
【論文瞬読】MMLU-Pro: 大規模言語モデルの真の能力を引き出す革新的なベンチマーク

こんにちは、みなさん!株式会社AI Nestです。今日は、大規模言語モデル(LLM)の評価において重要な役割を果たす新しいベンチマーク、MMLU-Proについてお話ししたいと思います。
タイトル:MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
URL:https://arxiv.org/abs/2406.01574
所属:University of Waterloo, University of Toronto, Carnegie Mellon University
著者:Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, Tianle Li, Max Ku, Kai Wang, Alex Zhuang, Rongqi Fan, Xiang Yue, Wenhu Chen
MMLUの問題点とMMLU-Proの登場
LLMの評価といえば、MMLUが広く使われてきましたが、最近ではいくつかの問題点が指摘されています。
選択肢が4つしかないため、LLMが推論を使わずに正解にたどり着けてしまう可能性がある。
知識中心の質問が多く、特にSTEM分野では推論能力の評価が十分でない。
アノテーション誤りや答えられない質問が一定数含まれており、最先端のモデルがこの限界に達してしまっている。
これらの問題点を克服するために登場したのが、MMLU-Proなんです!
MMLU-Proの特徴
MMLU-Proには、以下のような特徴があります。

選択肢を10個に増やし、LLMが簡単に正解にたどり着けないようにしました。これにより、LLMの推論能力をより的確に評価できるようになりました。
STEMウェブサイト、TheoremQA、SciBenchから質問を追加し、推論を必要とする問題の割合を増やしました。これにより、知識だけでなく推論能力も評価できるようになりました。
専門家によるレビューを2段階で行い、データセットのノイズを減らしました。第1段階では正解の検証と不適切な質問の排除を行い、第2段階では誤答の選択肢の検証を行いました。
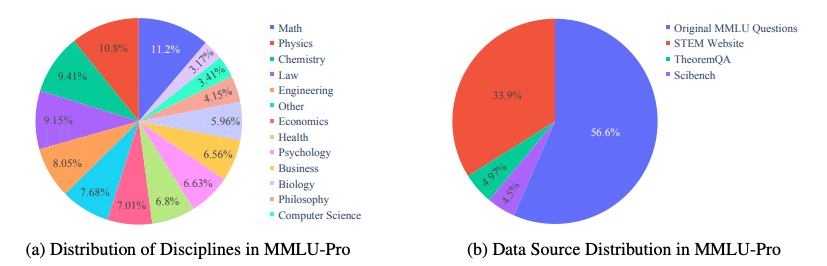
さらに、MMLU-Proは数学、物理、化学、法律、工学、心理学、健康など14の多様な分野をカバーし、12,000以上の質問を含んでいます。これにより、LLMの能力を幅広い分野で評価できるようになりました。

MMLU-Proの実験結果
実際にMMLU-Proを使って50以上のLLMを評価したところ、以下のような興味深い結果が得られました。
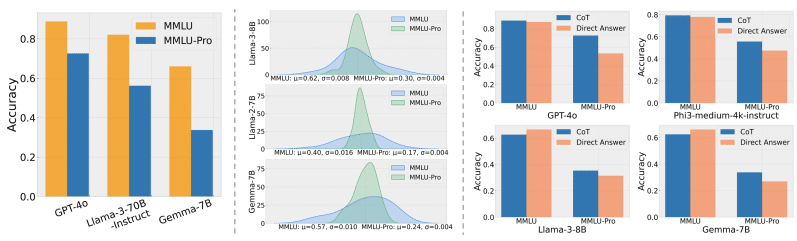
MMLU-Proはより難易度が高く、モデル間の性能差をより明確に示せること。例えば、GPT-4oとGPT-4-TurboのMMLUでの性能差は1%ですが、MMLU-Proでは9%に拡大しました。
Chain-of-Thought(CoT)を使うことで性能が大きく向上すること。例えば、GPT-4oではCoTを使うことで19%の性能向上が見られました。一方、MMLUではCoTを使うと逆に性能が下がるという結果になりました。

特にCoTによる性能向上は、MMLU-Proが複雑な推論を必要とする問題を含んでいることを示しています。これは、MMLUの知識中心の質問とは対照的です。

また、MMLU-Proはプロンプトのバリエーションに対してもロバストであることが示されました。24種類のプロンプトを使った評価では、モデルのスコアのばらつきがMMLUの4-5%からMMLU-Proの2%に減少しました。
今後の展望
MMLU-Proは、LLMの評価における重要な一歩を示した論文だと思います。一方で、いくつかの限界も指摘されています。
選択式の形式では、開放型の回答と比べて理解の深さや創造性を十分に評価できない可能性がある。
言語モデルのみを対象としているため、画像や音声など複数のモダリティを統合したマルチモーダルモデルの評価には使えない。
今後は、こうした限界を踏まえつつ、MMLU-Proを活用してLLMの評価を進めていくことが重要だと思います。同時に、LLMの性能向上に合わせて、MMLU-Proをアップデートしていく必要もあるでしょう。
MMLU-Proを出発点として、LLMの評価手法がさらに発展していくことを期待しています!