
【論文瞬読】AIが自身を批評?驚きの新技術「CriticGPT」が登場!

こんにちは!株式会社AI Nestです。今日は、AI業界に激震を走らせる可能性のある新技術「CriticGPT」について紹介します。AIが自分自身を評価する?そんな SF のような話が現実になりつつあるんです。さあ、一緒に最先端の AI 研究の世界を覗いてみましょう!
タイトル:LLM Critics Help Catch LLM Bugs
URL:https://cdn.openai.com/llm-critics-help-catch-llm-bugs-paper.pdf
所属:OpenAI
著者:Nat McAleese, Rai (Michael Pokorny), Juan Felipe Cerón Uribe, Evgenia Nitishinskaya, Maja Trebacz, Jan Leike
1. CriticGPT って何?驚きの新技術の全貌
みなさん、ChatGPT や GPT-4 のような大規模言語モデル(LLM)をご存知ですよね。これらの AI は私たちの質問に答えたり、コードを書いたりしてくれます。でも、その出力が本当に正しいのか、安全なのかを判断するのは、実は大変な作業なんです。
そこで登場したのが「CriticGPT」。これは、OpenAI の研究チームが開発した、AI の出力を評価するための AI です。特に、AI が生成したコードの問題点を指摘することに特化しています。
簡単に言えば、CriticGPT は「AI のコードレビュアー」なんです。人間の専門家顔負けの精度で、コードの中のバグや安全性の問題を見つけ出してくれるんですよ。
2. なぜ CriticGPT が必要なの?AI 評価の難しさ
「えっ、AI の出力を評価するのに、なんで AI が必要なの?」って思われるかもしれませんね。実は、ここに大きな問題があるんです。
現在の AI 技術の主流である RLHF(Reinforcement Learning from Human Feedback)は、人間のフィードバックを基に AI を訓練します。でも、AI の能力が人間を超えつつある今、人間が AI の出力を正確に評価できるのか?という疑問が生じているんです。
例えば、AI が書いた複雑なプログラムのバグを、人間が全て見つけられるでしょうか?見逃したバグが重大な問題を引き起こす可能性もあります。そこで、AI 自身に評価をさせよう、というわけです。
3. CriticGPT の驚きの性能
研究チームが行った実験の結果は、正直言って驚きの連続でした。
AI vs 人間のコードレビュー対決:CriticGPT は、人間の専門家よりも多くのバグを発見しました。しかも、その批評は人間のレビューよりも63%も高く評価されたんです!

このグラフを見てください。左側(Figure 1(a))は、ChatGPTとCriticGPTの批評が人間の批評よりも好まれた割合を示しています。CriticGPTの勝率が80%を超えているのがわかりますね。右側(Figure 1(b))は、人間が挿入したバグを発見できた割合です。人間の専門家が50%程度なのに対し、CriticGPTは85%以上のバグを発見しています。これはもう、人間を圧倒する性能と言っていいでしょう。
「完璧」なコードにも問題発見:さらに驚いたことに、人間が「完璧」と評価したChatGPTの学習データの中からも、CriticGPT は数百ものエラーを見つけ出しました。
コード以外でも活躍:CriticGPT はコード以外の一般的なAIアシスタントタスクでも、人間が見逃した問題を24%のケースで発見しました。
4. CriticGPT のしくみ:AI が AI を評価する裏側
さて、CriticGPT がどうやって動いているのか、ちょっと技術的な話もしてみましょう。
CriticGPT の核心は、RLHF(人間のフィードバックによる強化学習)にあります。でも、普通の RLHF とちょっと違うんです。
データ収集:まず、人間に意図的にバグを含むコードを作ってもらいます。これを「タンパリング」と呼びます。
批評生成:次に、AI にこのコードを批評させます。
人間による評価:人間が AI の批評を評価します。どの批評が一番役立つか、包括的か、などを判断します。
モデルの訓練:これらの評価を基に、AI モデルを訓練します。より良い批評ができるように学習していくわけです。
FSBS の導入:Force Sampling Beam Search (FSBS) という新しい技術も使われています。これにより、批評の包括性と精度のバランスを取ることができます。
ここがポイントなんですが、CriticGPT は単にバグを見つけるだけでなく、その批評自体の質も向上させているんです。まさに、AI による AI の評価の進化ですね。
5. CriticGPT がもたらす未来:AI 評価の革命
CriticGPT の登場は、AI 技術の世界に大きな影響を与える可能性があります。
より安全な AI 開発:AI が生成したコードの問題をより正確に発見できれば、AI を使ったソフトウェア開発がより安全になります。
AI の信頼性向上:AI の出力を AI 自身がチェックすることで、全体的な信頼性が向上する可能性があります。
人間と AI のコラボレーション:研究では、人間と CriticGPT のチームが最も効果的だったことも示されています。これは、人間と AI の新しい協力関係の可能性を示唆しています。
AI 安全性研究への貢献:CriticGPT のような技術は、より広い意味での AI の安全性研究にも貢献するでしょう。
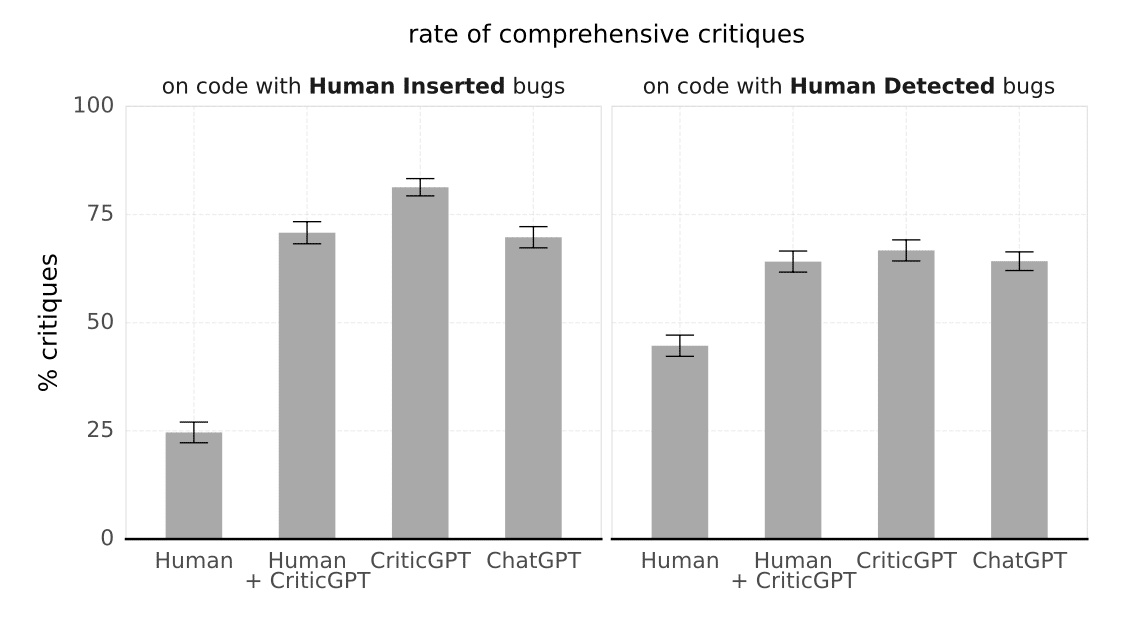
このグラフ(Figure 6)は、人間、人間+CriticGPT、CriticGPT単独、ChatGPTの批評の包括性を比較したものです。人間とCriticGPTのチームが最も包括的な批評を行えていることがわかります。これは、AI と人間の協力が最も効果的であることを示唆していて、非常に興味深い結果です。
6. 課題と展望:CriticGPT の未来
もちろん、CriticGPT にも課題はあります。
評価の正確性:AI による評価が本当に正確なのか、さらなる検証が必要です。
倫理的問題:この技術が悪用される可能性(例:ハッカーがバグを見つけるのに使う)も考慮する必要があります。
一般化の課題:現在はコードに特化していますが、他の分野でも同様に機能するのか、検証が必要です。

このグラフ(Figure 8)は、批評の包括性と幻覚(誤検出)のトレードオフを示しています。右に行くほど包括的な批評ができますが、同時に幻覚も増えてしまうんです。CriticGPTは、このバランスを取るのが上手なんですね。でも、完璧なバランスを取るのは難しく、これが今後の大きな課題の一つになりそうです。
研究チームは、これらの課題に取り組むための今後の研究方向性も示しています。長期的な実験や、AI によるバグの挿入など、興味深いアイデアが提案されています。
最後に:AI が AI を評価する時代の幕開け
CriticGPT の登場は、AI 技術の新たな章の始まりを告げているのかもしれません。AI が自身を評価し、改善していく。そんな未来が、もう目の前に来ているんです。
でも、忘れてはいけないのは、最終的に AI を使うのは私たち人間だということ。AI と人間がどうやって協力していくのか、その答えを見つけていくのが、これからの大きな課題になりそうです。
みなさんは、AI が AI を評価する未来をどう思いますか?コメント欄で皆さんの意見を聞かせてください!
それでは、次回のブログでまたお会いしましょう。AI の世界の冒険は、まだまだ続きます!