
【SeaArt】無料で簡単にLoRAを作成する方法

画像生成AIのhow to記事です。
今回はSeaArtでLoRAを作成する方法についてご紹介します。
■プロフィール
自サークル「AI愛create」でAIコンテンツの販売・生成をしています。
クラウドソーシングなどで個人や他サークル様からの生成依頼を多数受注。
実際に生成した画像や経験したお仕事から有益となる情報を発信しています。
詳細はこちら(🔞コンテンツが含まれます)
➡️lit.link
メンバーシップ(月額500円)に加入して頂くと、300円以下の有料記事が読み放題です。
SeaArtとは?
SeaArtは、無料かつオンラインで画像生成ができるサービスです。
ローカルやクラウド環境で画像生成AIを利用している方が多いですが、中には導入が難しかったり、PCスペックが足りなかったりして、始められない方も多いと思います。
SeaArtであればSNSアカウントで簡単にログインができ、ローカル環境と同じモデルを使用して画像生成を楽しむことが可能です。
画像生成以外のAIツールやスマホアプリもあるので、PCを持っていなくても画像生成を始めることができます。
画像生成方法については別途書いた記事があるのでこちらを参考にしてください。
LoRAとは?
LoRA(Low-Rank Adaptation) は、AI画像生成で特定のスタイルやキャラクターを簡単に反映できるものです。
特定のキャラクターや特徴、画風などを学習したLoRAを適用すると、プロンプトだけでは再現できない画像を生成することができます。
一般的にモデル共有サイトなどからダウンロードして使用しますが、やり方さえわかれば自分で作成も可能です。
今回はこのLoRAをSeaArt上で作成する方法についてご紹介します。
SeaArtは無料でLoRA作成できるの?
正直ギリギリですが、やり方次第で無料でも作成できます。
SeaArtではスタミナという単位が与えられ、それを消費することでサービスの利用が可能です。
今回紹介するやり方だと7枚の画像を700ステップで学習し、消費スタミナが157でした。
無料プランだとスタミナが150なので、枚数を減らすか、ステップ数を落とせば150以内に収めることができます。
先に結果をお見せすると、7枚の画像を700ステップで学習したLoRAでもこのクオリティにはなります。
※学習したずんだもんの画像

※LoRAを適用した画像

あと初級プランなら3日間無料トライアルというものがあるので、それを使えば300スタミナ使うことができます。
余裕を持ってLoRA学習したいという人は無料トライアルを試してみてください。
SeaArtでLoRA作成する方法
とりあえず細かいことはあまり書かず、基本的な操作方法のみ紹介します。
結果がイマイチだったり、こだわりたいと言う人は最後に「高級設定」について解説しているので、そちらを参考にしてください。
全体の流れは以下の通りです。
1.学習画像の用意
2.トレーニングページにアクセス
3.モデルの指定
4.学習画像のアップロード&キャプションデータ作成
5.キャプションデータの編集
6.リピート数とエポック数
7.モデル効果プレビューのプロンプト
8.データセット名入力&トレーニング開始
9.学習終了&データの確認
10.LoRAを使用して画像生成
1.学習画像の用意
まずLoRAの学習元となる画像を用意します。
いつもLoRA解説系記事で利用させてもらってるずんだもんの画像をお借りします。
同じ手順で進めたい方は以下のリンクから学習用データをダウンロードしてください。
バナーをクリックするとGoogle Driveに飛ぶので、使用したいデータセットをダウンロードします。
今回は04フォルダにある20_zdm 1boyを使用します。
2.トレーニングページにアクセス
SeaArtにログインして創作からトレーニングページに移動してください。

左上のデータセット作成をクリックして設定画面に移動します。

3.モデルの指定
ここでは画像の学習元となるモデルを選択します。
基本「このモデルのテイストでLoRAを作りたい」というものを選んでOKです。
ただ二次元で出力したいなら二次元モデル、三次元なら三次元の方が無難です。
あと現在色んなモデルが出回っていますが、全てにベースとなっているモデルがあります。
それがSD1.5、SDXL、Fluxと呼ばれるものです。
またSDXLにはponyやIllustriousなどの派生モデルもあります。
SD1.5モデルで学習したLoRAは、ベースモデルがSD1.5のモデルにしか使えないので、そこだけ注意してください。
今回はSDXLのponyというモデルを使用します。
まずSDXLのアイコンをクリックします。

基本モデルの部分がSDXLに変わるので、プルダウンから「もっと選ぶ」をクリックします。

そうすると一覧が表示されるので、ここから好きなモデルを選んでください。
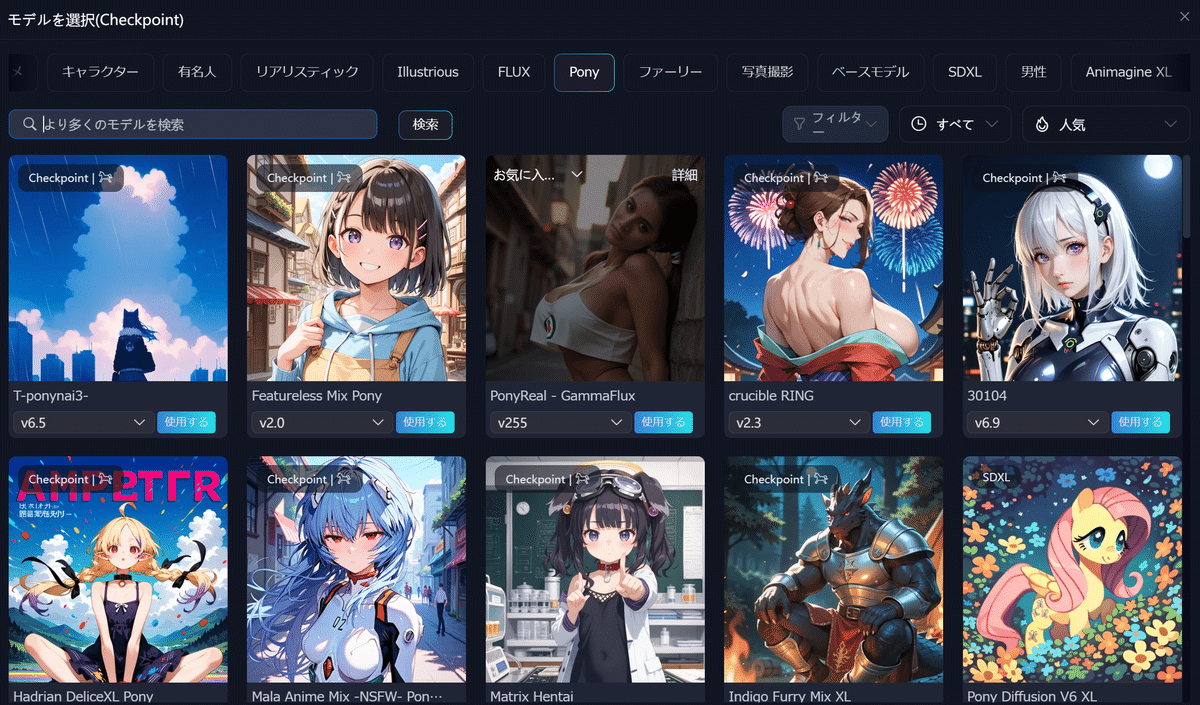
この記事ではAuthakuMixというモデルを使用します。
同じ手順で進めたい方は検索に「AuthakuMix」と入れて選択してください。

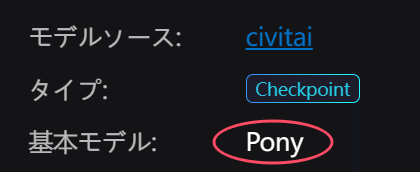
一応詳細画面で基本モデル(ベースモデル)が何になっているか確認できます。
4.学習画像のアップロード&キャプションデータ作成
LoRA学習には画像と、画像の特徴をテキストで出力したキャプションデータが必要です。
ずんだもんのフォルダにあるtxtファイルがそのキャプションデータです。
両方取り込めばすぐ学習が始められますが、今回はキャプションデータの作成方法も解説したいので画像のみ使用します。
まずは画像アップロードからずんだもんの画像取り込んでください。
bmpが対応していないのでPNGの7枚だけでOKです。
※もし画像・キャプション両方取り込んで学習したい場合は、データセットアップロードから行ってください。

次に画面下部でキャプションデータを作るための設定をします。

切り抜き方式:画像のどこを切り抜くか(切り抜き後の画像が学習に使われる)
切り抜きサイズ:そのまま切り抜くサイズ
タグ付けアルゴリズム:キャプションデータ作成に使用するアルゴリズム
タグ付け閾値:画像の特徴をどの程度抽出するかを調整するもの。
値が高いと主要部分のみ抽出され、細かい要素は出力されない
値が低いと多くの要素がキャプションとして出力される。ただ学習にあまり関係ないオブジェクトや小物が抽出される可能性がある
トリガーワード:他のキャプションデータの要素を紐づけるキーワード
今回元画像が512*512なので切り抜きはしません。
アルゴリズムは人に寄りますが、プルダウンの中だとtaggerが一般的かと思います。
トリガーワードはLoRAと一緒に使うプロンプトだと思ってください。
この状態で「切り抜き/タグ付け」をクリックすると処理が始まり、キャプションデータが紐づけられます。

5.キャプションデータの編集
どの画像でもいいのでクリックしてキャプションデータの編集画面を開きます。
上が表示している画像のキャプションデータ、下が画像全部のキャプションデータを統合したものです。

ここではより強く学習したい要素を削除します。
説明が難しいのでLoRAはそういうものだと考えてください。
例えばずんだもんだったら緑髪とか緑の服装が特徴的だと思います。
ですので、今回は下のキャプションから以下を削除しておきます。
green_hair
short_sleeves
suspenders
green_footwear
shirt
shorts
green_shorts
suspender_shorts
green_sailor_collar
×をクリックすると確認画面が出るので1つずつ進めてください。
6.リピート数とエポック数

左側のパラメータからリピート数とエポック数を設定します。
これらは各画像、または画像全体を何回学習するかです。
リピート数:各画像を何回繰り返し学習するか
エポック数:全ての画像を何回学習するか
今回画像が7枚なので7枚学習が終わったら1エポックとカウントします。
ここの適切な値については本当にいろいろな情報があり、正直私もよくわかってません。
なので結果を見て調整するしかないと思います。
あとSeaArtは使用する画像枚数やここの値によって消費スタミナが変わります。
最初に書いた通り予想消費数が120、実際の消費量は157でした。
なので無料プラン内に収めたい方は予想消費が100前後になるよう調整した方がいいかもです。
7.モデル効果プレビューのプロンプト
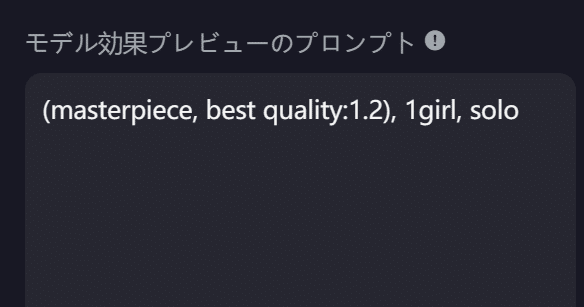
ここは作成したLoRAのサンプル画像を生成するためのプロンプトです。
SeaArtではLoRA学習終了後、エポックごとにLoRAを分割して保存できます。
ここで入力したプロンプトでサンプル画像が作られるので、LoRAに使用するトリガーワードや特徴を予め入れておくと、確認しやすくなります。
8.データセット名入力&トレーニング開始
ここまで設定できたらデータセット名を入力してトレーニングを開始します。
データセット名は今回の設定をSeaArt上に保存する名前、またはLoRAのファイル名になる部分です。
このデータを呼び出してまたLoRA作成が行えます。
今回はzdmにしました。

入力したら右上の今すぐトレーニングをクリックします。
これで学習が始まるのですが、SeaArtは順番待ちがあり、込んでいると少し時間がかかります。
正確に測ったわけじゃないですが、私が学習したときは60人待ちくらいで2~4時間くらいかかりました。
ブラウザを落としても学習は進むので、長そうな場合は一旦別のことやってた方がいいかもしれません。
お金に余裕がある人は、プロプラン以上になると「LoRAトレーニング優先権」を獲得できます。
9.学習終了&データの確認
学習が終わったか確認するには、最初の創作→トレーニングページに移動してトレーニング履歴をクリックします。

タスク完了となっていれば終わっているので、確認をクリックしてください。
そうするとエポック事にプレビュープロンプトで生成したサンプル画像が表示されます。
この中から出来がいいなと思うものを選んで、右下のダウンロード、またはセーブで保存してください。
※ダウンロードはローカル、セーブはSeaArt上に保存されます

10.LoRAを使用して画像生成
セーブしたLoRAはトレーニングページのLoRAタブに表示されます。
使用したいLoRAの右下にある実行ボタンをクリックしてください。
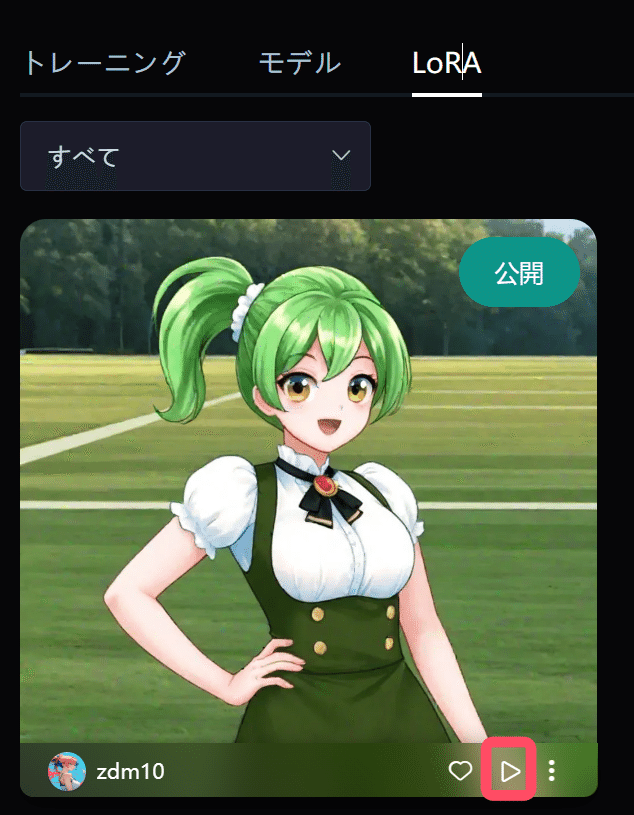
そうすると画像生成ページに移動します。
自動的にLoRAがセットされるので、どの程度LoRAを反映させるか重みを調整してください。
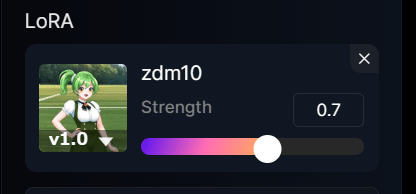
あとはパラメータやプロンプトを入力して生成します。
LoRAを使用するときはプロンプトにトリガーワードを入れるのを忘れないでください。
※画像生成方法については別記事参考
https://note.com/aiaicreate/n/n1b73b19e5041
これで創作ボタンを押せば自分で作ったLoRAで画像が作れます。
・左:重み0.7
・中:重み0.8
・右:重み1
1girlを入れている割には性別がよくわからないのと、枝豆の耳の再現率は低いですが、総ステップ700にしてはずんだもんっぽさは出てると思います。
重み0.7でこのくらい特徴は再現できているので、150スタミナに収めてもある程度のクオリティは維持できるかもしれません。
こんな感じでSeaArtなら簡単にLoRAが作れます。
高級設定
トレーニングページにある高級設定からより細かくLoRA学習の設定ができます。

ただここについては私も全てを理解しているわけではないので、一部ChatGPTに助けてもらってます。
あとSeaArtに公式のマニュアルがあるのでこちらも合わせて参考にしてください。
上に書いたのと同じ項目については除外しているので、高級設定で設定できる部分のみ解説します。
トレーニングパラメータ

・バッチサイズ
バッチサイズは1回の学習ステップで使用するデータの数です。
大きいとメモリ消費量は増えるが、学習速度や安定性が向上。
小さいとメモリ消費量は少ないが、学習速度や安定性が下がる。
設定するポイントとしては、特定の画像の特徴が反映されすぎていた場合、バッチサイズを上げると抑えられる効果があります。
一度に複数のデータを処理することで特徴を平均化できるからです。
これはリピート下げてエポック上げることでも同様の効果が得られます。
逆に特徴があまり出ていないなと感じた場合は、バッチファイルを下げて画像1枚ずつしっかり学習した方がいいかもしれません。
まずは2でやってみて結果を見て調整してみてください。
・混合精度
混合精度は、モデル学習時に計算精度(データの数値表現)を調整して効率化する方法を指します。
基本はデフォルトのFP16で問題ありません。
なし: 精度重視、計算は遅いが安定。
FP16: 高速&メモリ効率◎、一部で精度低下のリスクあり。
BF16: FP16より安定(特に数値範囲が広いデータ)、効率は少し劣る。
サンプル画像の設定
ここはLoRAごとのサンプル画像を生成するときのパラメータなので学習には直接関係しません。
自由に設定してください。
保存設定

・NラウンドごとにLoRAを保存
エポック数÷N(値)で分割してLoRAを保存します。
上記のずんだもんだと10エポックでここを1に設定していたので、10÷1でLoRAが10分割されていました。
2だったら2エポックずつ保存されるので5個になります。多分。
※実際に試してないので間違ってたらすいません
・LoRAの保存精度
LoRAを保存する数値表現の形式を指定するものです。
ファイルサイズや互換性に影響しますが、ここも基本はFP16で問題ありません。
FP32(Float):精度が重要で、サイズを気にしない、追加学習を予定している場合に使用
FP16:軽量で十分な精度を保てるもの
BF16:最新のハードウェア環境で、FP16の安定性に不安がある場合に選択
学習率&オプティマイザー

・学習率
Learning Rateは、学習画像から抽出される特徴(構図や画風など)をどの程度LoRAに反映させるかを調整するものです。
Learning Rateには2種類あります。
最初の項目は以下2つの値を同時に指定するものです。
U-Net学習率:
画風やスタイルに影響。プロンプト(タグ)では指定されない質感や絵柄がここで学習される
テキストエンコーダー学習率:
構図やポーズに影響。プロンプト(タグ)で指定した要素が反映される
U-Net学習率とテキストエンコーダー学習率を別々に指定した場合は、このLearning Rateの設定は無視されます。
こちらも基本的には 0.0001(1e-4) で問題ありません。
もし結果を見て画風やテイストが強く出すぎる、または構図やポーズがうまく反映されないと感じた場合は、それぞれの値を調整することで、改善できる可能性があります。
・学習率ウォームアップ(%)
これは学習率を徐々に増加させるものです。
例えば、
・Learning Rate:0.0001
・総ステップ数:1000
・学習率ウォームアップ:10%
で学習した場合、最初の100ステップまでは0.0001以下から学習を始め、100ステップになると0.0001で学習されるようになります。
これを行うことの効果は、学習の安定性を高めることです。
LoRAで生成したときプロンプトが効きにくかったり、不自然なアーティファクトが出たりした場合はウォームアップで改善できる可能性があります。
後述するスケジューラーにこの効果がついているものもあるので、そっち使うのもありです。
結果が崩れていなければデフォルトの0ままでも問題ありません。
・学習率スケジューラー
スケジューラーは学習中にLearning Rateを変化させる方法を指します。
よくペースメーカーやブレーキに例えられており、変な学習をしないよう調整しながら安定性と効率を両立させる役割があります。
多分説明するより見た方が早いのでスケジューラーごとに作成したLoRAを比較してみました。
スタミナもったいないのでローカルで作りましたが、SeaArtと設定は同じです。
左上から順に以下のスケジューラーで生成しています。
cosine_with_restarts
cosine
linear
polynomial
constant_with_warmup
constant
なお、constantを使用する場合は学習率ウォームアップは使用できないので注意してください。

個人的にはデフォルトで設定されているcosine_with_restartsが一番安定している印象でした。
正直どういう画像を使ってるか、他のパラメータをどう設定しているかにもよるので、結果を見て変えるのが一番良いと思います。
選び方の基準としては以下のような特徴があるそうです。(ChatGPTの回答)
複数の画風や構図を含む場合:
cosine_with_restarts, constant_with_warmup
多様な特徴を安定的に学習し、適応力を向上させる。
細部やディテールを強調したい場合:
cosine, polynomial
学習率の滑らかな減少が微調整を助け、品質を向上させる。
同じ画風や単純な構図で十分な場合:
constant, linear
シンプルに収束させ、効率良く学習を進められる。
学習が途中で停滞する、結果が不安定な場合:
cosine_with_restarts, constant_with_warmup:
初期の安定化や再スタートで新しい局所最適解を探索できる。
・オプティマイザー
オプティマイザーは、モデルを「良い方向」に改善するための調整役みたいなもので、学習を安定・効率的に進める役割があります。
何を選ぶかによって結果や学習速度に影響します。
こちらも見た方が早いと思うので比較しました。
左上から順に以下のオプティマイザーで生成しています。
AdamW
AdamW8bit
Adafactor
Lion
DAdaptation
DAdaptAdam
Prodigy

脚バグってますが、この生成では一番DAdaptationの再現性がよかったです。
次にAdamW8bit・Lion・DAdaptAdamって感じでした。
なお、使用するオプティマイザーによってlearning rateの変更も必要です。
ローカルのツールだと
・DAdaptation
・DAdaptAdam
・Prodigy
の3つはlearning rateの推奨値が1とされています。
SeaArtだとProdigyは自動的に1になりますが、DAdaptation・DAdaptAdamはデフォルトのままなので、これらを使う場合も1の方がいいかもしれません。
・反復回数
反復回数はスケジューラーがcosine_with_restartsのとき使えるものです。
cosine_with_restartsはlearning rateがコサインカーブに従って徐々に減少し、リセットされてまた上昇します。
通常は学習過程全体で1回行われますが、反復回数を増やすとこの回数を増やせます。
効果としては長時間の学習や複雑な画像のLoRAを作る場合などに安定するようです。
・U-Netのみをトレーニング
プロンプトでは出力されない画風・スタイルのみを学習します。
※U-Netのみ学習したもの(おそらくステップ数不足?であまり画風・スタイルが学習できていません)

・テキストエンコーダのみをトレーニング
プロンプトで出力できる構図・ポーズのみ学習します。
※TEのみ学習したもの(こっちもイマイチです)

・最小SNR(信号/ノイズ比)ガンマ値
ここはChatGPTに聞いてもよくわかりませんでした。
作ったLoRAで生成した画像に一貫性がなかったり、特徴がぼやけたり、不明瞭だった場合はここで調整できるようです。
ネットワーク
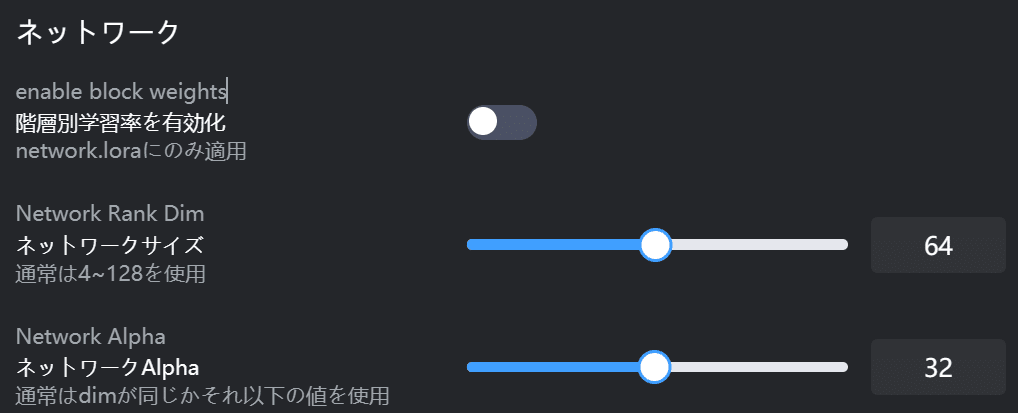
・階層別学習率を有効化
ここは階層別dimを設定できるものです。
階層ごとに学習する画像の特徴を調整できるものですが、どの階層がどういう特徴を持ち、値によってどう結果が変わるのかはよく分かりませんでした。
ここについてはとあるwikiに詳細があるのでそちらを参考にしてください。
リンクが禁止なのでお手数ですが「LoRA階層 wiki」などで検索をお願いします。
・sd-scriptの解説はこちら
https://github.com/kohya-ss/sd-scripts/blob/main/docs/train_network_README-ja.md#%E9%9A%8E%E5%B1%A4%E5%88%A5dim-rank
・ネットワークサイズ
ネットワークサイズは値が高いほど、細かい特徴などを反映しやすくなると言われています。
ちなみにSeaArt上で作ったこのLoRAはDim128。
スケジューラーとオプティマイザーのところで紹介した画像はDim16で作っています。
上記だとそこまで大きな違いは見られませんが、枝豆の耳が全然再現できなかったり、アクセサリーや細かい特徴があるキャラクターとかだと、値を上げることで結果に反映しやすくなるそうです。
・ネットワークAlpha
AlphaはLoRAの重みを調整するもので、値が低いとLoRAが強く適用?されるようです。
注意書きの通り、dimと同じかそれ以下の値(半分)で使用している方が多いと思います。
左がdimと同じ値、右が半分の値で生成したものです。
この結果だけ見るとalphaが半分の方が特徴は出ているかもしれません。

タグ付け設定

・各タグをシャッフル
例えば、キャプションがすべて「1girl, black hair」という固定された順序の場合、LoRAは「1girl」と「black hair」がセットであると誤解し、黒髪の女性を生成しやすくなる可能性があります。
タグをランダムにシャッフルすることで、こうした文脈の影響を排除し、各タグ(1girlやblack hair)を個別に学習させることができます。
・重み付きのトークン使用
キャプションに重みを付けたプロンプトがあり、重みも含めて学習したい場合はONにします。
例)(black hair:1.2)
・N個のトークンを保持
ここはキャプション1つを1トークンするのか、チャンクで1トークンとするのかよく分かりませんでした。
デフォルトの1でもキャプション内の全ての要素を学習できていたので結果がちゃんとしていれば1のままで良いと思います。
・最大トークン長
ここのデフォルトが75なので、プロンプトでいうチャンクの最大長が決められるところだと思います。
ノイズ設定
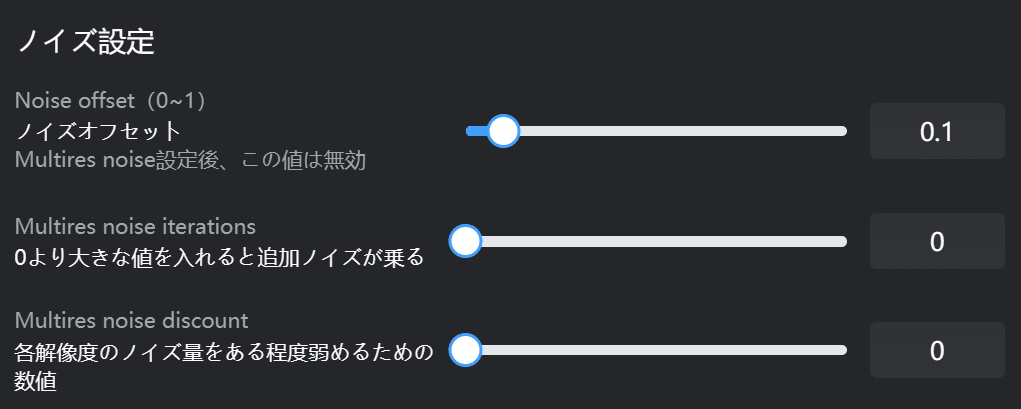
・ノイズオフセット
値を上げるとコントラストやディティールを強調するようになります。
・Multires noise iterations
分からなかったのでChatGPTの解説を記載します。
Multires Noise Iterationsは、スケールごとの処理を組み込むことで、より自然で詳細な生成結果を実現するもの。
スケールは、異なる解像度で画像の特徴やノイズを学習することで、全体的な構成と細かいディテールの両方をバランスよく学習するための技術を指します。
・Multires noise discount
こっちも分からなかったのでChatGPTの解説を記載します。
Multires Noise Iterations 設定が有効な場合に使用されるオプションです。
Multires Noise Iterationsを使うと、複数のスケール(解像度)でノイズを付加して学習を行いますが、ノイズが強すぎると学習が不安定になることがあります。
Multires Noise Discountを設定すると、各スケールで付加されるノイズの量を減らし、学習プロセスを安定化させます。
高級設定

・ランダムシード
画像生成と同じでシード値を固定した場合、学習のプロセスも基本的に同じものとなります。
学習する画像や他のパラメータが同じ条件かつシード値も同じであれば、似たような結果になるというものです。
・clip スキップ
こっちも画像生成と同じCLIPモデルの層をどれくらいスキップするかで、プロンプトの解釈やLoRAの学習結果に影響を与えます。
Clip Skip1:プロンプトを抽象的に解釈しやすくなり、複雑な内容に適ししている
Clip Skip2:具体的な特徴が強調され、明確な結果が得られやすくなる
画像生成と同じでSD1.5ならClip skip2、SDXL以降なら1など元モデルに合わせる感じで良いと思います。
以上SeaArtでLoRA作成する方法について解説しました。
正直それぞれのパラメータがどういうものかを知るより、LoRAを作りまくって何がどう影響するのかを比較しまくった方が理解力は高まると思います。
結果を見て「こうしたいああしたい」っていうのがあれば「じゃあどうしたらいいか」を考えた方が簡単だし楽しいからです。
最終的に自分好みのLoRAができれば良いので、とりあえず作ってみてそこから調整してみてください。
当サークルではこのようなAIに関するさまざまな情報を発信しています。
メンバーシップに加入して頂くと一部の有料記事は読み放題です。
AI技術の向上、マネタイズ方法などに興味がある方は、ぜひご検討ください。
もしこの記事が少しでも役に立った場合は、いいねやフォローして頂けると励みになります。
最後まで読んでいただき、ありがとうございました。
いいなと思ったら応援しよう!
