
【論文瞬読】LLMのIn-Context Recall能力の秘密を解明:新研究が明らかにした重要な知見

こんにちは、みなさん。株式会社AI Nest です!
今日は、大規模言語モデル(LLM)の性能評価に関する興味深い研究について紹介したいと思います。
タイトル:LLM In-Context Recall is Prompt Dependent
URL:https://arxiv.org/abs/2404.08865
所属:VMware NLP Lab
著者:Daniel Machlab, Rick Battle
LLMとIn-Context Recall能力
最近、GPT-4に代表されるLLMの性能が飛躍的に向上し、さまざまな自然言語処理タスクで活躍しています。LLMは、大量のテキストデータを用いて学習された言語モデルで、与えられたプロンプト(入力テキスト)に対して、文脈に沿った自然な応答を生成できます。
しかし、LLMの性能を適切に評価することは簡単ではありません。特に、与えられたプロンプト内の情報を正確に取り出す能力(In-Context Recall)は、LLMの実世界での応用において重要な役割を果たします。例えば、質問応答システムやドキュメント要約など、プロンプト内の情報を正確に理解し、活用する必要があるタスクでは、In-Context Recall能力が不可欠です。
新しい研究の概要
そんな中、ある研究チームが9つのLLMを対象に、「needle-in-a-haystack」メソッドを用いてIn-Context Recall能力を評価した論文を発表しました。この研究では、以下の9つのLLMを対象に評価を行いました:

needle-in-a-haystackメソッドでは、事実(needle)をフィラーテキスト(haystack)に埋め込み、モデルにその事実を取り出させます。研究チームは、3種類のテストを行い、プロンプトの長さとneedleの位置を変化させながら、各LLMのIn-Context Recall能力を評価しました。

研究の主な結果
研究の主な結果は以下の通りです:
LLMのIn-Context Recall能力はプロンプトの内容に大きく依存する
同じLLMでも、プロンプトの内容によってIn-Context Recall能力が大きく異なることが示されました。
したがって、LLMの性能評価には、さまざまな内容のプロンプトを用いた複数のテストが必要です。
学習データと矛盾する情報を含むプロンプトでは、In-Context Recall能力が低下する
LLMの学習データと矛盾するような情報を含むプロンプトでは、In-Context Recall能力が低下することが明らかになりました。
これは、LLMが学習データに過度に依存している可能性を示唆しています。
パラメータ数の増加、アーキテクチャの変更、学習戦略の改善、ファインチューニングによりIn-Context Recall能力が向上する
Llama 2 70BはLlama 2 13Bに比べ、パラメータ数が5倍以上多いため、In-Context Recall能力が向上しました。
Mistral v0.2は、アーキテクチャと学習戦略の改善により、v0.1よりもIn-Context Recall能力が大幅に向上しました。
WizardLMとGPT-3.5 Turboは、ファインチューニングによりIn-Context Recall能力が向上しました。

In-Context Recall能力が低下することを示すヒートマップ
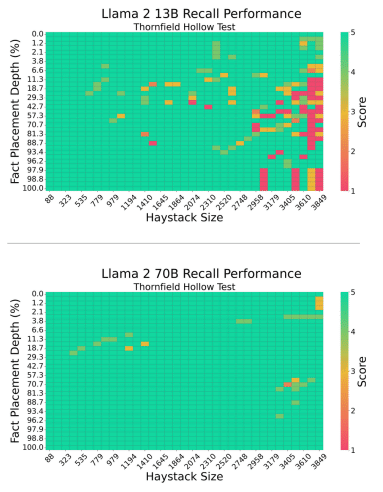
高いIn-Context Recall能力を示すことを表すヒートマップ

高いIn-Context Recall能力を示すことを表すヒートマップ
これらの結果は、LLMの性能評価や実世界での応用を考える上で重要な示唆を与えてくれます。
今後の展望
今回の研究では、9つのLLMと3種類のテストに限定した評価が行われましたが、より多様なLLMやテストを用いた評価も必要だと感じました。また、In-Context Recall能力の向上につながる要因についてより詳細な分析があれば、LLMの改善に役立つでしょう。
さらに、In-Context Recall能力以外にも、LLMの性能を評価する上で重要な指標があります。例えば、論理的な推論能力、常識的な判断力、感情の理解など、さまざまな観点からLLMの性能を評価することが求められます。
まとめ
今回紹介した研究は、LLMのIn-Context Recall能力について重要な知見を提供しており、LLMの評価や応用を考える上で示唆に富む内容でした。LLMの性能評価には、さまざまな内容のプロンプトを用いた複数のテストが必要であり、学習データとの整合性にも注意が必要です。また、パラメータ数の増加、アーキテクチャの改善、学習戦略の工夫、ファインチューニングなどにより、In-Context Recall能力を向上させることができます。
今後、この分野の研究がさらに進展し、LLMの性能向上と実世界での活用が進むことを期待しています。LLMは、自然言語処理の分野に大きな革新をもたらす可能性を秘めています。これからの研究が楽しみですね!