
クラロワデータ分析_No.3_機械学習(クラスタリング)

お久ぶりです。takeshiです。
前回はクラロワで使用される全109枚のカードの性能の一部を可視化していきましたが、今回は機械学習による分析を行っていきたいと思います。
本記事では機械学習についての説明に始まり、今回分析に用いる具体的な分析手法につての解説を行ったのち、分析結果とその考察を記述していきます。
実はこの記事を作成するにあたり、1度誤って「下書き保存」をせずにブラウザを閉じてしまったため、書いた内容がすべて消えてしまうハプニングが起きてしまいました。正直ショックでしたが、記録に残しておきたいため書くしかないと自分に訴えかけ、再度書き直しました笑
ボリュームが多いため、気になる点だけ読んで、その他は無視していただいても構いません。ただ、最後に「スキ」ボタンを押していただけると嬉しいです。
1. 背景
クラロワでは8枚のカードを使用して戦うゲームですが、カードの構成はデッキによって様々です。しかし、強いデッキの作成方法には共通点があります。それは、カードの役割に被りがないように構成されているということです。
一例としてこちらのデッキを見ていきましょう。

わかりやすく説明するために、昔からの大人気デッキ「2.6ホグ」を採用しました。このデッキではそれぞれのカードで次のような役割を担っています。(個人的な見解です。)
ホグライダー:攻め
マスケット銃士:ユニット処理
ファイアボール:複数のユニットの処理
アイスゴーレム:盾
スケルトン:受け
アイススピリット:時間稼ぎ
ローリングウッド:陸の小物処理
大砲:防衛
このように、「高回転でホグライダーを回す」コンセプトはありつつも、すべてのカードで役割が被らないように構成されています。
そこで、全カードを8種類のグループに分け、各グループから1つずつカードを選ぶとテンプレートのデッキがいくつか存在するのではないかと考えました。そして、もしそうであれば、自らデッキのコンセプトを決めた後、各グループから1つずつカードを選択し、自分に合ったデッキを作成することができるのではないかという思いに至ったのです。
AIによるデッキ作成についても考えていますが、それは今後行っていく予定です。今回は機械学習によりカードを分類し、上記の考えの検証を行っていきます。
2. 結果
グループ分けを行った結果は次のようになりました。(詳しい説明はのちに行います。)

こちらが精度評価になります。

今回はカードを8種類に分けることを目的としていたため、8種類に分けた際に精度がよくなるモデルを作成しました。
結論からいうと、グループ分けは数字上だけでみると納得のいく結果を得ることができましたが、各グループから1枚ずつ選んで「テンプレデッキ」を作成することはできませんでした。
とはいえ、ここまできれいにグループ化できていれば、もしかしたらこのクラスタリングの結果をもとに、未知なる最強デッキを作れるかもしれません。
3. 機械学習
3.1 機械学習とは
機械学習とは、大量のデータをもとに繰り返し学習を行うことでパターンやルールを見つけ出し自動にモデル構築を行うことを指します。
実は、よく耳にするAIと機械学習は同じものではなく、AIを構築するための支えとなる技術が機械学習となっています。イメージとしてはAIという技術の中に機械学習があるという考え方をしていただくとよいかと思います。
さらに機械学習の中には「教師あり学習」と「教師なし学習」の2種類があります。「教師あり学習」では、データに正解・不正解の情報を事前に付与した状態で学習を行っていきます。例としては、土地の価格予測が考えられます。この場合は実際の価格を正解データとし、土地の緯度・経度や平均気温などを用いて学習を行い、パターンやルールを見つけ出し、モデルを構築します。
それに対して「教師なし学習」ではデータに正解・不正解の情報がわからない状態で学習を行っていきます。「正解がないのに学習ってどういうこと?」と思われるかもしれませんので、ネット通販の顧客のグループ分けを例に説明していきます。
ネット通販の購買履歴には、購入日時や購入量など様々なデータが記録されています。それらのデータをもとに「1度に大量に購入する顧客」や「1週間に1度の頻度で購入する顧客」などのグループ分けを行うことで、それぞれの顧客に合った施策案を立案したいとします。このグループの分け方には正解はありません。その状況で、数学的に類似度の計算などを行いグループ分けをするときに行う学習が、まさに「教師なし学習」の手法の1つなのです。
今回はカードを8種類に分けることを目的としていますが、それに正解・不正解はありません。そのため、「教師なし学習」を行うことになるのです。
3.2 階層クラスタリングとは
一口に「教師なし学習」をするといっても、種類は様々です。しかし、すべてを説明するわけにはいきませんので、今回使用する手法に絞って説明します。
そこで、今回使用する手法はタイトルにある通り「階層クラスタリング」です。そもそもクラスタリングとは、収集したデータを分析し「クラスター」と呼ばれるグループに分ける手法のことを指します。
最近は新型コロナウイルスの影響で「クラスター」というワードはよく聞くかと思いますが、それと同じような意味で、集団を意味しています。
そのクラスタリングにもさらに「階層クラスタリング」と「非階層クラスタリング」の2種類があります。細かく説明すると長くなりますので、簡潔に説明すると、「階層クラスタリング」とは、収集したデータから性質が近い者同士でグループ化していくことで、クラスター数を少なくしながら最適なグループ分けを行う手法のことを指します。
「階層クラスタリングでは」どのようにグループ化されていったのかを視覚的に把握しやすく、単純なデータに対しては有効な手法となっています。
対して、「非階層クラスタリング」とは初めにクラスター数を決定してから自動的にグループ化を行う手法のことを言います。こちらは「階層クラスタリング」とは反対に、グループ化の過程を把握しずらいが、大規模のデータでも信頼性の高い結果を得られるという特徴があります。
今回は、分類するカードの数が108枚と小規模のため、階層クラスタリングを採用しました。
4. モデリング
作業手順
今回のモデリングでは下記の手順を繰り返し行い、実行しました。
特徴量作成
正規化
主成分分析
モデリング
精度評価
1. の特徴量とは簡単に説明すると、攻撃力やヒットポイントといったカードの持つ能力を数値化した情報のことを指します。本来ならばもっとぐらい敵に説明すべきかと思いますが、クラロワのプレイヤー層を把握することが難しく、詳しく説明しすぎると読んでもらえないのではという不安もあるため省略します。
正規化、主成分分析については説明をすると、非常に長くなってしまうため割愛させていただきます。
気になる方は気軽に質問していただければ喜んでお答えします。
使用データ
今回の分析を行うにあたり、収集したデータに不備があり、また、フェニックスの緊急バランス調整があったためその修正を行いました。
それに伴い前処理をしたデータにも変更されたため、それらのデータを掲載します。
データ説明(前回と変更点なし)
収集したデータ
前処理済みデータ
また、学習を行うにあたり使用した特徴量(カードの情報)は下記の通りとなっています。
攻撃速度
建物への毎秒ダメージ
コスト
ヒットポイント
ユニットへの最大毎秒ダメージ
ユニットへの最小毎秒ダメージ
同時出撃数
射程
サブユニットの攻撃速度
タワーへのダメージ
タワーへの毎秒ダメージ
ユニットへのダメージ
ユニットへの毎秒ダメージ
ヒットポイントを加味した1コストあたりのユニットへのダメージ(前回の記事を参照)
1コストあたりのユニットへの毎秒ダメージ
1コストあたりのタワーへのダメージ
1コストあたりのヒットポイント
ユニットへのダメージ×射程
それらをまとめたデータがこちらとなります。
今回はこのデータを使用してクラスタリングを行いました。
特徴量
結果
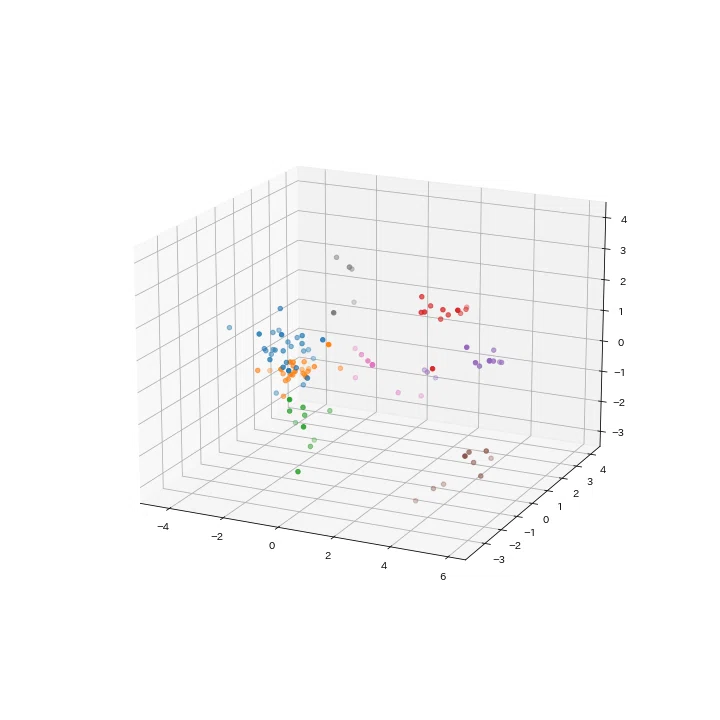
実際に階層クラスタリングを用いてグループ化した結果がこちらになります。

5. 精度評価

画像2の見方についてですが、こちらは最も似ていると判断したカード同士をつないでグループ化し、さらにそのグループと似ているカードや他のグループを結ぶという操作を表示したものとなっています。
縦線の長さは、長いほどカードの性能が似ていないことを意味し、短いほど似ていることを意味しています。
上記を踏まえて確認すると、8グループはそれぞれよく似ているカード同士でまとまっていることが確認できます。
また、画像2については専門知識を必要とするため、わからない方は無視していただいても大丈夫です。簡単に説明すると、攻撃速度やコストといった様々な特徴を「主成分分析」と呼ばれる手法を用いて集約し、その中で最もデータの特徴を表すことのできるもの3つを選び表示したものとなっています。
こちらは大学数学レベルの内容ですが、知りたい方がいればコメントお願いします。
最後に画像3についてですが、それぞれの指標の意味は次のようになっています。
シルエット係数:-1以上1以下の値をとる評価指数でクラスタ間の距離に比べクラスター内の距離がどれほど近いかを表す。(1に近いほどモデル性能が高いことを意味する)
Calinski Harabasz基準:クラスター内の距離の2乗の合計値に対するクラスター間の分散の割合を表す評価指標で適切なクラスター数がいくつであるのかを判断するために用いる(値が大きいほど適切なクラスター数であることを意味する)
Davies Bouldin基準:クラスター内の距離とクラスター間の距離の比に基づいて表される評価指標でクラスター間の距離が十分に離れているかどうかを表す(値が小さいほどクラスター間の距離が十分に離れていることを意味する)
上記を踏まえて各評価指標を確認すると、クラスター数8,9で各評価指標がどれもよくなっていることが確認できます。
6. 考察
8グループにはうまく分けることはできましたが、各グループからカードを選択し、テンプレデッキを作成することは難しいことがわかりました。
しかし、グループ分け自体は統計学的にはうまくできているため、もしかしたら新たな強いデッキを作れる可能性があるということも否定できません。
ちなみにこのクラスタリングの結果をもとに私が選んで作成してみたデッキがこちらになります。

実際に使用してみようと思いましたが、カードのレベルが低いためマルチでは検証にならず、無課金でプレイをしているため、グラチャレで試すこともできてはいません。
しかし、トリプルエリクサー大会にて使用してみたところ、3クラ勝利が続き高い勝率を得ることができました。私のスマホの調子が悪く後半は通信不良が続きその後の検証ができませんでしたが。デッキとしては成り立っていたように感じました。
ただし、マジックアーチャーに対しては処理が難しく、相性が悪いように感じました。
平均コストが3.6と使いやすいと感じる人も多いと思いますので是非使用してみてください。
また、ご自身でもクラスタリングの結果をもとに自作デッキを作成してみてください。
7. まとめ
グループ分け自体はうまくいきましたが、その結果をもとに、強いデッキを作成できるかどうかは判断できませんでした。そのため、さらに精度を高めるために、特徴量の選択の仕方を変えてみる必要もあるように感じました。
8. 今後について
これまで、データ収集と基礎集計を行い、今回は機械学習を進めていきましたが、少しずつクラロワのデータ分析でやってみたいことを終わってきています。
現段階でやってみたい内容の残りがこちらです。
AIによるデッキの自動生成
プロの大会向けのデュエルデッキ予想
選択したデッキを使いこなせるかどうかを数値化
プレイヤーの現環境への満足度・不満度などの数値化
このように、クラロワ関連でやりたいことは残り僅かになりました。そのため、もしこんなことをやってほしいということがあれば連絡していただければ幸いです。
しかしながら、実は私には将来プロ野球のデータアナリストになりたいという淡い夢があるため、今後はクラロワに縛られずプロ野球のデータ分析も行っていきたいと考えています。
今後方向性がどうなるかわかりませんが応援のほどよろしくお願いします!
データ説明(前回と変更点なし)
収集したデータ
前処理済みデータ
特徴量
この記事が気に入ったらサポートをしてみませんか?