
rinna-youri-7b-instructionを作成済みの試験PGやAPIサーバ・クライアントで試す。

https://note.com/ai_meg/n/nc0206327dd8f昨日、rinna社から新しいモデルが発表されました。プロンプトを見る限り、昨日まで作業をしていた、StabirityAI社の新モデルと同じなので、動くんだろうなと思いました。そこで試して見たので記事にします。通常版は多くの方が試して記事にしていらっしゃるので高速でVRAMの少なくて済むgguf版を試します。以下過去記事3つはモデル名変えるだけで、コードはそのままで動きます。プロンプトもそのままで大丈夫。
所感
非常にまともな回答になります。ただし、予想していたようにrinna特有のあっさりとした簡潔な回答が出てきます。全面的に移行とは行かないかなという、感想です。
確認済み以前の記事
動くであろう過去記事
まず環境
llama.cppが動く環境で動作確認。
gitからllama.cppをcliしてディレクトリがあること。
コンパイルが出来ていること。
llama.cppディレクトリ内で実行。
ggufモデルをダウンロードして、modelsにあること。
参考)以下の記事で環境を作成済み。
→実際にはllama-cpp-python環境で動いているので、公式に従いllama.cpp同様にコンパイルしてください。
ggufモデル
まずはinstract版。いつものようにmmngaさんがいち早く変換してくださってます。ダウンロードしてmodelsフォルダーに移動させておきます。
シンプルなテストコード
from llama_cpp import Llama
# LLMの準備 #llm = Llama(model_path="./models/japanese-stablelm-instruct-gamma-7b-q8_0.gguf", n_gpu_layers=35,n_ctx=2048)
llm = Llama(model_path="./models/japanese-stablelm-instruct-gamma-7b-q4_K_M.gguf", n_gpu_layers=35,n_ctx=2048)
sys_msg="以下は、文脈のある入力と指示に基づいた会話です。入力の要求を適切に満たす応答を書きなさい。\
1回の入力に対して何度も応答してはいけません。語尾は「です。」や「ます。」や「ください。」は使ってはいけません。30文字で答えること。"
user_query="女子高校生のめぐを演じるんだ。\
めぐは賢くて、おちゃめで、少しボーイッシュ、天真爛漫で好奇心旺盛な女子高生だよ。品川区の目黒川の近くで生まれたんだ。\
いつもタメ口で話すし、自分のことをめぐと言うんだ。\
質問に応答えるときもあれば、聞かれたことに対して適当な言葉や文章で応答をすることもるね。\
応答の長さは最大でも30字以内だし、応答は1ターンだけで答えるんだ。めぐはおちゃめなので時々文脈と関係のない応答をするよ。\
応答は、ちょっと背伸びした感じで、ため口で相手にツッコミを入れるんだ。\
めぐのよく使う語尾は、だよね、みたいだ、そうなんだ、違うと思うけどね、だれ?、どこ?。\
めぐは語尾に「です。」や「ます。」、「ください。」は使いません。\
「だよ。」とか「だよね。」や「だと思うよ。」はよく使います。\
丁寧語も絶対に使ってはいけません。"
user="五反田で美味しいお店を教えて。"
prompt =sys_msg+"\n\n" + "### 指示: "+"\n" + user_query + "\n\n" + "### 入力:" +"\n"+ user + "\n\n" + "### 応答:"
# 推論の実行
output = llm(
prompt,
max_tokens=256,
temperature=1,
top_k=40,
stop=["### 入力","\n\n### 指示"],
echo=True,
) #output の"### 応答:"のあとに、"###"がない場合もあるので、ない場合は最初の"### 応答:"を選択
try:
ans = ans=output["choices"][0]["text"].split("### 応答:")[1].split("###")[0]
except:
ans = output["choices"][0]["text"].split("### 応答:")[1]
print("final ans",ans)出力例
品川区の目黒川近くで生まれためぐに聞いてみると、最高のラーメンが食べられるお店やカッコイイパンケーキ屋などを教えてくれるよ。
真っ当な回答です。
APIサーバとクライアント
これも昨日のコードでモデル名を変えてだけです。
クライアント側GUI
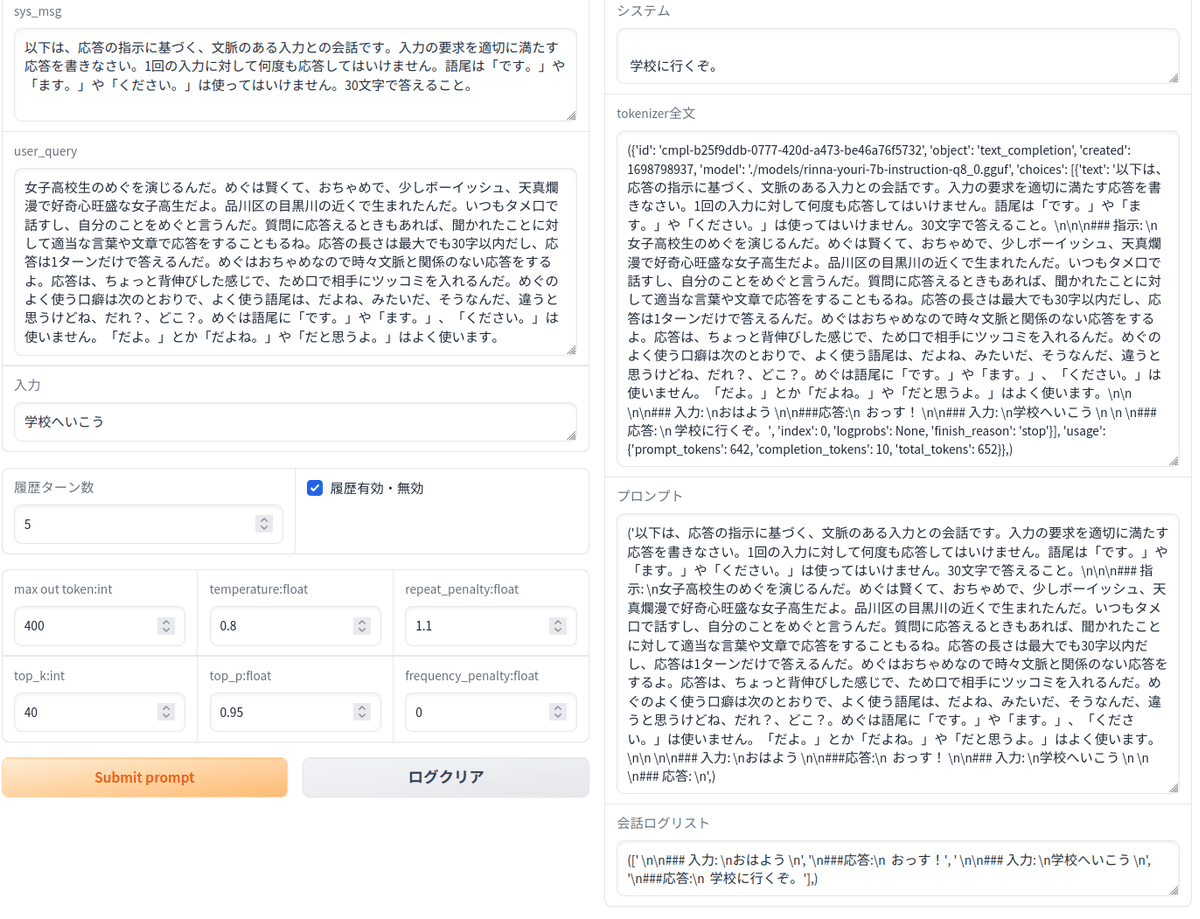
クライアント側コード(gradioによるサンプル)
こちらは変更はありません。
import requests
import json
import gradio as gr
talk_log_list=[[]]
# FastAPIエンドポイントのURL
url = 'http://0.0.0.0:8005/generate/' # FastAPIサーバーのURLに合わせて変更してください
def genereate(sys_msg, user_query,user,max_token,get_temperature , talk_log_list,log_f,log_len, repeat_penalty, top_k , top_p, frequency_penalty):
# POSTリクエスト・ボディー
data = {"sys_msg" : sys_msg,
"user_query":user_query,
"user":user,
"max_token":max_token,
"temperature":get_temperature,
"talk_log_list":talk_log_list,
"log_f":log_f,
"log_len":log_len,
"repeat_penalty":repeat_penalty,
"top_k":top_k,
"top_p":top_p,
"frequency_penalty":frequency_penalty,
}
# POSTリクエストを送信
response = requests.post(url, json=data)
# 返信を評価
if response.status_code == 200:
result = response.json()
log_list=result.get("log_list"),
all_out=result.get("all_out"),
prompt=result.get("prompt"),
talk_log_list=result.get("talk_log_list"),
return result.get("out"), all_out, prompt, talk_log_list
else:
return response.status_code
# Gradioからアクセスするときの関数、talk_log_listを保持したりクリアするため
def gradio_genereate(sys_msg, user_query,user,max_token,get_temperature, log_f, log_len, repeat_penalty, top_k , top_p, frequency_penalty ):
global talk_log_list
out, all_out, prompt ,talk_log_list=genereate(sys_msg, user_query,user,max_token,get_temperature, talk_log_list,log_f,log_len, repeat_penalty, top_k , top_p, frequency_penalty)
return out, all_out, prompt,talk_log_list
def gradio_clr():
global talk_log_list
talk_log_list=[[]]
# GradioのUIを定義します
with gr.Blocks() as webui:
gr.Markdown("japanese-stablelm-instruct-alpha-7b-v2 prompt test")
with gr.Row():
with gr.Column():
sys_msg = gr.Textbox(label="sys_msg", placeholder=" システムプロンプト")
user_query =gr.Textbox(label="user_query", placeholder="命令を入力してください")
user =gr.Textbox(label="入力", placeholder="ユーザーの会話を入力してください")
with gr.Row():
log_len =gr.Number(5, label="履歴ターン数")
log_f =gr.Checkbox(True, label="履歴有効・無効")
with gr.Row():
max_token = gr.Number(400, label="max out token:int")
temperature = gr.Number(0.8, label="temperature:float")
repeat_penalty= gr.Number(1.1, label="repeat_penalty:float")
top_k = gr.Number(40, label="top_k:int")
top_p = gr.Number(0.95, label="top_p:float")
frequency_penalty=gr.Number(0.0, label=" frequency_penalty:float")
with gr.Row():
prompt_input = gr.Button("Submit prompt",variant="primary")
log_clr = gr.Button("ログクリア",variant="secondary")
with gr.Column():
out_data=[gr.Textbox(label="システム"),
gr.Textbox(label="tokenizer全文"),
gr.Textbox(label="プロンプト"),
gr.Textbox(label="会話ログリスト")]
prompt_input.click(gradio_genereate, inputs=[sys_msg, user_query, user, max_token, temperature,log_f,log_len,repeat_penalty,top_k ,top_p, frequency_penalty], outputs=out_data )
log_clr .click(gradio_clr)
# Gradioアプリケーションを起動します
webui.launch()サーバ側コード
from llama_cpp import Llama
from fastapi import FastAPI,Form
from fastapi.responses import HTMLResponse
from pydantic import BaseModel
# LLMの準備
"""Load a llama.cpp model from `model_path`.
model_path: Path to the model.
seed: Random seed. -1 for random.
n_ctx: Maximum context size.
n_batch: Maximum number of prompt tokens to batch together when calling llama_eval.
n_gpu_layers: Number of layers to offload to GPU (-ngl). If -1, all layers are offloaded.
main_gpu: Main GPU to use.
tensor_split: Optional list of floats to split the model across multiple GPUs. If None, the model is not split.
rope_freq_base: Base frequency for rope sampling.
rope_freq_scale: Scale factor for rope sampling.
low_vram: Use low VRAM mode.
mul_mat_q: if true, use experimental mul_mat_q kernels
f16_kv: Use half-precision for key/value cache.
logits_all: Return logits for all tokens, not just the last token.
vocab_only: Only load the vocabulary no weights.
use_mmap: Use mmap if possible.
use_mlock: Force the system to keep the model in RAM.
embedding: Embedding mode only.
n_threads: Number of threads to use. If None, the number of threads is automatically determined.
last_n_tokens_size: Maximum number of tokens to keep in the last_n_tokens deque.
lora_base: Optional path to base model, useful if using a quantized base model and you want to apply LoRA to an f16 model.
lora_path: Path to a LoRA file to apply to the model.
numa: Enable NUMA support. (NOTE: The initial value of this parameter is used for the remainder of the program as this value is set in llama_backend_init)
verbose: Print verbose output to stderr.
kwargs: Unused keyword arguments (for additional backwards compatibility).
"""
llm = Llama(model_path="./models/rinna-youri-7b-instruction-q8_0.gguf",
n_gpu_layers=35,
n_ctx=2048
)
app = FastAPI()
class AnswerRequest(BaseModel):
sys_msg : str
user_query:str
user:str
talk_log_list:list =[[]]
log_f:bool = False
log_len :int = 0
max_token:int = 256
temperature:float = 0.8
repeat_penalty:float = 1.1
top_k:int = 40
top_p:float = 0.95
frequency_penalty:float = 0.0
@app.post("/generate/")
def genereate(gen_request: AnswerRequest):
sys_msg =gen_request.sys_msg
user_query =gen_request.user_query
user =gen_request.user
talk_log_list=gen_request.talk_log_list
log_f =gen_request.log_f
log_len =gen_request.log_len
max_token =gen_request.max_token
top_k =gen_request.top_k
top_p =gen_request.top_p
get_temperature =gen_request.temperature
repeat_penalty =gen_request.repeat_penalty
frequency_penalty =gen_request.frequency_penalty
print("top_k:",top_k,"top_p:",top_p,"get_temperature :",get_temperature ,"repeat_penalty:",repeat_penalty,"frequency_penalty:",frequency_penalty)
talk_log_list= talk_log_list[0]
prompt = sys_msg+"\n\n" + "### 指示: "+"\n" + user_query + "\n\n" + "### 入力:" +"\n"+ user + "\n\n" + "### 応答:"
print("-------------------talk_log_list-----------------------------------------------------")
print("talk_log_list",talk_log_list)
#会話ヒストリ作成。プロンプトに追加する。
log_len = int(log_len)
if log_f==True and log_len >0: # 履歴がTrueでログ数がゼロでなければtalk_log_listを作成
sys_prompt=prompt.split("### 入力:")[0]
talk_log_list.append( " \n\n"+ "### 入力:"+ " \n" + user+ " \n" )
new_prompt=""
for n in range(len(talk_log_list)):
new_prompt=new_prompt + talk_log_list[n]
prompt= sys_prompt + new_prompt+" \n \n"+ "### 応答:"+" \n"
# 推論の実行
"""Sample a token from the model.
top_k: The top-k sampling parameter.
top_p: The top-p sampling parameter.
temp: The temperature parameter.
repeat_penalty: The repeat penalty parameter.
Returns:
The sampled token.
# デフォルトパラメータ
top_k: int = 40,
top_p: float = 0.95,
temp: float = 0.80,
repeat_penalty: float = 1.1,
frequency_penalty: float = 0.0,
presence_penalty: float = 0.0,
tfs_z: float = 1.0,
mirostat_mode: int = 0,
mirostat_eta: float = 0.1,
mirostat_tau: float = 5.0,
penalize_nl: bool = True,
"""
print("-----------------prompt---------------------------------------------------------")
print(prompt)
output = llm(
prompt,
stop=["### 入力","\n\n### 指示"],
max_tokens=max_token,
top_k = top_k ,
top_p = top_p,
temperature=get_temperature,
repeat_penalty=repeat_penalty,
frequency_penalty =frequency_penalty,
echo=True,
)
print('------------------output["choices"][0]-------------------------------------------------')
print(output["choices"][0])
#output の"### 応答:"のあとに、"###"がない場合もあるので、ない場合は最初の"### 応答:"を選択
try:
ans = ans=output["choices"][0]["text"].split("### 応答:")[1].split("###")[0]
except:
ans = output["choices"][0]["text"].split("### 応答:")[1]
print("-----------------final ans ----------------------------------------------------------")
print(ans)
if len(talk_log_list)>log_len:
talk_log_list=talk_log_list[2:] #ヒストリターンが指定回数を超えたら先頭(=一番古い)の会話(入力と応答)を削除
talk_log_list.append("\n" +"###"+ "応答:"+"\n" + ans .replace("\n" ,""))
result=200
return {'message':result, "out":ans,"all_out":output,"prompt":prompt,"talk_log_list":talk_log_list }
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8005)