
【実装付きAI論文解説】PatchTST: A TIME SERIES IS WORTH 64 WORDS:LONG-TERM FORECASTING WITH TRANSFORMERS|TECH BLOG #03

1. はじめに
はじめまして、AIVALIX株式会社 Chief AI Engineer を務めております、大木基嗣です。(X: @A7_data)会社ではこれまで、RAG関係の論文のR&Dを主に担当し、現在は時系列モデルを用いたアパレルの需要予測モデルの開発に取り組んでいます。研究ではGNN(グラフニューラルネットワーク)を用いた都市の水道管ネットワークの保全モデルの開発を行なっています。
さて、弊社ではAIエンジニアによるテックブログの発信に力を入れております。このテックブログでは、最新のAI論文について実装付きで分かりやすく解説することを目的としています。少しでも多くの方にAIの技術や可能性を感じていただければ幸いです。
今回は、テックブログ第3回として、ICLR 2023にも採択された、多変量時系列データの長期予測を高精度に行うためのTransformer系モデル「PatchTST」について解説と実装をまとめました。ぜひ最後までお読みいただけると嬉しいです。また、フォローしていただけますと今後の発信の励みになります。よろしくお願いいたします。
2. PatchTST論文解説
2-1. 前提・概要
時系列データは、時間の経過とともに記録された一連のデータポイントで、時間軸に沿って変化するパターンや傾向を分析できる情報の集合です。つまり、日常生活やビジネス上のデータの多くは時系列データであり、その予測モデルは多くの研究が進んでいます。
深層学習系のモデルでは、有名な論文「Attention Is All You Need」で発表されたTransformer系のモデルが大きな成功を収め、従来モデルよりも大幅な精度向上を達成しています。
時系列データ予測においてもTransformerの応用モデルが提案されてきましたが、様々な一般的なベンチマークで非常に単純な線形モデルがそれらを上回ることが示されており、Transformerの時系列データへの応用には課題が残っています。
PatchTSTでは、パッチングとチャネル独立性の二つを工夫として取り込むことで、従来モデルと比べて精度・計算効率を大幅に向上できるとしています。さらに、自己教師あり事前学習と転移学習によって、限られたデータセットでも高い予測精度を実現できることがこのモデルの強みです。
2-2. 手法
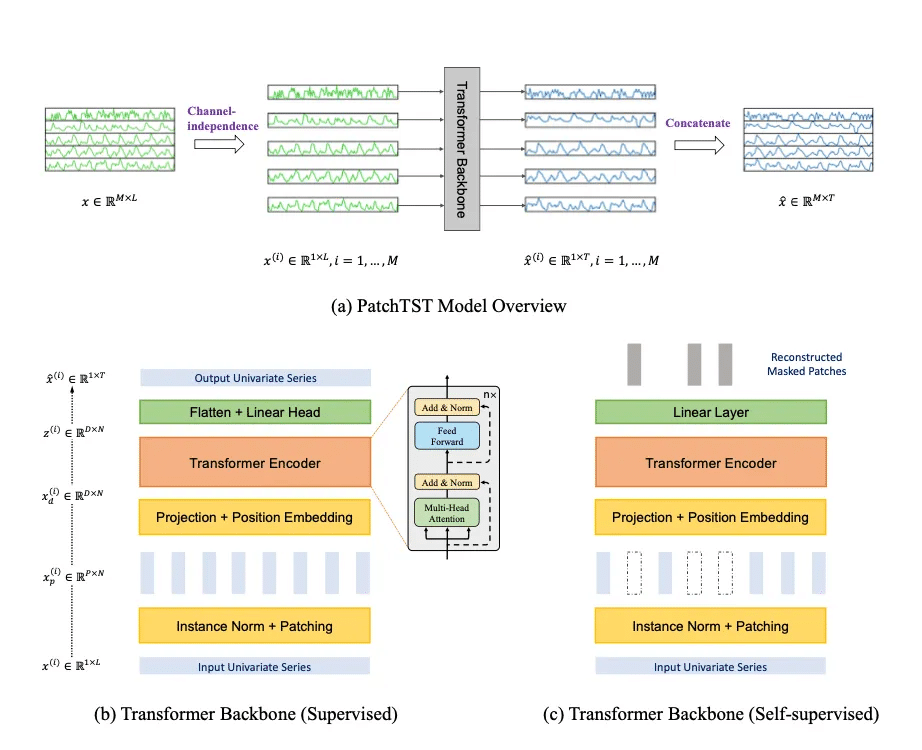
PatchTSTは一言で説明するなら「多変量時系列データをそれぞれ独立に扱い、さらにそれぞれの時系列データを一定期間ごとに分割(一つ一つを『パッチ』という)し、Transformerに入力することで計算効率・精度の向上をしたモデル」です。
問題設定
この論文での問題設定は以下の通りです。
『ルックバックウィンドウLを持つ多変量時系列サンプルの集合が与えられた時、(x_1, …, x_L)(x_tは時間tにおける次元Mのベクトル)からT個の将来の値(x_L+1, … , x_L+T)を予測する。』
つまり、複数種類のL個の過去の時系列データをもとに学習し、目的の変数をTステップ分予測する、ということになります。
ここからはパッチングとチャネル独立性について扱いますが、上のモデルの図を見ながら読むとわかりやすいと思います。
チャネル独立性
多変量時系列は、M種類の単変量時系列が組み合わさったもので、モデルへの入力(ここではTransformer)は、単一チャネルもしくは複数チャネルのデータで表すことができます。
PatchTSTでは、各入力トークンが単一チャネルからの情報のみを含むようにします。これは、CNNや線形モデルではうまく機能することが証明されていましたが、Transformerへの適用はされていませんでした。
パッチング
入力の時系列をいくつかのまとまりごとに分割することを「パッチング」と言います。PatchTSTでは、多変量時系列データを入力としますが、その一つ一つの単変量時系列x(i)(i=1, …, M)を、パッチに分割して入力するのです。
この入力の分割によって、入力トークンの数をLから約L/Sまで減らすことができます。(Sはストライドで、2つの連続するパッチ間の非重複領域)Attentionは入力トークンの二乗のオーダーで計算量が増加するため、Sの係数によって二次的に計算量を減少させられます。
パッチングを行った後は、Transformerエンコーダに入力し、潜在表現にマッピングします。それぞれの入力が次元DのTransformer潜在空間にマッピングされ、Transformerによって処理されます。
Transformerエンコーダの細かい部分は通常のTransformerと基本的には同じなのでここでは省略します。
表現学習
PatchTSTは、自己教師あり学習によって、事前学習が可能です。その後、手元にあるデータでファインチューニングをすることで、高い精度での予測を実現できる、とされています。
今回の実装では事前学習は関係ないため、省略します。
2-3. 結果
長期予測性能

比較対象のモデル
DLinear:時系列データのトレンドと季節性を分解し、線形モデルを適用する手法。計算コストを抑えつつ、長期的な依存関係を効果的に捉えることができる。
FEDformer:時系列データをトレンド成分と季節成分に分解し、季節成分にフーリエ変換を用いて周波数領域でのアテンションを行うモデル。長期的な時系列予測の精度向上を実現。
Autoformer:時系列データのトレンドと季節性を自己相関メカニズムを用いて分解し、それぞれに適した予測を行うモデル。長期的な依存関係を効果的に捉え、高精度な予測を実現。
Informer:長期の時系列予測に特化したTransformerベースのモデルで、ProbSparse Self-attentionやSelf-attention Distillingなどの手法により計算効率を向上。長期的な依存関係を効率的に捉える。
Pyraformer:階層的なピラミッド型アテンション機構を持つモデルで、異なる時間スケールでの依存関係を効果的に捉えることが可能。
LogTrans:ログスパースマスクを用いたスパースアテンション機構を持つモデルで、計算コストを削減しつつ、高精度な時系列予測を実現。
多くのデータセットにおいて、PatchTSTが他のモデルと比較して良好な結果が得られていることがわかります。(PatchTST/64は入力パッチ数が64を意味する。ルックバックウィンドウは512。)
PatchTST/64で、MSEは全体的に21%の削減、MAEでは16.7%の削減を達成しています。
Ablation Study
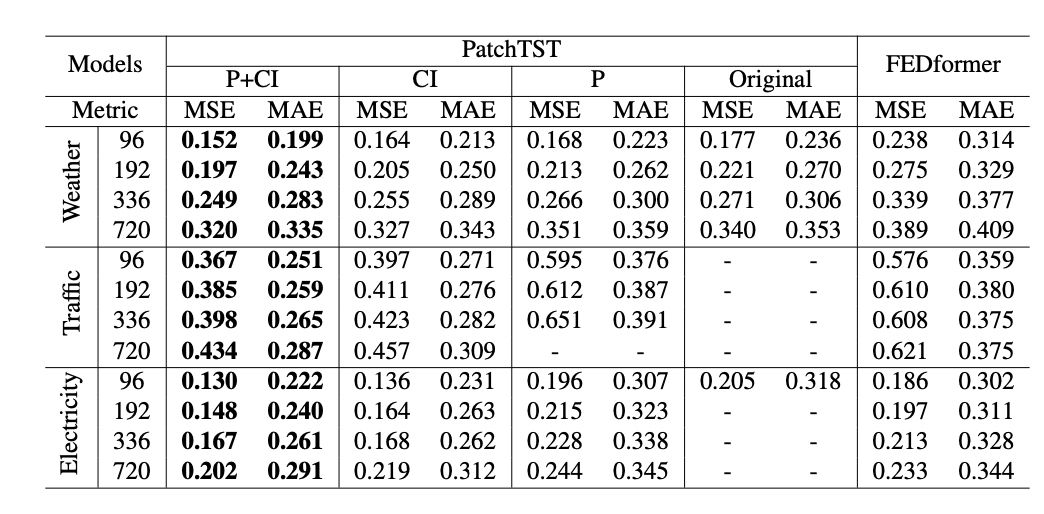
パッチング(P)とチャネル独立(CI)のアブレーションスタディです。
やはり、この両方が予測性能の向上に重要な要素であることがわかります。「-」となっているのは、バッチサイズが1でもGPUメモリ(NVIDIA A40 48GB)を使い果たし、学習ができないということです。
パッチングを入れることでメモリ効率を向上できていることが読み取れます。
ルックバックウィンドウ

直感的には、ルックバックウィンドウを長くするほど予測性能が向上しそうですが、多くのTransformerモデルはそうではありません。つまり、長いルックバックウィンドウのデータを活かせていないのです。
しかしながら、PatchTSTについてはルックバックウィンドウが長くなるほど精度が向上していることがわかります。この結果に基づき、PatchTSTは長いルックバックウィンドウから学習できる能力があると主張されています。
2-4. 結論
PatchTSTはパッチングとチャネル独立という二つのコンポーネントを導入することで予測精度向上・計算効率向上を実現した、時系列予測タスクのためのTransformerベースモデルです。パッチングはシンプルで他のモデルにも転用可能ですし、チャネル独立もチャネル間の相関を組み込むためにさらに活用することが可能です。それらが今後のステップとして紹介されていました。
3. NeuralForecastによる簡易版実装
実はNeuralForecastというライブラリを使うことによって、PatchTSTはものすごく簡単に実装できてしまいます。
NeuralForecastは深層学習系の時系列モデルを簡単に実装できるようにしたライブラリであり、Transformer系モデルのPatchTST、iTransformerやAutoFormerの他にもRNN系のLSTMやDeepAR、MLP系のNBEATS等にも同様に対応しています。
さらに変更できるパラメータもちゃんと整備されており、細かいチューニングの前にひとまず試す段階ではとても重宝するツールだと思います。
(scikit-learnの時系列深層学習版、がしっくりくる表現でしょうか。)
3-1. 実装コード
今回はYahooのyfinance APIを使って、Apple社の株価予測を行います。データ期間は2023年1月1日〜2024年12月1日とし、2024年12月1日から31日までの株価を予測することにしました。
株価取得&データ整形コード
まずはyfinanceライブラリをインストールします。
pip install yfinance以下で株価を取得し、学習できるように整形します。
neuralforecastライブラリでは「unique_id」という列が必要なので追加しています。
import yfinance as yf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# yfinanceを使用してデータを取得
def prepare_stock_data(ticker, start_date, end_date):
"""
株価データを取得する関数
Parameters:
ticker (str): 銘柄コード(例: "AAPL")
start_date (str): データ取得の開始日(例: "2020-01-01")
end_date (str): データ取得の終了日(例: "2023-12-31")
Returns:
pd.DataFrame: 日付と終値を持つデータフレーム
"""
data = yf.download(ticker, start=start_date, end=end_date, interval="1d")
close_prices = data['Close'] # 終値を抽出
close_prices = close_prices.reset_index()
close_prices.rename(columns={'Date': 'ds', f"{ticker}": 'y'}, inplace=True)
close_prices['unique_id'] = 1.0 # NeuralForecastの入力データにはunique_idが必要
return close_prices
# データ取得
stock_data = prepare_stock_data("AAPL", "2023-01-01", "2024-12-31")
# 学習データとテストデータに分割
train_data = stock_data[stock_data['ds'] < '2024-12-01']
test_data = stock_data[stock_data['ds'] >= '2024-12-01']学習
from neuralforecast import NeuralForecast
from neuralforecast.models import PatchTST
# パッチサイズとストライドの設定
horizon = 30
input_size = horizon * 2
# モデルのパラメータ設定
model = PatchTST(
input_size=input_size,
h=horizon,
)
# NeuralForecastオブジェクトの作成
nf = NeuralForecast(
models=[model],
freq="D"
)
# 学習
nf.fit(df=train_data)モデルに指定できるパラメータは多数ありますが、このコードのように少ないパラメータだけでも実行が可能です。今回は予測日数を30日、入力日数を60日としています。
パッチングやチャネル独立等の処理は自動で行われます。もちろん、パラメータを指定してストライドのサイズなどを指定することも可能です。
予測・評価
import matplotlib.pyplot as plt
from sklearn.metrics import mean_absolute_error, mean_absolute_percentage_error, r2_score
import pandas as pd
# 予測
pred_df = nf.predict().reset_index()
pred_df = test_data.merge(pred_df, how='left', on=['unique_id', 'ds'])
# プロット
plot_df = pd.concat([train_data, pred_df]).set_index('ds')
fig, ax = plt.subplots()
plot_df[['y', 'PatchTST']].plot(ax=ax, linewidth=2)
# 予測精度評価関数
def calculate_performance_metrics(y_true, y_pred):
return {
'MAE': mean_absolute_error(y_true, y_pred),
'MAPE': mean_absolute_percentage_error(y_true, y_pred),
'R2 Score': r2_score(y_true, y_pred)
}
y_true = test_data['y']
y_pred = pred_df['PatchTST']
metrics = calculate_performance_metrics(y_true, y_pred)
print(f"Model: PatchTST")
print(f"MAE: {metrics['MAE']}")
print(f"MAPE: {metrics['MAPE']}")
print("\n")結果は、以下のようになりました。

MAE: 8.514730834960938
MAPE: 0.03453684222907062他のモデルとも比較をしてみます。NHITSとNBEATSを比較対象にし、同様のコードにて精度比較をしてみます。結果は以下の通りでした。
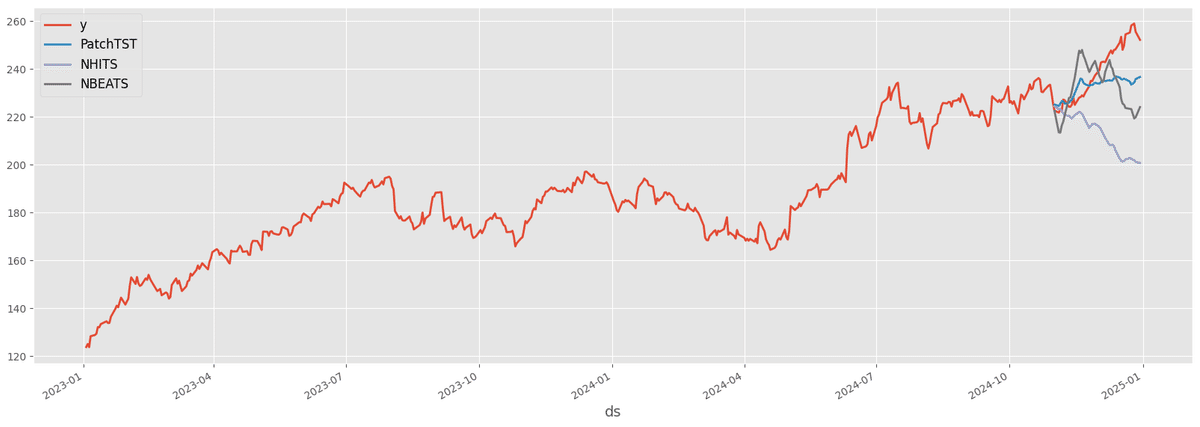
Model: PatchTST
MAE: 8.514730834960938
MAPE: 0.03453684222907062
Model: NHITS
MAE: 25.393868255615235
MAPE: 0.10272022583712573
Model: NBEATS
MAE: 13.55612907409668
MAPE: 0.05561482967296246PatchTSTのMAEが一番良くなっています。ここはパラメータを変更すると順位も変動したので、データの適切な前処理や、タスクに最適なモデルの探索などは必要になりそうです。
PatchTST以外のTransformer系のモデルであるInformerやAutoformerでも精度検証を試みましたが、いずれも計算時間が長くなるため、GPUが必要であるというエラーが出てしまい、実行できませんでした。
PatchTSTはパッチングにより計算効率を向上させられているのでそのような心配はなく、簡単に実行することができました。この点もPatchTSTの大きなメリットの一つでしょう。
4. さいごに
今回のテックブログは以上になります。最後までお読みいただき、ありがとうございました。この記事が、少しでも皆様の参考になり、新たな気づきや挑戦のきっかけとなれば幸いです。今後も引き続き、有益な情報をお届けしてまいりますので、どうぞご期待ください。
AIVALIX株式会社では、AIに関する開発やR&Dの案件を常時承っております。また、共同開発・共同研究にご協力いただける企業様も広く募集しております。
AI技術を通じた新たな価値創造に向け、一緒に挑戦していただけるパートナーを心よりお待ちしております。ご興味をお持ちの際は、ぜひお気軽にお問い合わせください。
▼ コーポレートサイトはこちら ▼
本記事の著者(大木基嗣 / A7|データサイエンティスト界の大谷翔平になりたい大学院生)もXやNoteで情報発信をしておりますので、そちらも見ていただけると幸いです。