
【論文瞬読】言語モデルは本当に「考えて」プランを立てているの? - 最新研究から見える現実と課題

こんにちは!株式会社AI Nestです。今回は、言語モデルのプランニング能力に関する最新の研究から見えてきた興味深い発見についてお話ししたいと思います。最近話題のGPT-4やLlama3など、様々な言語モデルを使って「計画を立てる」というタスクに挑戦させてみると、実は予想以上に難しい課題が見えてきたんです。
タイトル:Revealing the Barriers of Language Agents in Planning
URL:https://arxiv.org/abs/2410.12409
所属:Fudan University、Carnegie Mellon University、ByteDance Inc. 、The Ohio State University
著者:Jian Xie, Kexun Zhang, Jiangjie Chen, Siyu Yuan, Kai Zhang, Yikai Zhang, Lei Li, Yanghua Xiao
はじめに:なぜプランニングが重要なのか
私たちが日常的に行っている「計画を立てる」という作業。例えば旅行の計画を立てるとき、私たちは予算、時間、好み、様々な制約を考慮しながら最適な選択をしていきますよね。これは実はかなり高度な知的作業なんです。
AIがこのような計画立案をできるようになれば、例えばこんな活用が期待できます:
• 複雑な業務プロセスの最適化
• パーソナライズされた旅行プランの提案
• 効率的なリソース配分の計画立案
最新研究で分かったこと:意外な事実
最近発表された研究では、現在最高性能とされる言語モデルでさえ、現実世界の計画立案タスクで驚くほど低い成功率しか達成できていないことが明らかになりました。

この図は、様々なモデルと手法での性能比較を示しています:
• Direct:単純に直接プランニングをさせた場合
• Behavioral Cloning:過去の成功・失敗例からの学習
• Oracle Feedback:評価結果からのフィードバック学習
• Reference:人間の作った参照例からの学習
• Fine-tuning:モデルの再学習による改善
見ていただけるように、最新のモデルでも、特に現実世界の旅行プランニング(TravelPlanner)では20%未満の成功率に留まっています。これは予想以上に厳しい結果と言えるでしょう。
なぜこんなに成功率が低いのか?
研究チームが詳しく分析したところ、主に2つの大きな問題が見つかりました:
1. 制約条件の扱いが苦手

この図は、異なるモデルでの制約とエピソード記憶の影響度を示しています。予想以上に制約条件の影響度が低いことが分かります。具体的には:
• 予算内に収めなければならない
• 営業時間内に訪問する必要がある
• 順序に依存関係がある
といった制約条件を適切に考慮できていないケースが多いんです。
2. 長期的な目標を見失いがち

この図は、プランニングのステップ数/日数が増えるにつれて性能が低下していく様子を示しています。特に:
• 計画が長くなるほど、最初の目標への注目度が低下
• 途中で一貫性を失う傾向
• 制約条件から外れていくケースの増加
が確認されています。
改善への取り組み:2つのアプローチ
現在、これらの問題を解決するために、主に2つのアプローチが試されています:
1. エピソード記憶の更新
これは人間で言うところの「経験から学ぶ」アプローチです。過去の成功・失敗例から教訓を抽出し、新しい計画立案に活かす方法です。例えば、予算超過で失敗した経験から、より効率的な予算配分を学習するといった具合です。
2. パラメトリック記憶の更新
モデル自体の能力を向上させる方法です。成功例を使ってモデルを再学習(ファインチューニング)することで、プランニング能力の向上を図ります。
意外な発見:制約の影響と組み合わせの効果
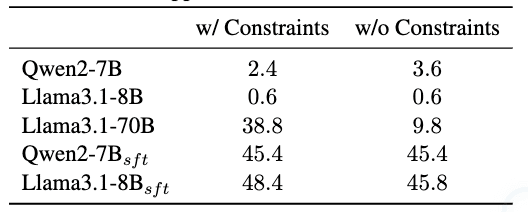
この表は制約の有無による性能比較を示しています。興味深いことに:
• 一部のモデルでは制約を取り除いた方が性能が向上
• 他のモデルでは大幅な性能低下
• ファインチューニング済みモデルではほとんど影響なし
という様々なパターンが観察されました。
また、2つの改善アプローチを組み合わせると、むしろ性能が低下することも分かりました。考えられる理由として:
情報の重複による干渉
学習済みのパターンとの競合
決定プロセスの複雑化
が挙げられます。
実務での活用に向けて:現実的な提案
では、現状でどのように言語モデルのプランニング機能を活用すべきでしょうか?
推奨される使い方
人間との協調モード
• モデルによる初期プラン生成
• 人間による検証と修正
• モデルによる細部の調整タスクの適切な分割
• 長期計画は複数の短期計画に分割
• 各フェーズでの目標を明確化
• 定期的な整合性チェック制約条件の明示的な管理
• 各制約条件の優先順位付け
• 制約違反の自動チェック
• 段階的な制約の適用
今後の展望
この研究から見えてきた課題は、実は言語モデルの本質的な限界というよりも、「まだ解決できていない技術的課題」と捉えるべきでしょう。
期待される発展:
より洗練された制約処理メカニズム
長期依存関係の改善
よりロバストな学習アーキテクチャ
まとめ
現状の言語モデルは、確かに印象的なプランニング能力を示すことがありますが、まだまだ人間レベルの計画立案には達していません。しかし、これは限界というよりもチャンスと捉えるべきでしょう。
この研究が示唆するように、課題が明確になってきた今こそ、より効果的な解決策を見出すチャンスなのかもしれません。実務では、これらの限界を理解した上で、人間とAIの良いとこ取りをする「ハイブリッドアプローチ」が現実的な選択となりそうです。