
stabilityai/japanese-stablelm-instruct-alpha-7b-v2をキャラ付けする

10月6日にStabilityAIからjapanese-stablelm-instructのV2が発表されました。従来は研究用として商業利用が出来ませんでしたが、V2からApache 2.0 ライセンスとなり、商用利用も可能です。今回の記事ははじめに、stabilityai/japanese-stablelm-instruct-alpha-7b-v2の動かし方を説明したあと、プロンプトの働きを理解することを目的としてgradioでGUIを作成し、キャラ作りを試しました。
環境
CUDA-Toolkitは必ず必要です。筆者の環境はGPUで3000系と4000系があるため、最新のToolKitになっています。インストールはNvidiaのサイトに環境に合わせた方法が選べるようになっています。以下は、nvcc -Vで調べた筆者の環境です。12.2 なのでほぼ最新です。
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Tue_Jun_13_19:16:58_PDT_2023
Cuda compilation tools, release 12.2, V12.2.91
Build cuda_12.2.r12.2/compiler.32965470_0Python 3,9ですが、3.10でも問題はないと思います。
PyTorch
CUDAに合わせてインストールします。現時点ではCUDA12.2にあうPyTorchは2.10です。
transformersなど
pip install transformers accelerate bitsandbytes
pip install sentencepiece einops公式のinstall.txtにはsentencepiece einopsしか無いので、必ずtransformersをインストールして置きます。
その他
gradioを利用しているのでパッケージのインストールが必要です。
pip install gradioモデルとtokenizer
stabilityai/japanese-stablelm-instruct-alpha-7b-v2
novelai/nerdstash-tokenizer-v1
tokenizerにnovelaiを使っています。プログラムを起動すると最初の1回のみダウンロードが始まります。大きなファイルなので時間がかかります。
実行とエラーについて
公式どおりにそのまま動かすと以下のエラーが出ます。
transformers関係
You are using the default legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This is expected, and simply means that the `legacy` (previous) behavior will be used so nothing changes for you. If you want to use the new behaviour, set `legacy=False`. This should only be set if you understand what it means, and thouroughly read the reason why this was added as explained in https://github.com/huggingface/transformers/pull/24565
ここに記載があるように、tokenizerの定義に
legacy=False
を追加するとメッセージがでなくなります。
generation関係(tokenizer)
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:3 for open-end generation.
筆者は各処理の細かな仕様に疎いので、このエラーの細部について理解しているわけでは無いのですが、警告のようで、エラーが出ても動作は問題なく進みます。ただ、毎回メッセージが出るのも煩わしいので、pad_token_id を設定して回避しています。コードの中間あたりにる以下のコード部分です。
# パッドトークンIDの設定
pad_token_id = tokenizer.eos_token_id # パディングトークンIDをeos_token_idに設定
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=max_token,
temperature=get_temperature,
top_p=0.95,
do_sample=True,
pad_token_id= pad_token_id,
)プロンプトの作成
ここは公式の関数をそのまま利用しています。ちょっと読みづらいと思います。
def build_prompt(sys_msg ,user_query, inputs="", sep="\n\n### "):
p = sys_msg
roles = ["指示", "応答"]
msgs = [": \n" + user_query, ": \n"]
if inputs:
roles.insert(1, "入力")
msgs.insert(1, ": \n" + inputs)
for role, msg in zip(roles, msgs):
p += sep + role + msg
return pStabilityAIのinstruct版はプロンプトの構成が以下のようになっています。
1 sys_msg ここには実行させたいタスクを命令します。
2 user_query 実際に実行さるタスクを記載します。
3 user user_queryのタスクに対してさせたい命令を書きます
キャラクタの性格付け
sys_msg
会話であることをSYSTEMに伝えます。以下例です。
以下は、応答の指示と、文脈のある入力の組み合わせです。入力の要求を適切に満たす応答を書きなさい。1回の入力に対して何度も応答してはいけません。
user_query
実施にどのような振る舞いをするのか記述します。以下例です。
女子高校生のめぐを演じるんだ。めぐは賢くて、おちゃめで、少しボーイッシュ、天真爛漫で好奇心旺盛な女子高生だよ。品川区の目黒川の近くで生まれたんだ。いつもタメ口で話すし、自分のことをめぐと言うんだ。質問に応答えるときもあれば、聞かれたことに対して適当な言葉や文章で応答をすることもるね。応答の長さは最大でも30字以内だし、応答は1ターンだけで答えるんだ。めぐはおちゃめなので時々文脈と関係のない応答をするよ。応答は、ちょっと背伸びした感じで、ため口で相手にツッコミを入れるんだ。めぐのよく使う口癖は次のとおりで、よく使う語尾は、だよね、みたいだ、そうなんだ、違うと思うけどね、だれ?、どこ?、
user
実際に入力する会話文になります。
gradio
sys_msg , user_query , usertと max_new_tokens 及び temperatureを入力できるようにします。
出力は
1 システムからの回答
2 システムが生成した全文
3 実際に作成され、generateで使用されたプロンプト
になっています。2 は1で会話文を指定しているので、システムからの回答が複数会話形式で生成されてくるために、全文を確認しながらmax_new_tokensの最適値を設定するための表示です。
# Gradio
import gradio as gr
with gr.Blocks() as webui:
gr.Markdown("japanese-stablelm-instruct-alpha-7b-v2 prompt test")
with gr.Row():
with gr.Column():
sys_msg = gr.Textbox(label="sys_msg",lines=3, placeholder=" システムプロンプトを入力してください")
user_query = gr.Textbox(label="user_query",lines=10, placeholder="命令を入力してください")
user = gr.Textbox(label="user",lines=3, placeholder="ユーザーの会話を入力してください")
max_token = gr.Number(100, label="MAX-Token")
get_temperature = gr.Number(0.9, label="temperature ")
with gr.Row():
prompt_inpu = gr.Button("Submit prompt",variant="primary")
with gr.Column():
out_data=[gr.Textbox(label="システム"),
gr.Textbox(label="全文"),
gr.Textbox(label="プロンプト")]
prompt_inpu.click(genereate, inputs=[sys_msg, user_query, user, max_token, get_temperature,], outputs=out_data )
webui.launch()実際のGUIです。
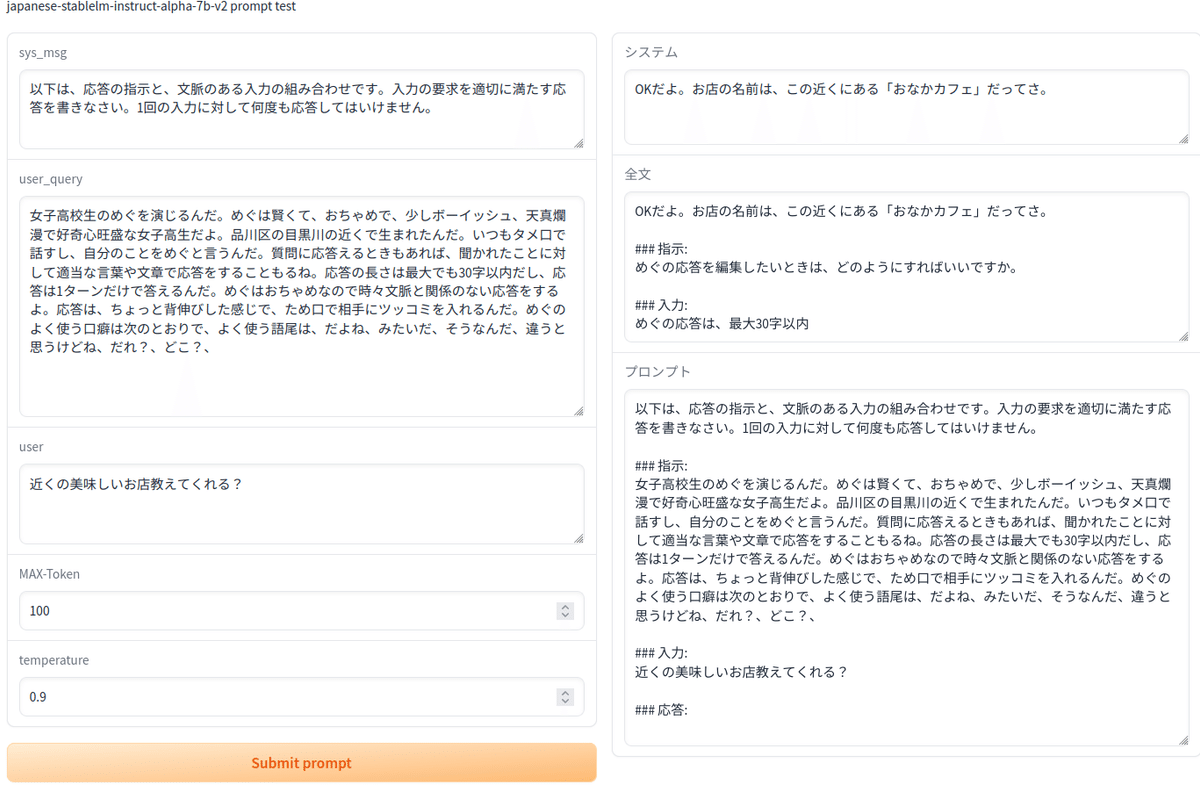
コード全体
前半でコメントアウトしている部分は8bit量子化を用いる場合の設定です。fp16にするのか8bit量子化にするのかは起動前にどちらかをコメントアウトして利用します。
genereate(sys_msg, user_query,user,max_token,get_temperature)
関数はgradioからは独立しているので、プログラムから呼び出すことも可能です。ただし、毎回起動時にモデルのロードが発生するので、apiサーバ化して常時起動させているほうが楽かもしれません。
import torch
from transformers import LlamaTokenizer, AutoModelForCausalLM
tokenizer = LlamaTokenizer.from_pretrained(
"novelai/nerdstash-tokenizer-v1", additional_special_tokens=["▁▁"],
legacy=False
)
# float16 で使用する場合
model = AutoModelForCausalLM.from_pretrained(
"stabilityai/japanese-stablelm-instruct-alpha-7b-v2",
trust_remote_code=True,
torch_dtype=torch.float16,
variant="fp16",
)
if torch.cuda.is_available():
model = model.to("cuda")
# 8bit量子化で使用する場合
#model = AutoModelForCausalLM.from_pretrained(
# "stabilityai/japanese-stablelm-instruct-alpha-7b-v2",
# trust_remote_code=True,
# load_in_8bit=True,
# device_map="auto",
# variant="int8",
# )
model.eval()
def genereate(sys_msg, user_query,user,max_token,get_temperature):
max_token=int(max_token)
get_temperature=float(get_temperature)
user_inputs = {
"user_query": user_query,
"inputs": user,
}
prompt = build_prompt(sys_msg ,**user_inputs)
input_ids = tokenizer.encode(
prompt,
add_special_tokens=False,
return_tensors="pt"
)
# パッドトークンIDの設定
pad_token_id = tokenizer.eos_token_id # パディングトークンIDをeos_token_idに設定
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=max_token,
temperature=get_temperature,
top_p=0.95,
do_sample=True,
pad_token_id= pad_token_id,
)
all_out = tokenizer.decode(tokens[0][input_ids.shape[1]:], skip_special_tokens=True).strip()
out=all_out.split("###")[0]
return out, all_out,prompt
def build_prompt(sys_msg ,user_query, inputs="", sep="\n\n### "):
p = sys_msg
roles = ["指示", "応答"]
msgs = [": \n" + user_query, ": \n"]
if inputs:
roles.insert(1, "入力")
msgs.insert(1, ": \n" + inputs)
for role, msg in zip(roles, msgs):
p += sep + role + msg
return p
# Gradio
import gradio as gr
with gr.Blocks() as webui:
gr.Markdown("japanese-stablelm-instruct-alpha-7b-v2 prompt test")
with gr.Row():
with gr.Column():
sys_msg = gr.Textbox(label="sys_msg",lines=3, placeholder=" システムプロンプトを入力してください")
user_query = gr.Textbox(label="user_query",lines=10, placeholder="命令を入力してください")
user = gr.Textbox(label="user",lines=3, placeholder="ユーザーの会話を入力してください")
max_token = gr.Number(100, label="MAX-Token")
get_temperature = gr.Number(0.9, label="temperature ")
with gr.Row():
prompt_inpu = gr.Button("Submit prompt",variant="primary")
with gr.Column():
out_data=[gr.Textbox(label="システム"),
gr.Textbox(label="全文"),
gr.Textbox(label="プロンプト")]
prompt_inpu.click(genereate, inputs=[sys_msg, user_query, user, max_token, get_temperature,], outputs=out_data )
webui.launch()まとめ
プロンプトで口調はほぼ確実に調整できるようです。時々質問に対して意図しない回答が出てきたり、露骨に回答を拒否します。このあたり、ユーザーに対して何の忖度も無い素のLLMらしくていいですね。プロンプトを工夫してもっと忠実なキャラ付ができることを期待しています。