
【論文瞬読】複数のAIモデルを組み合わせて評価!大規模言語モデルの新しい評価手法「PoLL」とは?

こんにちは!株式会社AI Nestです。今日は、大規模言語モデル(LLM)の評価に関する新しい研究について紹介します。この研究では、単一の大規模モデルではなく、複数の小規模モデルを組み合わせて評価を行う手法「PoLL」が提案されています。それでは、詳しく見ていきましょう!
タイトル:Replacing Judges with Juries: Evaluating LLM Generations with a Panel of Diverse Models
URL:https://arxiv.org/abs/2404.18796
著者:Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, Patrick Lewis
大規模言語モデルの評価における課題
近年、GPT-4に代表されるような大規模言語モデル(LLM)が目覚ましい発展を遂げています。しかし、これらのモデルの生成物を評価することは容易ではありません。特に、単一の大規模モデルを判定者として使用する場合、以下のような課題があります。
コストが高い
モデル内バイアスが導入される
必ずしも大規模なモデルが必要とは限らない
実際に、異なるLLMを判定者として使用した場合、モデルのパフォーマンスランキングが大きく変化することが示されています(図1上)。

PoLL:複数のモデルを組み合わせた新しい評価手法
これらの課題を解決するために、研究者たちは「PoLL(Panel of LLM evaluators)」という新しい評価手法を提案しました。PoLLは、異なるモデルファミリーから選ばれた複数の小規模モデルを組み合わせてLLMの生成物を評価するというアプローチです。
研究者たちは、3つの異なる判定者設定と6つのデータセットを用いて実験を行い、PoLLの有効性を検証しました。その結果、以下のような知見が得られました。
PoLLは人間の判断と高い相関を示す(図1下、表1)
PoLLはGPT-4よりも7倍以上安価である
PoLLを使用することで、モデル内スコアリングバイアスが低減される

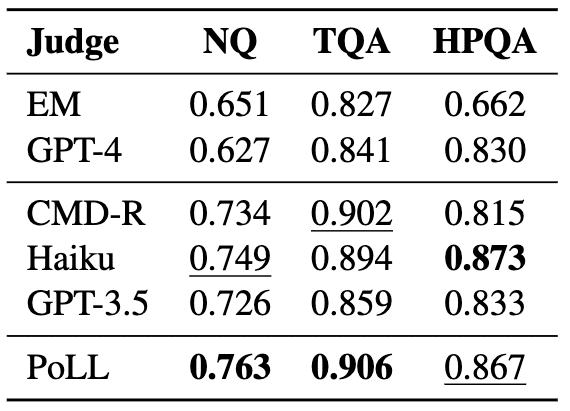
これらの結果は、PoLLが大規模言語モデルの評価において非常に有望な手法であることを示しています。
PoLLのさらなる検証:ChatbotArenaでの比較
研究者たちは、PoLLの有効性をさらに検証するために、ChatbotArenaというベンチマークを用いて実験を行いました。その結果、PoLLによるランキングが、GPT-4による判定よりも人間の判断と高い相関を持つことが明らかになりました(表2、図2)。

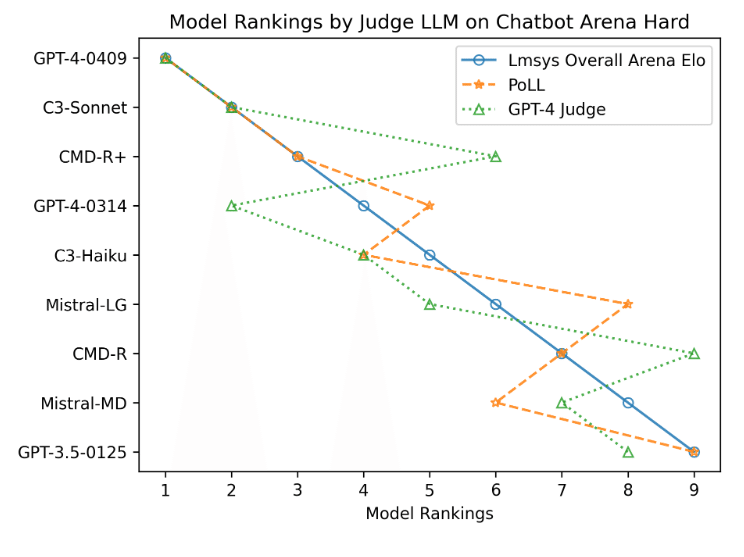
PoLLの実用性と今後の課題
PoLLは、コストの面でも優れていることが示されており、実用面での利点が大きいと考えられます。また、複数のモデルを組み合わせることで、より信頼性の高い評価が可能になるでしょう。
ただし、PoLLの構成要素となるモデルの選択については、まだ課題が残されています。最適なパネル構成を探索するためには、さらなる研究が必要です。また、数学や推論などの他のタスクへのPoLLの適用可能性についても、より詳細な検討が求められます。
まとめ
今回紹介した研究は、大規模言語モデルの評価における新しいアプローチを提案し、その有効性を実験的に示したものです。PoLLのようなアプローチが、今後のLLM評価の標準的な手法の一つになる可能性は大いにあります。
同時に、本研究で指摘されている課題についても、今後の研究で解決されていくことを期待したいですね。LLMの評価手法の発展は、より高度な言語モデルの開発につながります。今後のさらなる進展に目が離せません!
以上、大規模言語モデルの新しい評価手法「PoLL」についてお伝えしました。みなさんも、最新の研究動向にぜひ注目してみてください。それでは、またお会いしましょう!