スクレイピングで高校偏差値テーブルを作成する

高校の偏差値をリスト化し、高校名から特徴量を作りたかったときのメモです。
今回は、「みんなの高校情報」さんのサイトをスクレイピングして、高校名と偏差値の情報をCSVファイルで取り出す例を取り挙げます。

Pythonの実行環境はどこでも良いのですが、最もお手軽なのはGoogle Colabですね。社内のネットワーク制限がある場合は、anacondaがお手軽です。
ただし、プロジェクトとして分析を行うときは、dockerで分析環境をポータブルかつ再現可能な状態にしておくのがいいでしょう。
※環境周りの記事もどこかで書けたらと思っています。
スクレイピングを行う上での注意点
例えばTOP COURT INTERNATIONAL LAW FIRMさんによれば、スクレイピングをする際には、以下の3つの法律的問題をクリアする必要があります。
著作権法上の問題
利用規約との抵触
サーバーへの過度なアクセス
サイト中では、スクレイピングを行ったことで逮捕された事例も掲載されています。考慮が必要な点やリスクを十分に理解したうえで、自己責任においてスクレイピングを行うようにしましょう。
ライブラリのインポート
さて、jupyter notebookを立ち上げたら、ライブラリのインポートをします。今回は、pythonでスクレイピングを行う場合には王道のBeautifulSoupを利用します。
import numpy as np
import pandas as pd
from tqdm import tqdm
tqdm.pandas()
import requests
from bs4 import BeautifulSoup今回は、実行にそれなりの時間がかかるので、プログレスバーを表示するためのtqdmもインポートしておきます。
なお、tqdmもrequestsもBeautifulSoupも、pipで入ります。
$ pip install tqdm
$ pip install requests
$ pip install beautifulsoup4
ページの構造を理解する
こちらのサイトでは、高校の偏差値情報は以下のURLの形式で、末尾のpage=nを指定することで、nページ目にアクセスできるようです。
https://www.minkou.jp/hischool/ranking/deviation/page=n/次に、Google Chromeの検証機能を使って、どの要素に高校名と偏差値が入っているのかを確認します。

divタグの"mod-listRanking-name"クラスに高校名が入っていることが分かりました。ただし、所在地や私立/公立の区分も同じ要素に入っていますね。続いて偏差値です。
![]()
こちらはddタグの"info-main"クラスに入っていました。
必要箇所の抽出を行う:偏差値
まずは易しそうな偏差値のほうから。
1ページ目にアクセスして、欲しいデータが含まれる要素をすべて抜き出してみます。ついでにtqdmの動きも確認しておきたいので、for文で回しておきましょう。
# 1ページ目にアクセスし情報を取得
for pageno in tqdm(range(1, 2)):
url = 'https://www.minkou.jp/hischool/ranking/deviation/page=' + str(pageno) +'/'
html = requests.get(url)
# パース用オブジェクト作成
soup = BeautifulSoup(html.text,"html.parser")
# 偏差値を含む要素の抽出
devi = soup.find_all("dd", class_="info-main")
print(devi)
プログレスバーはきちんと表示されています。偏差値部分は、タグ以外の部分を抜き出せば、うまく必要な部分だけを取り出せそうです。よって、こうすれば良さそうです。
# 偏差値を含む要素の抽出
devi = soup.find_all("dd", class_="info-main")
# 必要箇所の抽出
devi_list = [int(d.text) for d in devi]パースしたbs4.element.ResultSet型のオブジェクトから、それぞれの要素の偏差値部分だけをtextメソッドで抜き出し、それをint型に変換してlistに入れていきます。
必要箇所の抽出を行う:高校名
さて、次は高校名です。
# 1ページ目にアクセスし情報を取得
for pageno in tqdm(range(1, 2)):
url = 'https://www.minkou.jp/hischool/ranking/deviation/page=' + str(pageno) +'/'
html = requests.get(url)
# パース用オブジェクト作成
soup = BeautifulSoup(html.text,"html.parser")
# 偏差値を含む要素の抽出
devi = soup.find_all("dd", class_="info-main")
print(devi)

このままだとtextメソッドの戻りに所在地や私立/公立の区分も入ってしまうので、タグの切り分けをしたほうが良さそうです。contentsメソッドを利用すると、タグごとに分割できます。
print([h.contents for h in hsname])![]()
2番目の要素にaタグが入っているlist × 20校分のlist が取得できました。よって、こうすれば良さそうです。
# 学校名を含む要素の抽出
hsname = soup.find_all("div", class_="mod-listRanking-name")
# 必要箇所の抽出
hsname_list = [h.contents[1].text for h in hsname]
パースしたbs4.element.ResultSet型のオブジェクトをタグ毎に分割し、その2番目の要素のうち高校名部分だけをtextメソッドで抜き出し、それをlistに入れていきます。
コードまとめ & pandas.DataFrameに成形する
上記のコードをまとめるとこんな感じです。
すべてのページにアクセスして要素を取得し、出力結果をDataFrame化するようにしました。
df = pd.DataFrame() #空のDataFrameを作成
#すべてのページにアクセスし情報を取得
for pageno in tqdm(range(1, 504)):
url = 'https://www.minkou.jp/hischool/ranking/deviation/page=' + str(pageno) +'/'
html = requests.get(url)
# パース用オブジェクト作成
soup = BeautifulSoup(html.text,"html.parser")
# 偏差値を含む要素の抽出
devi = soup.find_all("dd", class_="info-main")
# 学校名を含む要素の抽出
hsname = soup.find_all("div", class_="mod-listRanking-name")
# 必要箇所の抽出
devi_list = [int(d.text) for d in devi]
hsname_list = [h.contents[1].text for h in hsname]
# DataFrame化して結合
df = pd.concat([df, pd.DataFrame({'hsname' : hsname_list, 'devi': devi_list})])うまく取得できました。基本統計量を見ておきましょうか。
df.describe()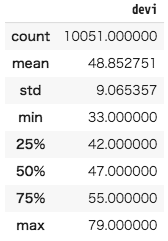
CSVにするなら…
df.to_csv('devi_hs.csv', encoding='cp932')encodingはお好みで。
私はexcelで開きたいケースが多いのでcp932にしておきました。
引き続き、もう少しテクニカルな記事も書いていけたらと思います。