
【画像生成AI】 Flux.1 の圧縮形式を徹底比較! その違いは構図力!

謹賀新年
あけましておめでとうございます! 今年もよろしくお願いします!
お題:初詣
さて、今回のお題は初詣です。

正月休みも終わりですが、新年初めての投稿なのでこのお題でいってみます!
モデルの圧縮は画質に影響する?
前回は、テキストエンコーダーをアップグレードして、イラストのクオリティーを上げる方法を調べました。
今回は、画像を生成する本体のトランスフォーマー部分で、圧縮形式が画質にどのように影響するのか検証します。

実際の比較
まずは、実際のイラストを比較してみます。
FP16 (16 bit)

最初はオリジナルの FP16 形式です。FP16 形式は非常にクリアーなイラストです。
次から比較する右側の黒い画像は、この FP16 形式 と比べたときのカラーの差分マップになります。
Q8_0.gguf (8 bit)

Q8_0.gguf は 8 bit の GGUF 形式です。容量は先ほどの FP16 形式と比べて半分になります。
見た目ではあまり違いが無いように感じますが、差分マップを見ると所々が変わっているのが分かります。
Q5_K_M.gguf (5 bit)

続いて、5bit の GGUF 形式です。
Q8_0 より 全体の構図が単純 になっています。灯籠が大きくなり、小さな人物が省略 されているのが分かります。
FP8e4m3 (8 bit)

今度は、 8 bit の FP8e4m3 形式です。
奥の門が単純になり、構図が単純化して 左右対称のイラスト になっています。
Q4_K_M.gguf

次は、Q4_K_M.gguf 形式です。門が単純化されて鳥居になりました。
Q2_K.gguf

最後は 2bit の Q2_K.gguf です。
非常に単純な構図になり、中央の人物も省略されてしまってます。
結果のグラフ


今回の検証結果です。ベースモデルもテキストエンコーダーと同じように、圧縮が進むにつれて画質が低下していきます。
個別の形式を見ると、FP8e4m3 形式 は同じ 8 bit の Q8_0.gguf 形式 より精度が大きく劣っています。
FP8e4m3 形式の精度は Q4_K_M 形式に近く、やはり FP8 形式 よりも GGUF 形式 が容量と精度のバランスに優れていることが分かります。
構図が変わってくる!
今回の比較で明らかになったのが、トランスフォーマー部分を圧縮すると 構図が単純になっていく 点です。
圧縮が進むにつれて 小さな人物が省略 されるようになり、また 構図も左右対称 に近づいていきす。

前回は、テキストエンコーダーの違いは主にディティールの表現に現れましたが、トランスフォーマーはより大きな視点で イラスト全体 に影響を与えるようです。
圧縮したモデルで全体が左右対称になる理由はよく分かりませんが、アシンメトリー(左右非対称)は AI にとってイレギュラーな表現なので、その計算には高い精度が必要になるのかもしれません。
ベースモデル と テキストエンコーダ のどちらを優先する?
それでは、今回の結果を前回のテキストエンコーダーの結果と並べて比較してみます。


両者を比べると、下のグラフの ベースモデル(トランスフォーマー)の方が、圧縮が進むにつれて劣化が大きい ことが分かります。
ベースモデルとテキストエンコーダーのどちらかを優先する場合、まずはベースモデルを優先するのが良いでしょう。
VAE は画質に影響するか?
ベースモデルとテキストエンコーダーに続いて、最後は VAE を比較してみます。
ComfyUI・Stable Diffusion webUI Forge ともに、VAE は通常は BF16 形式 で処理されています。
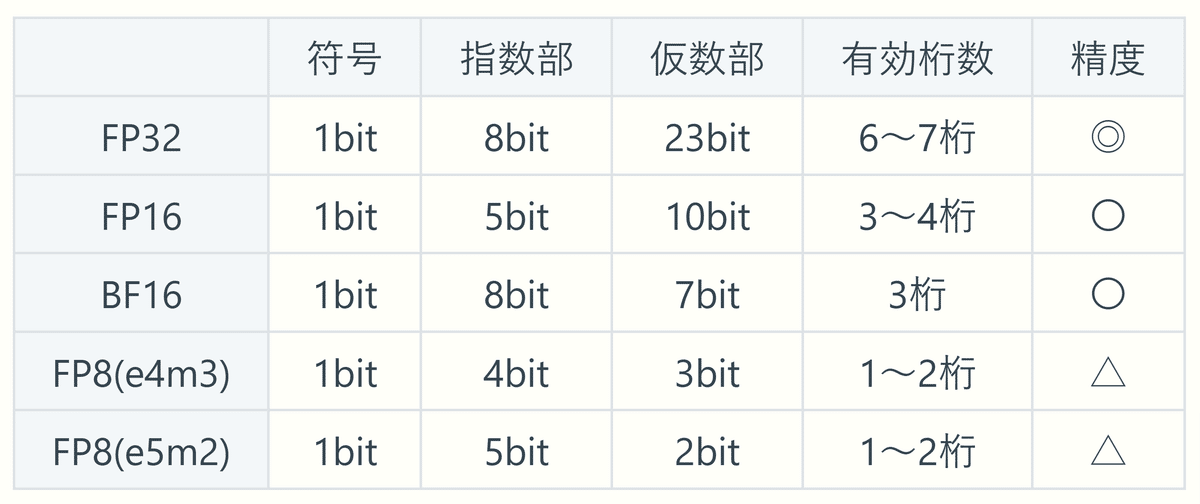
今回は、これをより精度の高い FP32 形式と比べてみます。

FP32 形式 と BF16 形式 を比較すると、生成されたイラストの MAE 及び SSIM はほぼ完全に一致していて、差がないことを示しています。
VAE は、デフォルトの BF16 形式 で問題ないでしょう。
モデルを分離する!
Flux.1 のモデルは、テキストエンコーダーとトランスフォーマーが結合したものが多く配布されています。
前回紹介した Flan-T5xxl と 改良型 CLIP-L を使う場合、トランスフォーマー部分を分離して利用した方が容量の節約になります。
ComfyUI では、次の方法でトランスフォーマー部分を簡単に分離することができます。

ModelSave ノードを分離したいモデルに接続して、実行すれば OK です!
ベースモデルとテキストエンコーダーは両立する!
画像生成AI のトランスフォーマーは 非常に重い計算 が必要なので、通常は VRAM を利用して演算を行います。
一方で、ComfyUI ではテキストエンコーダーは、条件によってロードする場所が変わってきます。
テキストエンコーダーを VARM にロードする場合
VRAM が RAM の 0.5倍 以上空いている
かつ VRAM がモデルの容量の 1.2倍以上空いている
Flux.1 では、テキストエンコーダーの容量が大きいので、ほぼ例外なく演算は VRAM ではなく RAM を利用 して行われます。
つまり、十分な容量の RAM を増設すれば、テキストエンコーダーとトランスフォーマーは競合することなく演算を実行することができます。

RAM は GPU と比べると比較的増設が容易なので、画質を改善したいときは RAM の増設も検討してみてもよいでしょう。
まとめ:まずはベースモデル!
ベースモデルの精度は構図に出る
まず VRAM の容量に合わせてベースモデルを選ぶ
次に、RAM に応じてテキストエンコーダーを選択する
Flux.1 は、ベースモデルとテキストエンコーダーを別々に利用するため、その選択に悩む場面も多かったですが、今回の比較でそれなりに整理することができました。

高画質の追求に終わりはありませんが、ベストな出力を求めてセッティングを細かく調整できるのは、ローカル画像生成の魅力 の一つです。
みなさんも、納得の一枚を求めてセッティング詰めてみてはいかがでしょうか?
最後までお読みいただきありがとうございます!