
【実装付きAI論文解説】Cache-Augmented Generation is All You Need for Knowledge Tasks|TECH BLOG #05

1. はじめに
はじめまして。AIVALIX株式会社でAIエンジニアを務めております、安孫子リクです。現在、東京大学理科一類に在学しており、大学入学後から東大AI研究会に所属し、AI技術の学習・研究を続けてきました。AIVALIXでは、LLM・RAGの最新論文をもとにしたR&Dに取り組んでおり、現在はAIチャットサービスの回答精度向上を目的としたプロジェクトに従事しています。
弊社では、AIエンジニアによるテックブログの発信に力を入れており、最新のAI論文を実装例とともに分かりやすく解説することを目指しています。AIの技術や可能性を多くの方に届けるため、こうした情報を継続的に発信し、学習や研究の一助となればと考えています。
さて、第5回となる今回のテックブログでは、「Cache-Augmented Generation is All You Need for Knowledge Tasks」 という論文をご紹介します。
近年の大規模言語モデル(LLM)は、膨大なインターネット上の情報を学習し、一般的な知識を持つようになっています。しかし、企業の内部文書や独自データ、最新の研究成果など、公開されていない情報にはアクセスできません。この課題を解決するために、「Retrieval-Augmented Generation(RAG)」という手法が広く活用されています。
RAGは、事前に用意したデータベースから関連する文書を検索し、それをLLMのプロンプトに追加することで、独自データを活用した回答を生成する仕組みです。しかし、この手法にはいくつかの課題があります。
遅延の問題
質問ごとに関連文書を検索するため、検索処理がボトルネックとなり、応答時間が増加する可能性がある。
ドキュメント選択の誤り
検索アルゴリズムの精度によっては、適切な文書が選ばれず、最適な回答が得られないリスクがある。
システムの複雑化
検索エンジンやアルゴリズムの管理が必要となり、システム全体の保守性や運用負担が増す。
本論文では、こうしたRAGの課題を解決するために、LLMが長いコンテキストを処理できるようになった技術的進展を活かし、新たな手法を提案しています。具体的には、関連ドキュメント全体を事前にキャッシュとしてロードし、質問のたびに検索するのではなく、直接コンテキストとして活用する方法が検討されています。これにより、検索遅延の削減、ドキュメント選択ミスの防止、システムのシンプル化を実現できる可能性があります。
今回のブログでは、この論文の手法について詳細に解説し、従来のRAGと比較しながら、その実用性について考察していきます。最新のLLM技術の進化と、その活用方法を知る一助となれば幸いです。
それでは、詳しく見ていきましょう。
2. 論文解説
今回扱う論文は以下のリンクから閲覧できます。
2-1. Methods
単純にドキュメントを質問の前に文字のまま付け加えると、LLMの処理にかかる時間がとても長くなってしまうので、key value cacheというドキュメントの情報がすでに処理されて圧縮された数字のベクトルをあらかじめ生成しておき、これらを質問の前にコンテクストとして付加することで、生成速度を速めています。
実験に使ったアーキテクチャはシンプルで、
1. 参照用ドキュメントのkey value cacheを生成し、パソコンに保存する
2. key value cacheと質問をLLMに読み込ませ、回答を生成する
3. 生成された回答と正解を別のモデルに読み込み、類似度を判定する
これによるスコアと従来のRAGのスコア、及びこれによる生成時間とkey value cacheを用いず、ドキュメントを質問に付け加える方法での生成時間が比較されています。
2-2. Results
実験は、GPUにTesla V100 32GBを8個用いてベースモデルにLlama-3.1-8B-Instructが使われました。

Table 2 では、Sparse RAG、Dense RAGといった従来的なRAG手法とCAGが比較されています。複数のデータセットにおいて、CAGが最も精度が良いことが確かめられています。
以下がCAGと比較されている手法です。
Sparse RAGとは、情報検索時にスパース表現を用いて関連文書を取得し、言語モデルに入力するRAG(Retrieval-Augmented Generation)手法です。論文ではBM25というクエリと参照用ドキュメントから重要なキーワードをマッチさせる手法が使われています。
Dense RAGとは、情報検索時に密なベクトル表現(例:ニューラルネットワークベースの埋め込み)を用いて関連文書を取得し、言語モデルに入力するRAG手法です。論文ではOpenAI Indexというクエリと意味的に似通っているドキュメントを上位からRetrieveする手法が使われています。
使用したデータセットは以下の通りです。
HotPotとは、複数の文書にまたがる推論を必要とする質問応答データセットであり、主に多段推論(multi-hop reasoning)の能力を評価するために用いられます。
SQuADとは、単一の文書内での質問応答タスクを対象としたデータセットであり、文書内の特定の箇所から答えを抽出する能力を評価するために使用されます。
それぞれSmall, Medium, Largeの種類があり、参照用ドキュメントの量が三段階にわたって実験されています。
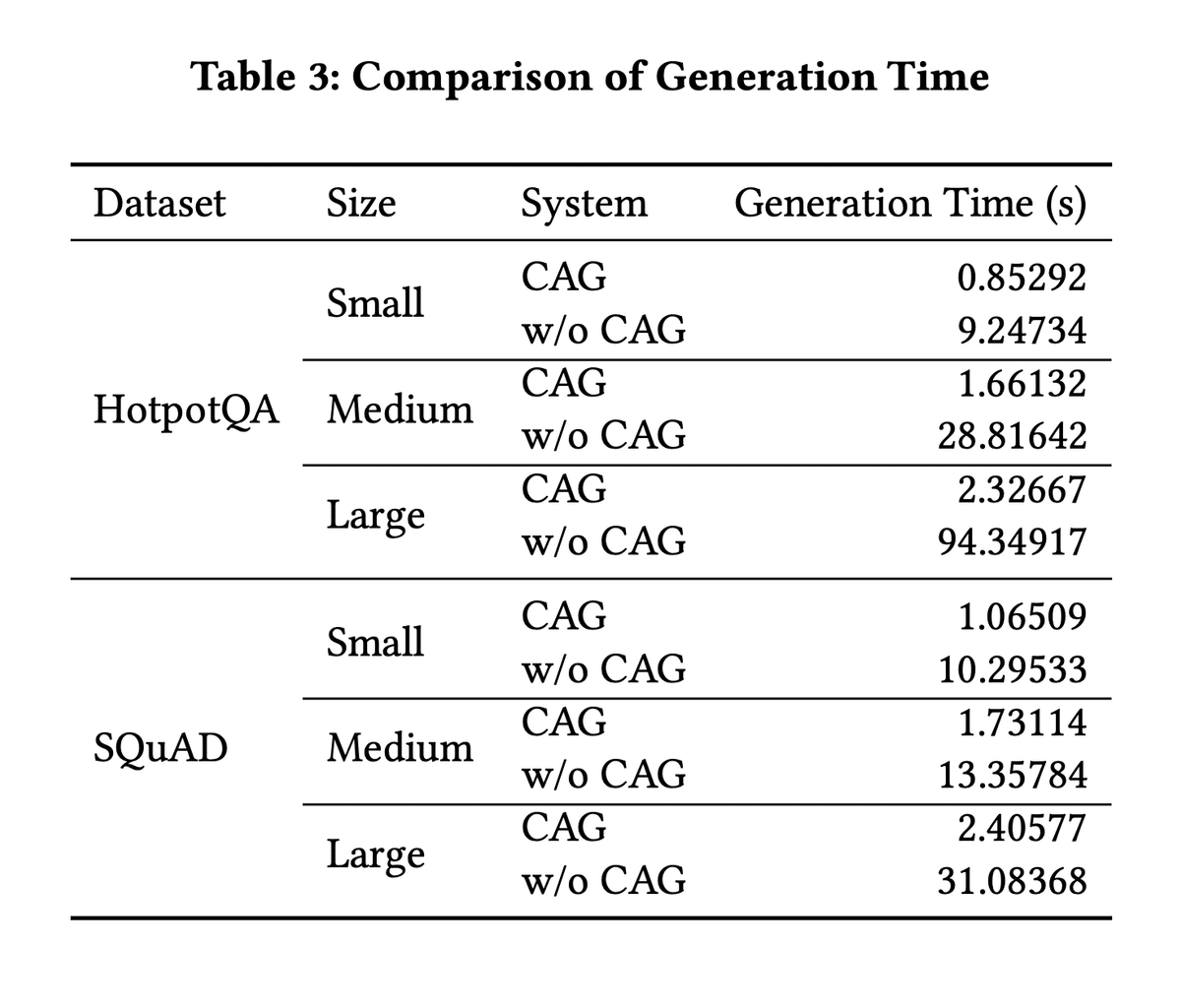
Table 3ではCAGを使う場合と参照用ドキュメントをkv cache化せずに直接LLMに読み込んだ場合の生成速度を比較しています。Cache化によって生成結果を変えずに生成時間が約10分の1になっていることがわかります。
2-3. Conclusion & Comments
ロングコンテキストを受け入れられるLLMが登場したことで、RAGの手法を使わずにRAGと同等以上に独自ドキュメントに基づいてLLMを運用できる可能性を示しました。論文ではCAGにより生成速度が速くなることに重点を置いてますが、現実的な使用においてはCAGとRAGのハイブリッド手法、すなわち独自ドキュメントのうち使用頻度が高いものをcache化し、普段はそれに基づいて生成するが、それに対応できないQueryの時にはドキュメントからRetrieveしてくるというものも提案されています。
3. 実装
本論文のコードはGithubに公開されており、実行環境はローカル(M2 mac, 8GB RAM)で行いました。
生成モデルは論文で試されているLlama-3.1-8B-Instructの代わりに軽くてローカルで実行できるLlama-3.2-1B-Instructを使って実装しました。
まず、HuggingfaceからLlama-3.2-1B-Instruct使用許可を得ます。(使えるようになるまで数分から数時間待つ必要があります。)その後、Llama用のtokenを発行します。
論文著者が作ったhttps://github.com/hhhuang/CAGをフォークし、それをローカルのプロジェクトディレクトリにインストールします。
ターミナルなどでプロジェクトディレクトリに行き、.envファイルに自分のLlamaのトークンを書きます。
nano .env
(.envファイル内)
HF_TOKEN="hf_xxxxxxxx”などと編集
次に、Anacondaの公式サイトから依存関係を整理しやすくするminicondaをインストールします。
仮想環境を立ち上げます。
conda create -n cag_env python=3.10
conda activate cag_env
仮想環境内で必要なライブラリをインストールします。
conda install pytorch::pytorch torchvision torchaudio -c pytorch #install torch separately
pip install -r ./requirements.txt
pip install bitsandbytes
pip install accelerate
論文著者のGithubに書いてある方法で早速CAGでの生成を試します。ただし、modelnameは変えます。maxQuestionパラメータを変えることで、試行回数を変えることができます。
python ./kvcache.py --kvcache file --dataset "squad-train" --similarity bertscore \\
--maxKnowledge 5 --maxParagraph 100 --maxQuestion 100 \\
--modelname "meta-llama/Llama-3.2-1B-Instruct" --randomSeed 0 \\
--output "./result_kvcache.txt"
実行すると、
ValueError: You are trying to offload the whole model to the disk. Please use the disk_offload function instead.
というエラーが出たので、kvcache.pyのload_quantized_model関数内に
model = model.disk_offload(offload_folder="./offload")
という文を追加して、再度実行しました。
rag.pyを実行した時にも同様のエラーが出たのでそちらでも同様にdisk_offload機能を追加します。
以下の三つのコマンドでsquad-trainというデータセットを使って順番にCAG、RAG、cacheなし生成を試しました。
python ./kvcache.py --kvcache file --dataset "squad-train" --similarity bertscore \\
--maxKnowledge 5 --maxParagraph 100 --maxQuestion 100 \\
--modelname "meta-llama/Llama-3.2-1B-Instruct" --randomSeed 0 \\
--output "./result_kvcache.txt"
python ./rag.py --index "bm25" --dataset "squad-train" --similarity bertscore \\
--maxKnowledge 80 --maxParagraph 100 --maxQuestion 100 --topk 3 \\
--modelname "meta-llama/Llama-3.2-1B-Instruct" --randomSeed 0 \\
--output "./rag_results.txt"
python ./kvcache.py --kvcache file --dataset "squad-train" --similarity bertscore \\
--maxKnowledge 5 --maxParagraph 100 --maxQuestion 100 \\
--modelname "meta-llama/Llama-3.2-1B-Instruct" --randomSeed 0 \\
--output "./result_kvcache.txt" --usePrompt
前述にもあるSQuADというデータセット(コマンド内では”squad-train)は、wikipediaページを読解して質問に答える英語のデータセットで、wikiの一部、質問、答えなどが用意されています。本来ならば質問の手掛かりとなる文章はわかっているのを隠して、ある質問からそれに関連する文章を探すように設定することで、RAGの実験用にも使えます。CAGでは、記事群をすべてまとめてコンテキストとしてLLMに読み込ませています。例えば、文章A、問題a、文章B、問題b、文章C、問題cがある場合を考えます。問題aを答えさせる時にRAGでは3つの文章の中から1つ文章を選んで、その文章(間違っていることもあります)と問題aをLLMに入力します。一方で、CAGでは3つの文章全てと問題aをLLMに入力します。
質問の数だけ質問に対して回答が生成されるログがターミナルに現れ、またresult_kvcache.txtなどのようなファイルに記録されます。最後にスコアと実行時間が表示されます。以下が実行結果のサマリーです。
CAGのスコアと時間 (100回)
平均類似度(精度): 0.37528
準備時間: 12522.10秒
平均cache読み込み時間: 0.764秒
平均生成時間: 23.574秒
RAGのスコアと時間 (100回)
平均類似度(精度): 0.43832
平均retrieve時間: 0.0497秒
平均生成時間: 33.025秒
cacheなし生成スコアと時間 (1回)
類似度(精度): 0.10993
生成時間: 15593.60s秒
精度に関して、今回の実験ではRAGの方が高く出ていますが、これはモデルの性能が低いからだと考えられます。性能が低いモデルではコンテキストが長くなると関係ないものに注意を逸らされる可能性が高く、それによって答えが間違う可能性が高くなったかもしれません。CAGの精度に関してこれから様々なモデルで実験してみる余地があります。また、cacheなし生成においては本来はCAGと同じ精度が出るはずですが、時間がとてもかかる都合上一回しか試せていないので異なる精度が出ています。
時間に関して、CAGにおいては準備時間というのはkv cacheを計算するのにかかる時間で、全てのドキュメントを読み込む必要があり、膨大な時間がかかっています。しかし、一度計算してしまえば全ての質問に対してkv cacheを使用できるというのが本論文のメインポイントです。一回あたりの生成に実際にかかる時間はCAGにおいてはcache読み込み時間+生成時間、RAGにおいてはretrieve時間+生成時間、cacheなし生成においては生成時間であり、これを比較するとCAGが一番速い、すなわち質問に対する応答が一番速いことがわかります。一方、実際の運用上は、膨大な時間をかけてkv cacheを生成するコストも考える必要があります。
4. 最後に
大規模言語モデルの進化に伴い、RAGの課題を克服する新たな手法が次々と登場しています。特に、長いコンテキストを一度に処理するアプローチは、シンプルかつ効率的な解決策として注目に値します。今後も、LLMと独自データの統合を最適化する技術の進展を追いながら、より実用的な活用方法を模索していきたいと思います。
今回のテックブログは以上になります。最後までお読みいただき、ありがとうございました。この記事が、少しでも皆様の参考になり、新たな気づきや挑戦のきっかけとなれば幸いです。今後も引き続き、有益な情報をお届けしてまいりますので、どうぞご期待ください。
AIVALIX株式会社では、AIに関する開発やR&Dの案件を常時承っております。また、共同開発・共同研究にご協力いただける企業様も広く募集しております。
AI技術を通じた新たな価値創造に向け、一緒に挑戦していただけるパートナーを心よりお待ちしております。ご興味をお持ちの際は、ぜひお気軽にお問い合わせください。
▼ コーポレートサイトはこちら ▼