
Deep Research爆誕!AIがネットを深掘りして知識を構築する時代へ

O1とO3のメイン開発者であるMark Chen氏が、東京からお届けする「Deep Research」の紹介ライブが本日日本時間午前9時にありました。彼らは東京でソフトバンクの孫正義氏とのイベントに参加するため滞在しています。後ろの棚に日本の正月飾りが飾ってあり、日本にいることがわかりますね。
また、本日、OpenAIのCEOであるサム・アルトマン氏は、日本の石破首相との会談を予定しており、AIの未来に関する議論が行われるとみられています。
それでは下記の動画を解説していきます。
Deep Researchとは?
2025年2月3日に発表された「Introduction to Deep Research」の前半で、OpenAIの研究開発者であるMark ChenがDeep Researchについて解説しました。本記事では、動画の内容をセクションごとに分け、見出しを立てながら紹介します。
1. OpenAIの新たな研究ツール「Deep Research」
Mark Chenによると、Deep Researchはインターネットを活用したマルチステップの調査を行う新しいAIエージェントです。従来のモデルと異なり、長時間かけて情報を探索し、内容を統合し、推論を行いながら回答を生成することが特徴です。
通常のAIモデルはすぐに回答を出しますが、Deep Researchは5分から最大30分ほどかけて詳細な分析を行います。これにより、より高品質なアウトプットが得られるとされています。
2. なぜDeep Researchが必要なのか?
OpenAIは、AIエージェントが知識労働を変革すると考えています。従来のAIモデルは推論能力に優れていても、リアルタイムで新しい情報を取得することは困難でした。
Deep Researchはこの課題を解決するために開発され、最新の情報を収集・統合しながら、論理的なレポートを作成する能力を持ちます。これにより、ビジネス、学術研究、個人的な情報収集など、多様な用途に活用できます。
3. Deep Researchの主要機能
Deep Researchの主な機能は以下の通りです。
マルチステップのインターネット調査: 必要な情報を複数のソースから取得し、統合する。
推論と適応的計画: 取得した情報を分析し、検索プロセスを動的に調整。
包括的なレポート作成: 専門家レベルの詳細なレポートを作成し、情報源を明示。
長時間のタスク処理: 短時間の処理に制限されず、より複雑なリサーチを可能にする。
4. 具体的なユースケース
Deep Researchの活用例として、以下のようなシナリオが挙げられています。
市場調査: 競合分析や最新トレンドの調査。
学術研究: 論文やデータの収集と整理。
製品比較: 例として「最適なスキー板の選び方」の調査。
投資分析: 新しい投資機会のレポート作成。
5. Deep Researchのローンチスケジュール
Deep Researchは、まずProユーザー向けに公開され、その後Plus、Team、Education、Enterprise向けに順次展開される予定です。
この新しいツールは、AGI(汎用人工知能)へのロードマップの一環とされており、OpenAIの次世代技術への大きな一歩となります。
今後の展開が楽しみですね!
Deep Researchの仕様とベンチマーク
ライブの後半では、Deep Reserchの優れた機能とスペックを同席している三人の開発者が変わるがわる解説していきました。
Humanity's Last Exam(人類最後の試験)
Deep Reserchは「Humanity's Last Exam」(注01)で非常に高いスコアを出しています。Humanity's Last Examは、人類最後の試験と呼ばれており、AIの能力を評価するために開発された、これまでで最も難しいベンチマークテストです。このテストは、AIモデルが専門家レベルの知識と推論能力を持っているかを測定することを目的としています。

OpenAI Deep Research pass@1 はこのテストで26.6%という最も高い精度をだしています。ブラウジング機能とPythonツールを活用することで、従来のLLMよりもはるかに高精度な回答を生成できるのです。
この結果からわかるのは、Deep Researchの「情報収集+推論力」が通常のLLMではなく、外部の検索機能やPythonツールを組み合わせることで、より正確な回答を提供できる未来が見えてきたという事です。
AIの汎用性を測るGAIAテスト
下記のGAIAテスト(注02)の結果が表しているのは、
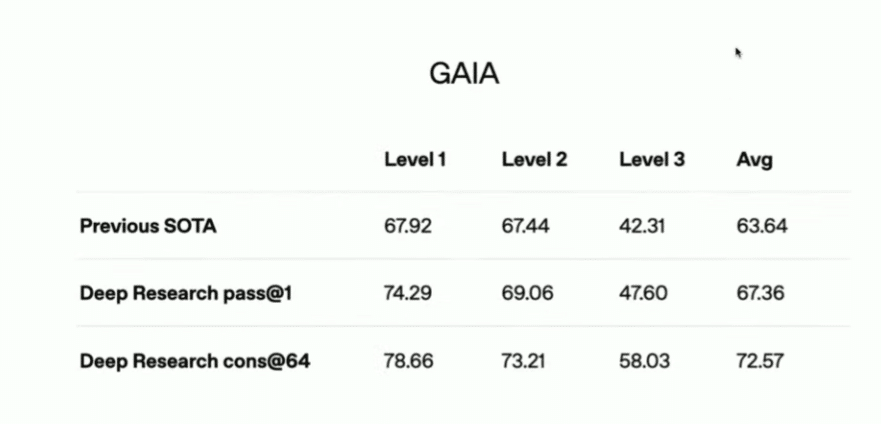
人間の正答率:92%に対して、
従来のSOTA AI(State of the Art):63.64%
Deep Research pass@1:67.36%
Deep Research cons@64:72.57%
です。まだ人間(92%)には及ばないが、AIが「考える時間を増やす」ことで、さらに差を縮める可能性があります。従来のLLM(大規模言語モデル)は、「1回の試行で即答する」ことが求められていたため、推論を深める時間がほとんありませんでした。
Deep Researchは「時間をかけて考える」ことを重視する設計になっており、推論・検索・計算のプロセスを活用することで、より高精度な解答を導き出しています。今後、さらなる最適化が進めば、GAIAテストにおいて人間を超える日も遠くないと見られています。
タスクの経済的価値と費用対効果
このグラフは、Deep Researchの「専門レベルのタスク(Expert-Level Tasks)」における合格率(Pass Rate)を、経済価値(Economic Value)と作業時間(Estimated Hours)の観点から分析したものです。

このグラフは、Deep Researchが「リサーチアシスタント」としてどこまで実用的かを示す興味深い指標になっています。
現状では「単純で短時間のタスク」が得意だけど、「高価値で長時間のタスク」への対応力を強化すれば、今後の活用範囲がさらに広がる可能性があります。では左右のグラフの結果を見ていきましょう。
左のグラフ:「経済価値別の合格率」
(Pass Rate on Expert-Level Tasks by Estimated Economic Value)
これは、「タスクの経済的価値」が高いほどAIがどれくらい正確にタスクをこなせるかを示している。
経済価値が低いタスク(Low):合格率 19%
→ 比較的単純なタスクは、高い確率でクリアできる。経済価値が中程度(Medium):合格率 17%
→ 若干難しくなっても、それなりの精度を維持。経済価値が高い(High):合格率 15%
→ 難易度が上がるにつれ、合格率が少し下がる。経済価値が非常に高い(Very High):合格率 9%
→ 最も価値の高いタスク(=おそらく専門的な判断や戦略的思考が必要なもの)では、AIのパフォーマンスが大きく低下。
右のグラフ:「作業時間別の合格率」
(Pass Rate on Expert-Level Tasks by Estimated Hours)
これは、「タスクの所要時間」がAIの合格率にどのような影響を与えるかを示している。
1〜3時間のタスク:合格率 22%
→ 短時間で済むタスクのほうが、AIは高い確率で成功する。4〜6時間のタスク:合格率 13%
→ タスクが長くなると、合格率が低下。7〜9時間のタスク:合格率 14%
→ 4〜6時間よりは若干回復するが、1〜3時間のタスクには及ばない。10時間以上のタスク:合格率 15%
→ 長時間のタスクでも少し回復するが、それほど大きな改善は見られない。
専門レベルのタスク(Expert-Level Task)の合格率
この折線グラフは、「専門レベルのタスク(Expert-Level Task)の合格率(Pass Rate)」と「最大ツール呼び出し回数(Max Tool Calls)」の関係を示しています。

「Deep Researchがどの程度ツールを活用することで成績を向上できるか」を示しており、特に、ツールの呼び出し回数を40〜60回程度に設定すると、最も効果的であることが分かります。
無制限にツールを使うのではなく、効率的に活用することでより高度なタスクをこなせるAIへと進化しているのがポイントです。
こんな感じでグラフを見ます。
X軸(横軸):最大ツール呼び出し回数(Max Tool Calls)
→ AIが外部ツール(検索、計算、データベース参照など)を使用できる回数の上限。Y軸(縦軸):タスクの合格率(Pass Rate)
→ AIが専門レベルのタスクを正しく完了できた確率。折線の傾向:
ツールの呼び出し回数が増えるほど、合格率も上昇している。
特に0〜40回の範囲で急激に合格率が向上している。
60回を超えると伸びが緩やかになり、100回あたりでほぼ頭打ちになっている。
※注01:「Humanity's Last Exam(人類最後の試験)」は、AIの能力を評価するために開発された、これまでで最も難しいベンチマークテストです。このテストは、AIモデルが専門家レベルの知識と推論能力を持っているかを測定することを目的としています。
従来のベンチマークテストでは、AIモデルが高得点を達成するようになり、AIの真の能力を評価することが難しくなってきました。この問題を解決するため、Center for AI Safety(CAIS)とScale AIが協力し、世界中の専門家から最も難解な質問を集めて「Humanity's Last Exam」を作成しました。
このベンチマークは、数学、人文科学、自然科学など、幅広い分野からの3,000問の問題で構成されています。各問題は、大学教授や研究者などの専門家によって提供され、AIモデルの知識と推論能力を厳しく評価します。
※注02:GAIA(General AI Assistantsの略)は、Meta社やHugging Face社の研究者たちによって開発された、汎用AIアシスタントの能力を評価するためのベンチマークです。このベンチマークは、AIシステムが現実世界のタスクをどの程度効果的にこなせるかを測定することを目的としています。
GAIAの特徴
多様な質問構成:GAIAは、466の質問から構成されており、これらの質問は人間にとっては概念的に単純ですが、AIにとっては挑戦的なものとなっています。
人間とAIの性能差:GAIAのテストでは、人間の正答率が92%であるのに対し、GPT-4のような高度なAIモデルでも正答率は15%にとどまっています。
評価の目的:GAIAは、AIシステムが日常的なタスクや現実世界の問題にどの程度適応できるかを評価することで、AI研究の新たなマイルストーンを設定することを目指しています。
GAIAは、AIの能力をより包括的に評価するための新しい基準を提供し、今後のAI開発や研究において重要な役割を果たすと期待されています。