
【論文瞬読】AIが自分の間違いを直せる!? 革新的手法「SCoRe」が切り開くLLMの新時代

こんにちは、株式会社AI Nestです!今日は、大規模言語モデル(LLM)の世界に大きな波紋を投げかける可能性のある新しい研究について深掘りしていきます。その主役は「SCoRe」(Self-Correction via Reinforcement Learning)。この革新的な手法が、LLMの自己修正能力を飛躍的に向上させるかもしれません。さあ、一緒に最先端のAI研究の世界に飛び込んでみましょう!
タイトル:Training Language Models to Self-Correct via Reinforcement Learning
URL:https://arxiv.org/abs/2409.12917
所属:Google DeepMind, Equal Contribution, Randomly ordered via coin flip, Jointly supervised
著者:Aviral Kumar, Vincent Zhuang, Rishabh Agarwal, Yi Su, John D Co-Reyes, Avi Singh, Kate Baumli, Shariq Iqbal, Colton Bishop, Rebecca Roelofs, Lei M Zhang, Kay McKinney, Disha Shrivastava, Cosmin Paduraru, George Tucker, Doina Precup, Feryal Behbahani, Aleksandra Faust
SCoReの登場:AIの自己改善の新たなステージへ
SCoReって何がすごいの?
SCoReの特徴を簡単にまとめると:
完全に自己生成データだけを使用
外部からの助けなしで自己修正が可能
単一のモデルで動作(複数モデル不要)
多段階の強化学習を活用

つまり、LLMが自分で自分を教育して、より賢くなるんです。まるでSF映画のような話ですが、これが最新のAI研究の現実なんです!
なぜこれが画期的なの?
従来のLLMには大きな課題がありました。一度答えを出すと、それを修正するのが苦手だったんです。人間なら「あ、ちょっと待って、ここ間違えたかも」と言えますよね。でも、AIにはその能力がありませんでした。
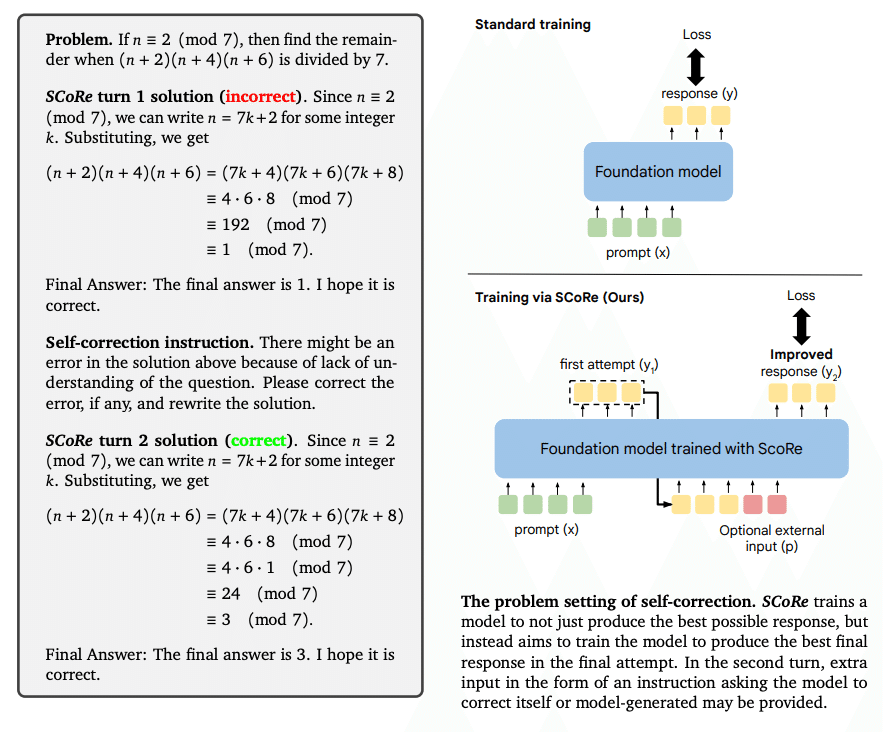
SCoReはこの問題に正面から取り組んでいます。この技術により、LLMが:
自分の間違いを認識する
その間違いを修正する
より良い回答を生成する
という一連のプロセスを学習できるようになるんです。これは、AIの応用範囲を大きく広げる可能性を秘めています。
SCoReのメカニズム:AIに「自己反省」を教える
SCoReは、2つの重要な段階を経てLLMを訓練します。
Stage I:賢い初期化
この段階では、モデルに「自己修正」の基本を教えます。ただし、ここでのポイントは単に教えるだけではありません。
モデルが過度に特定のパターンに固執しないよう工夫
多様な修正パターンを学習できるよう設計
これにより、モデルは柔軟な自己修正能力の基礎を身につけます。
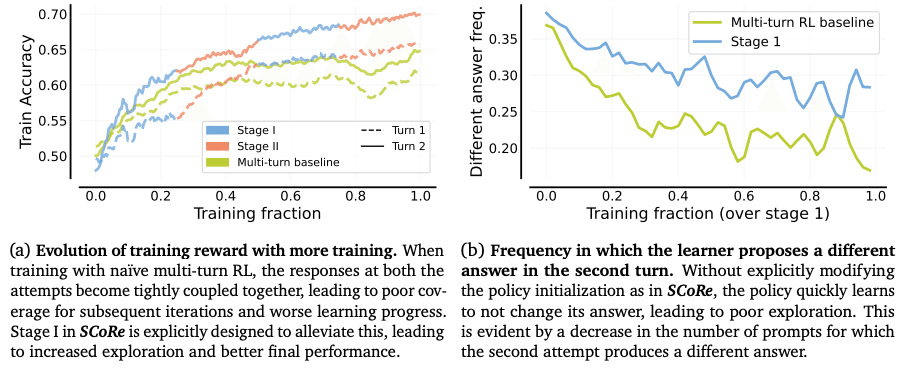
Stage II:実践的な強化学習
ここからが本番です。モデルは実際に自己修正を繰り返し練習します。
多段階の強化学習を採用
「報酬整形」という技術を使用
モデルが正しい方向に学習するよう誘導
この段階で、モデルは自己修正のスキルを磨き上げていきます。
技術的な深掘り:SCoReの革新性
SCoReが従来の手法と大きく異なる点がいくつかあります。

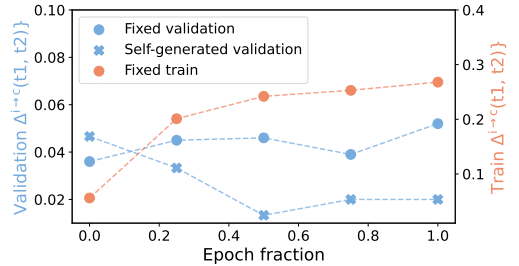
オンライン学習: 事前に用意したデータセットではなく、モデル自身が生成したデータを使って学習します。これにより、より実践的な自己修正能力を獲得できます。
報酬整形: 単純に正解・不正解だけでなく、修正の過程自体も評価の対象とします。これにより、モデルは「どのように修正すべきか」も学習します。
多段階アプローチ: 初期化と強化学習を分けることで、モデルが陥りがちな「局所解」を回避します。
単一モデル: 複数のモデルを組み合わせる従来の手法と異なり、単一のモデルで完結します。これにより、計算効率とスケーラビリティが向上します。
実際の成果:数字で見るSCoReの威力
研究チームは、SCoReを使ってGoogleの最新LLMであるGeminiモデルを訓練しました。その結果は驚くべきものでした:
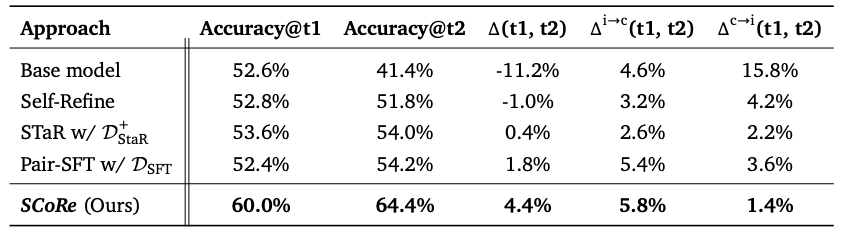

MATH(数学問題解決)ベンチマークで15.6%の改善
HumanEval(コーディング)ベンチマークで9.1%の改善
これらの数字が示すのは、単なる微々たる改善ではありません。既に高性能だったモデルが、さらに大きく性能を向上させたのです。
特に注目すべきは、自己修正によって正答率が向上しただけでなく、誤答を正答に修正する能力も大幅に向上したことです。これは、SCoReがただ単に「より良い回答を出す」だけでなく、真の意味で「自己修正能力」を獲得したことを示しています。
SCoReの潜在的な応用範囲

SCoReの技術は、様々な分野で革命的な変化をもたらす可能性があります:
教育支援: 生徒の誤りを的確に指摘し、段階的な指導を行うAIチューターの開発
プログラミング支援: バグの自動検出と修正を行う高度なコーディングアシスタント
医療診断: 初期診断の誤りを自己修正し、より正確な診断を提供する医療AIシステム
自然言語処理: より自然で文脈に適した文章生成や翻訳の実現
ロボティクス: 実世界のタスクにおいて、失敗を自己修正しながら学習するロボットAI
今後の展望と課題

SCoReは確かに画期的な技術ですが、まだ発展の余地があります:
より多くのターンでの自己修正能力の向上
タスクの多様性に対する一般化能力の検証
計算効率のさらなる改善
研究チームも、これらの課題を認識しており、今後の研究でさらなる進展が期待されています。
まとめ:AIの新時代の幕開けか
SCoReは、LLMの自己修正能力を向上させる画期的な手法です。この研究は、AIがより自律的に学習し、成長できる可能性を示しています。
自己修正能力は、人間の知性の重要な特徴の一つです。SCoReのような技術がさらに発展すれば、AIはこの重要な能力をより深く獲得し、真の意味で「知的」なシステムに一歩近づくかもしれません。
今後、SCoReを基盤とした技術が発展すれば、私たちの日常生活やビジネスにおけるAIの役割は、さらに大きく、そして重要になっていくでしょう。エラーを自己修正し、常に学習・成長し続けるAI。その未来は、期待と同時に新たな倫理的課題も提起するかもしれませんね!