
【論文瞬読】LLMの幻覚と戦う!知識編集の最新評価基準「HalluEditBench」

こんにちは!株式会社AI Nestです。ChatGPTやLlamaなどのLLMの利用が広がる中、「幻覚」という重要な課題が注目を集めています。今回は、この問題への解決策として注目される知識編集手法とその評価基準「HalluEditBench」についてご紹介します。
タイトル:Can Knowledge Editing Really Correct Hallucinations?
URL:https://arxiv.org/abs/2410.16251
所属:Illinois Institute of Technology, Cisco Research, Emory University
著者:Baixiang Huang, Canyu Chen, Xiongxiao Xu, Ali Payani, Kai Shu
🤔 LLMの「幻覚」問題とは?
「幻覚(Hallucination)」とは、LLMが事実と異なる情報を自信満々に出力してしまう現象です。例えば、「OpenAIのChief Scientistは誰ですか?」という質問に対して、「Ilya Sutskeverです」と回答してしまうケース(実際はJakub Pachocki)などが該当します。

編集前:37-61%、編集後:ほとんどの手法で95-100%の高性能
(既存の評価方法の限界を示す重要なエビデンス)

(5つの評価軸(Efficacy、Generalization、Portability、Locality、Robustness))
この問題は、ビジネスでの致命的なミスや、医療・法律など重要分野での利用制限の原因となっており、LLMの実用化における大きな障壁となっています。さらに、誤情報による損害の責任問題など、法的リスクも存在します。
💡 知識編集(Knowledge Editing)という解決策
従来の対応方法との比較
$$
\begin{array}{|c|c|c|} \hline
手法 & メリット & デメリット \\ \hline
再学習 & 確実な修正が可能、包括的な更新 & 莫大なコスト、時間がかかる \\ \hline
プロンプト工学 & 即時対応可能、低コスト & 一時的な対応、確実性が低い \\ \hline
知識編集 & ピンポイントの修正、比較的低コスト & 副作用の可能性、評価が難しい \\ \hline
\end{array}
$$
知識編集手法には、特定のニューロンを編集するROME、複数の知識を同時に編集できるMEMIT、コンテキスト学習を活用するICE、逐次的な編集に強いGRACEなど、様々なアプローチが存在します。各手法にはそれぞれ特徴があり、用途に応じて選択する必要があります。
📊 HalluEditBench:革新的な評価基準
HalluEditBenchは、芸術、ビジネス、エンターテインメントなど9つのドメインにわたる6,000以上の実例を含む包括的なデータセットです。Llama2-7B、Llama3-8B、Mistral-v0.3-7Bという3つの主要なLLMで検証が行われており、その評価は以下の5つの軸に基づいています:

9つのドメイン・26のトピック
5つの評価軸
効果(Efficacy)は誤った知識の修正成功率を、汎化(Generalization)は言い換えられた質問への対応能力を測ります。移植性(Portability)では2-6ホップの推論質問への対応を、局所性(Locality)では関連のない知識への影響を評価。そして頑健性(Robustness)では外部操作への耐性を検証します。
🔍 衝撃の評価結果
興味深いことに、従来のデータセットでは95-100%という高い性能を示していた手法が、HalluEditBenchでは大きく性能が低下することが判明しました。実際の幻覚修正タスクにおいて、Efficacyで60-80%、Generalizationで50-70%程度の性能にとどまっています。

各手法のEfficacyスコアを示す図
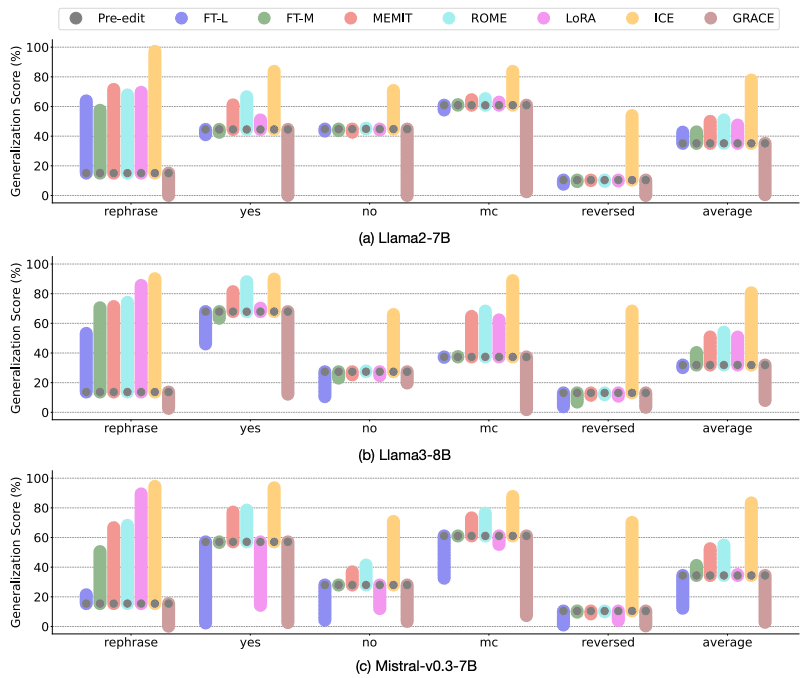
に対する各手法の汎化性能を示す図

human domain、places domain、overall performance の3つの観点から評価

ドメインごとの影響度、モデルごとの違いが示される

ターン数による性能変化、モデルごとの違いを示す
手法別の特徴
$$
\begin{array}{|c|c|c|} \hline
手法 & 強み & 弱み \\ \hline
ICE & Efficacy, Generalization & Robustness \\ \hline
GRACE & Efficacy, Locality & Portability \\ \hline
ROME & バランス型 & 特に際立つ点なし \\ \hline
MEMIT & Locality & Generalization \\ \hline
\end{array}
$$
💼 実務での活用に向けて
実務でLLMの知識編集を活用する際は、まず用途に応じた手法選択が重要です。高精度が求められる場合はICEやGRACE、安定性を重視する場合はROME、大規模な更新が必要な場合はMEMITが適しています。
また、事前評価やモニタリング、フォールバック策の準備など、包括的なリスク管理体制の構築も不可欠です。特に副作用の監視と、問題が発生した際のロールバック手順の確立は重要なポイントとなります。
🚀 今後の展望
技術的な課題として、より大規模なモデルへの対応や計算効率の改善、ドメイン依存性の解消などが挙げられます。また、マルチモーダルモデルへの応用や自動化された知識更新システムの開発なども期待されています。
まとめ
HalluEditBenchは、LLMの知識編集手法を実践的に評価する画期的な基準を提供しました。この研究により、既存の評価方法の限界が明らかとなり、より実践的な評価の重要性が認識されることとなりました。
AIの実用化が進む中、「幻覚」への対処は避けて通れない課題です。この研究を足がかりに、より信頼性の高いAIシステムの実現に向けた取り組みが加速することを期待しています。