
第291回: 「ALTAのテキストをつくろう」46 (エラー推測/前編)

◀前の記事へ 次の記事へ▶︎
≡ はじめに
前回は、「3. テスト技法」の「3.3 経験ベースのテスト技法」の導入部分について書きました。
「経験ベースのテスト技法の長所と短所」の話でしたが、シラバスの読み込みをしたというだけの回でした。
前回の復習は以下で模擬試験問題の確認を通して行います。
今回はJSTQBのALTAシラバスの「3.3 経験ベースのテスト技法」の「3.3.1 エラー推測」について書きます。
≡ 前回の復習
以下は前回出題したJSTQB ALTAの模擬試験問題を𝕏にポストした結果です。
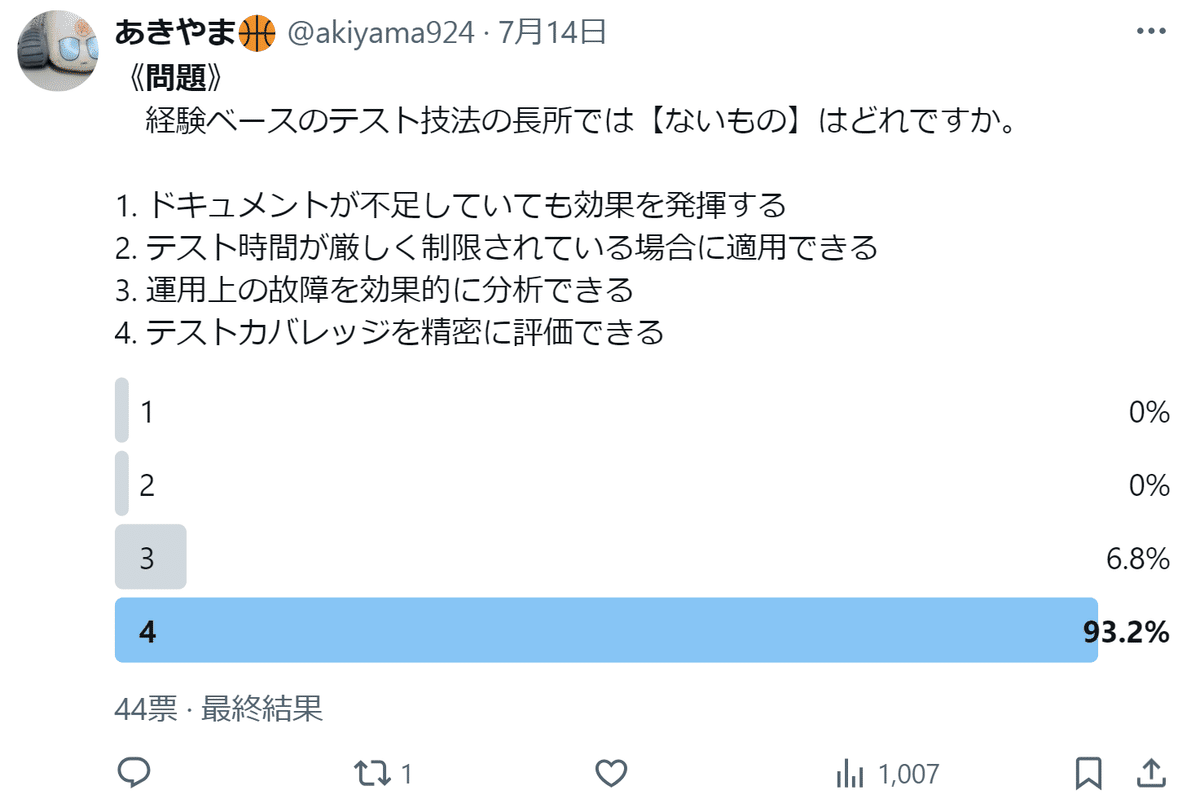
投票の結果、選択肢4の「テストカバレッジを精密に評価できる」が93.2%と最も多く、正解も4です。投票数は44票とまずまずで、正解率が高いので問題ないと思います。
「テストカバレッジを精密に評価できる」は、経験ベースのテスト技法の長所ではなく短所とISTQBのシラバスでは書かれています。
前回、シラバスより、下記の記載を転記しました。
「カバレッジについていくつかのアイデアを提示するが、経験ベースのテスト技法には、公式なカバレッジ基準が存在しないことに注意する必要がある。」
一つ気を付けてほしいのは、「テストカバレッジを精密に評価できる」でいう「テストカバレッジ」は例えばコードカバレッジではないという点です。
実際のところ、経験ベースのテストを実施しながらテスト対象のソフトウェアにコードカバレッジを計測する仕掛けをいれておいて測定するということは以前から実施されています。
ですから、例えば、探索的テストを1時間実施したタイミングで、ソースコードの網羅性を可視化したり、C0カバレッジやC1カバレッジといった網羅基準の網羅率を確認し、厳密に評価することは普通に、、、といっても、実施している組織は数パーセントかもしれませんが、、、行われています。
つまり、この問題の選択肢である「テストカバレッジを精密に評価できる」でいう「テストカバレッジ」は、例えば「探索的テストを実施した後にどれだけ網羅的に探索したかを精密に評価することは難しい」という意味です。
ある人の経験を網羅したことが、どれだけ一般的に網羅したことになるのかについて測るのは難しいですよね。
前回の復習は以上として、今回のnoteのテーマに移ります。
≡ エラー推測の定義
JSTQBのALTAシラバスのエラー推測の定義を引用します。
エラー推測技法を使用する場合、テストアナリストは経験を活かして、コードの設計および開発時に発生した可能性のある潜在的なエラーを推測する。
潜在的なエラーってなんだろう?「コードの設計および開発時」と、書いてあるから仕様書やコードに作り込んだ欠陥のことかな?
と思いませんか?
そこで、用語集も確認します。

英語では、
error guessing
A test technique in which tests are derived on the basis of the tester's knowledge of past failures, or general knowledge of failure modes
です。
今度は、「過去の故障の知識や故障モードの全般的な知識」と書いてあります。
『欠陥じゃなくて故障を推測するのかな?』と思いませんか??
そういうときには、FLのシラバスを読むと良いです。

推測するものは、「エラー、欠陥、故障の発生」とのことです。
「エラー推測は、間違った結果を生み出す人間の行為(エラー)を推測する」と間違えて覚えている人が多い気がします。
そうではなく、例えば過去に経験した不具合(故障)の知識を使って『このテスト対象で言えば、こういう不具合現象が起こりそうだ』と推測するのもエラー推測ですし、条件の実装漏れを推測してテストするのもエラー推測です。
≡ JSTQB ALTA試験対策
いつものことですが、まずは、「学習の目的」を確認します。
TA-3.3.1 (K2)経験ベースのテスト技法の原則と、ブラックボックステスト技法および欠陥ベースのテスト技法と比較した場合の長所と短所を説明する。
TA-3.3.2 (K3)与えられたシナリオから探索的テストを識別する。。
なぜ、TA-3.3.1 とTA-3.3.2 の二つを引用したかと言いますと、エラー推測に関するものがないからです。
「1. エラー推測は試験に出ない」、「2. 経験ベーステスト技法の原則のひとつとしてTA-3.3.1が適用されて、K2レベルの問題が出る」、「3. 探索的テストと同様に考えて、TA-3.3.2が適用されて、K3レベルの問題が出る」のどの解釈が正しいのでしょうか? (K2:理解、K3:適用、K4:分析)
わたしはK2レベルだと思います(K3レベルの問題は作りにくいから)。
《問題》
エラー推測が推測するのはどれでしょうか。
1. 間違った結果を生み出す人間の行為(error)
2. 作業成果物に存在する、要件または仕様を満たさない不備または欠点(defect)
3. コンポーネントやシステムが定義された範囲内で要求する機能を実行しないこと(failure)
4. 上記の全て
答えは次回に書きます。
≡ おわりに
今回は、「エラー推測の定義」がテーマでした。
実は、私自身、最近まで、「テストベースから開発者が間違えそうな箇所を推測して“その間違いをしたらこんな不具合現象が起きるはず”と考えてテストをしてみること」をエラー推測と呼ぶと誤解していました。
その方法自体が間違いということではなく、ISTQBのエラー推測の定義とは合っていないというだけですが、チームでテストをする以上、概念の統一は大切です。
さて、次回は、「3.3.1 エラー推測」の残りについて書きます。