
最強の自動プロンプトはどれ? TIPO・Cliption・Florence-2 を徹底比較!

はじめに
こんにちは、きまま / Easygoing です。
今回も前回に引き続き、画像生成のプロンプトを自動で作る方法を考えます。
キーワード VS 画像
前回、自動でプロンプトを作る方法には、キーワードと画像を使う2種類の方法があることをご紹介しました。
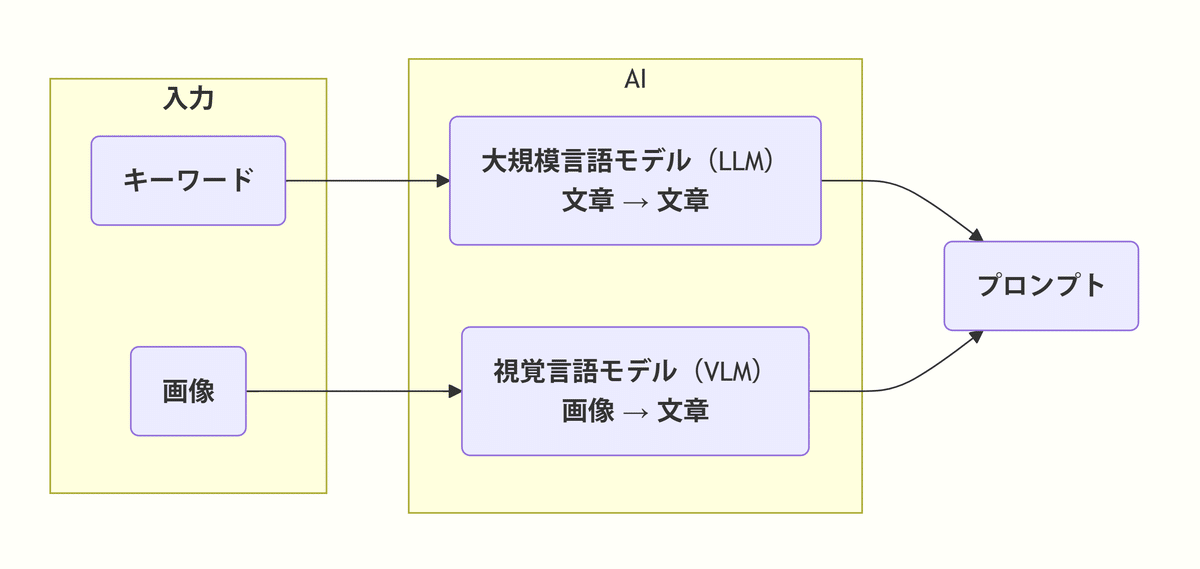
前回は高性能で万能な ChatGPT を使いましたが、今回はローカルで使える LLM と VLM を探してみます。
キーワードからプロンプトを作る
キーワードからプロンプトを作る場合、使用するのは LLM(大規模言語モデル)と呼ばれる AI モデルです。
大規模言語モデル:LLM(文章 → 文章)

ローカルで利用できる LLM として最も普及しているのが LLaMA で、オープンソース(正確にはオープンウェイト)で公開されているので様々なパラメータ数のモデルが存在しています。
プロンプトを作る専用の LLaMA モデル!
LLaMA の中には、軽量の LLaMA モデルに対して専用の追加学習を行い、画像生成のプロンプトの作成に特化したモデルがあります。
その中で、一番有名なのが TIPO だと思います。
TIPO:Text to Image with text presampling for Prompt Optimization
プロンプト最適化のための、テキスト事前サンプリングを用いたテキストから画像への生成
TIPO は ComfyUI のカスタムノードで使えるほか、Stable Diffysion webUI(A1111, Forge, Reforge)でも導入できる拡張機能も公開されています。
TIPO はアニメイラストに強い!
TIPO は、LLaMA の 500M もしくは 200M パラメータの軽量モデルに対して、画像とテキストのデータセットで学習を行い、画像のテキストの特徴 を理解しています。
TIPO は次のデータセットで学習しています。
Danbooru2023(500万枚以上、タグ、アニメイラスト)
GBC10M(約1000万枚、自然言語、実写系)
CoyoHD11M(約1100万枚、自然言語、実写系)
TIPO は実写系のイラストからも学習していますが、その最大の特徴は多くの アニメイラスト を学習していることです。
TIPO を使ってみる!
それでは、実際に TIPO を使って画像を生成してみます。
キーワードは前回と同じ インコ と 人懐こい を指定して、自然言語のプロンプトで8枚連続で生成します。
設定
Temperature: 0.3
Top-p: 0.3
Top-k: 5


TIPO の出力は、バリエーション に富んでいます。
一方で、キーワードとして入力した インコ と 人なつこい の要素は、鳥型の生き物にいくらか反映されるに留まっています。
今回は、アニメ関連のキーワードは入力していませんが、生成されるプロンプトの多くはアニメイラストのプロンプトになっていて、やはり TIPO は アニメイラストの出力 に特化 したモデルと言えそうです。
画像からプロンプトを作る!
次は、画像からプロンプトを作ってみます。
画像からプロンプトを作るときは、テキストに加えて画像も理解できる 視覚言語モデル を利用します。
視覚言語モデル(VLM:Vision Language Model)

視覚言語モデルの中で、軽量でローカルの PC でも使いやすいのが、CLIP-L と Florence-2 です。
以前に紹介した Cliption は、CLIP-L を利用して画像からテキストを生成するAI モデル でした。
CLIP-L は 学習のデータセットが大きい ですが、文章の理解力はあまり高くありません。
それに対して、2024年6月に Microsoft から公開された Florence-2 は、CLIP-L と同じぐらい軽量でありながら、高品質で詳細にキャプション されたデータセットで学習していて、高い分析力と理解力を持っています。
実際のキャプション!
それでは、実際に CLIP-L と Florence-2 で画像にキャプションをつけて比較してみましょう。
比較する画像は、こちらの黒髪の女性とインコが映ったアニメイラストです。
比較画像

CLIP-L(LongCLIP-SAE-ViT-L-14)
a young girl with blue hair holds a colorful parrot in a lush, sunlit garden with pink and purple flowers, surrounded by a wooden fence, trees, flowers, and a bench, and a small house in the background, with warm sunlight filtering through the leaves and a serene and a peaceful atmosphere. the woman wears a light - colored blouse and blue overalls with a brown
LongCLIP-SAE-ViT-L-14 モデルは、今までに何度か紹介している改良型の CLIP-L モデル です。
CLIP-L は、要点を捉えた 50語程度 のキャプションになっています。
ここから、生成した キャプション を プロンプトに投入 することを繰り返して、連続で8枚画像を生成してみます。
Cliption のキャプションは、それほど厳密ではないため、生成するにつれて イラストが少しずつ変化 していきます。


インコは少しずつ変化して くまのぬいぐるみ になり、アニメの女の子は 実写の女性 に変わっていきました。
Cliption を利用して生成を続けると、最後は実写の女性のイラストに収束していく傾向があり、おそらく学習元のデータセットにそのような写真が多かったのだろうと考えられます。
Florence-2(Florence-2-large-PromptGen v2.0)
今度は、 Florence-2 のキャプションを見てみます。
今回利用する Florence-2-large-PromptGen v2.0 モデルは、オリジナルの Florence-2 に対して Civitai にアップロードされたイラストで追加学習を行い、画像の認識能力を高めたモデルです。
Florence-2 は、① 自然言語、② タグ、③ 分析 の3つのキャプションの出力を行うことができ、それぞれ用途に合わせて利用することができます。

① 自然言語
A vibrant and detailed anime-style digital illustration from a front camera angle about a girl holding a parrot in a lush garden. the image features a young girl with long, black hair and golden eyes, standing in the middle of the image. she is wearing a blue overalls and a beige hoodie, with a warm and inviting expression on her face. the girl is holding a blue and green parrot close to her chest, with its beak slightly open and its eyes looking directly at the viewer. the background is filled with lush greenery, pink flowers, and a wooden fence, creating a serene and peaceful atmosphere. the lighting is soft and warm, casting gentle shadows on the girl's face and the parrot's feathers. the overall style is reminiscent of japanese anime, with detailed shading and vibrant colors that bring the scene to life.
② タグ
1girl, solo, long hair, looking at viewer, blush, smile, open mouth, black hair, long sleeves, holding, closed mouth, yellow eyes, upper body, flower, outdoors, open clothes, day, hair between eyes, tree, hood, animal, hoodie, pink flower, holding animal, bird, nature, forest, blue overalls, holding bird, parrot
③ 分析
camera_angle: from front, art_style: digital illustration, location: outdoor garden, background: lush greenery with flowers and trees, text: NA, image_composition: middle, clothing: blue overalls, beige long-sleeved shirt, distance_to_camera: upper body, hair_color: black hair, facial_expression: smile, action: holding a parrot, accessory: NA;NA, pants: overalls
Florence-2 のキャプションは、いずれも 詳細で分析的なキャプション になっています。
Florence-2 のキャプションは非常に正確なので、画像を image to image で加工する場合 などで大きな効果を発揮します。
それでは、先ほどと同じようにキャプションをプロンプトに投入して、連続でイラストを生成します。


Florence-2 は、先ほどの CLIP-L とは違ってキャプションが正確なため、オリジナルの特徴が そのまま維持 されたイラストが生成されていきます。
産業分野などでの画像認識の応用 を考えた場合には、このような正確なキャプションを行う能力は非常に重要な意味を持っています。
3つの自動プロンプトを比較!
それでは、今回紹介した3つの自動プロンプトの生成方法を比較します。

同じ自動プロンプト入力でも、今回紹介した TIPO・Cliption・Florece-2 はそれぞれ違った特徴を持っています。
なお、今回は生成したプロンプトをそのまま投入しましたが、実際には 特定のキーワードを追加したり消去 して使うことで、いずれの方法でももっと柔軟に使うことができます。
TIPO と Florence-2 のインストール方法
最後に、TIPO と Florence-2 のインストール方法を、ComfyUI Manager のスクリーンショットで簡単にご紹介します。
TIPO
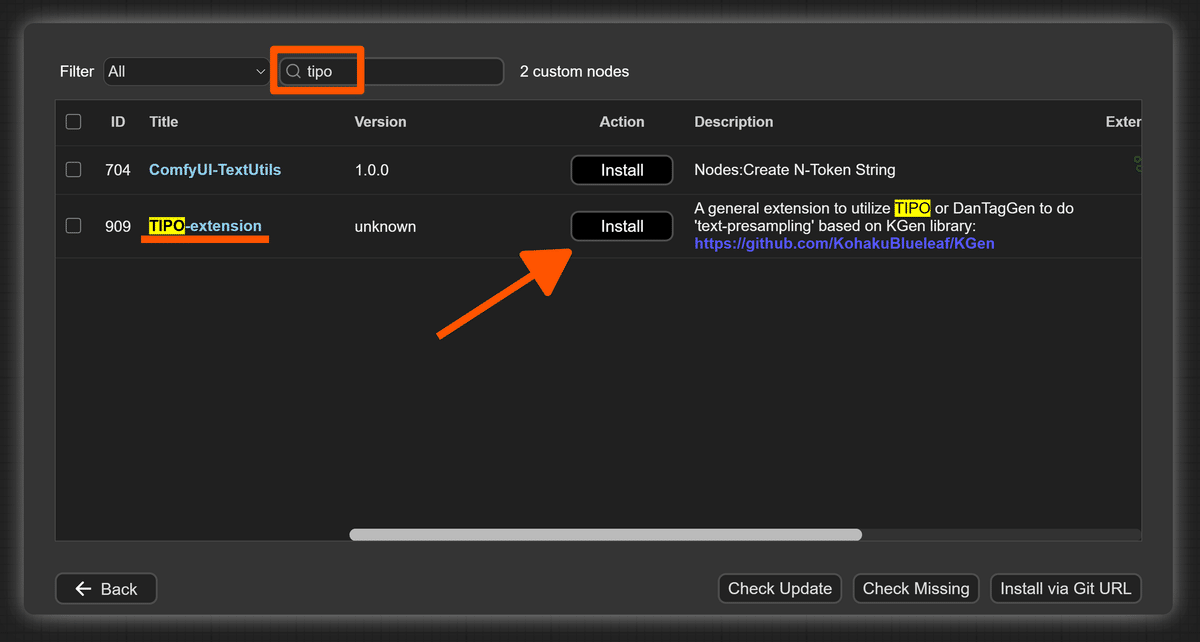
TIPO の使用方法については、公式のドキュメント を参考にしてください。
ComfyUI-Florence2


Comfyui-Florence2 カスタムノードを利用するときは、同時に comfyui-tensorop カスタムノードのインストールも必要です。
Florence-2 の使い方は、また次回の記事で取り上げたいと思います。
なお、Cliption のインストール方法については、以前の記事をご参照ください。
まとめ:AI には個性がある!
TIPO はアニメイラストに強い
CLIP-L は表現の幅が広い
Florence-2 は正確な分析
今回は、3つの自動プロンプトの作成方法を比較しました。
自動プロンプトは、AI を利用してさまざまなバリエーションを作り出していますが、そのバリエーションもまた、AI が学習した データセットの影響 を受けています。
私は普段、実写に近いアニメイラストを生成していますが、実写寄りのアートについては、学習枚数の多い CLIP-L が 表現の幅が広い と感じました。

画像生成で、アートの表現力が高い IP-Adapter はキャプションモデルとして CLIP(CLIP-L, CLIP-H, CLIP-G)を利用していて、CLIP にはまだまだ活躍の場があると感じます。
これからも、様々な AI と触れ合いながら、その得意な表現を探していきたいと思います。
最後までお読みいただきありがとうございます!