
【画像生成AI】 CLIP と T5xxl って何? テキストエンコーダーでイラストがこんなに綺麗になる!

はじめに
こんにちは、きまま / Easygoing です。
今日は 画像生成AI のテキストエンコーダーについて考えます。
テキストエンコーダーは辞書
AI は、私たち入力したテキストを、機械が分かる形に変えて理解しています。

この翻訳をするのがテキストエンコーダーで、その働きは 人間語を機械語に翻訳する辞書 にあたります。
画像生成AI でテキストエンコーダーを変更すると、画質はどのように変わるのでしょうか?
実際の画像を比較!
それでは、新しい 画像生成AI の Flux.1 で実際に画像がどのように変わるかを見てみます。
Flux.1 には、2種類のテキストエンコーダーが搭載されています。

T5xxl:プロンプトの文脈を理解
CLIP-L:単語をベクトルに変換
今回は、この T5xxl と CLIP-L をより精度の高いものに変えてみます。
T5xxl-FP16 + CLIP-L-FP16(オリジナル)

Flan-T5xxl-FP16 + CLIP-L-FP16

Flan-T5xxl-FP32 + CLIP-L-FP32

Flan-T5xxl-FP32 + CLIP-GmP-ViT-L-14-FP32

Flan-T5xxl-FP32 + Long-CLIP-GmP-ViT-L-14-FP32

今回利用したしたテキストエンコーダーは、下にあるものほど性能が良くなります。
テキストエンコーダーを変えると、特に 右側の建物のディティール が細かくなり、画質が向上しているのが分かります。
なお、一番下の Long-Clip-L モデルは ComfyUI で利用できますが、Stable Diffusion webUI Forge では利用することはできません。
また、FP32 形式のテキストエンコーダーを使うには、後述の --fp32-text-enc 設定が必要です。
テキストエンコーダーを詳しく見ていこう
それでは、テキストエンコーダーをもう少し詳しく見ていきます。
まず、主な画像生成AI に搭載されているテキストエンコーダーは次のようになります。

T5xxl と CLIP がテキストエンコーダーで、 UNET と Transformer は解析した情報をもとに画像を生成する部分です。
CLIP はすべての基本
CLIP は OpenAI が開発した画像とテキストを関連付ける基本的な手法です。
CLIP には、性能に応じて次の種類があります。

画像生成AI の基本学習データベースは、5億枚の画像データセットの LAION-5B ですが、LAION-5B は CLIP-B で画像のキャプション付けがされています。
CLIP-L は CLIP-B の性能向上型で、ほとんどの画像生成AI は CLIP-L を搭載 しています。
Long-CLIP-L は CILP-L を長文も理解できるように改良したモデルです。
CLIP-G は CLIP-L の全般の性能を向上させたモデルで、トークン数は変わらないものの、重要な要素を強調して再現することにより 200語以上の長文プロンプト も理解できるようになりました。
T5xxl は文脈を理解する
T5xxl は Google が開発したテキストからテキストを生成するモデルで、AIチャット や 翻訳AI など、今日の AIサービスの基本技術になっています。
T5xxl は理論上は非常に長い文章を扱うことができますが、長文になるにつれて精度は低下 します。

T5xxl v1.1 と Flan-T5xxl はパラメーター数は変化していませんが、効率的な追加学習を行ったことにより全体の精度が上がっています。
テキストエンコーダーは増えている
新しい 画像生成AI は、プロンプトの理解の精度を上げるために、複数のテキストエンコーダーが搭載されるようになっています。
Stable Diffusuin 1:単語で理解

2022年7月に登場した Stable Diffusion 1 は、テキストエンコーダーとして CLIP-L を使用していました。
CLIP-L は理解できるトークン数が少なかったので、プロンプトは 単語で区切って短く書く、また 重要なキーワードは最初に書く などの工夫が必要でした。
Stable Diffusion XL:長文を理解
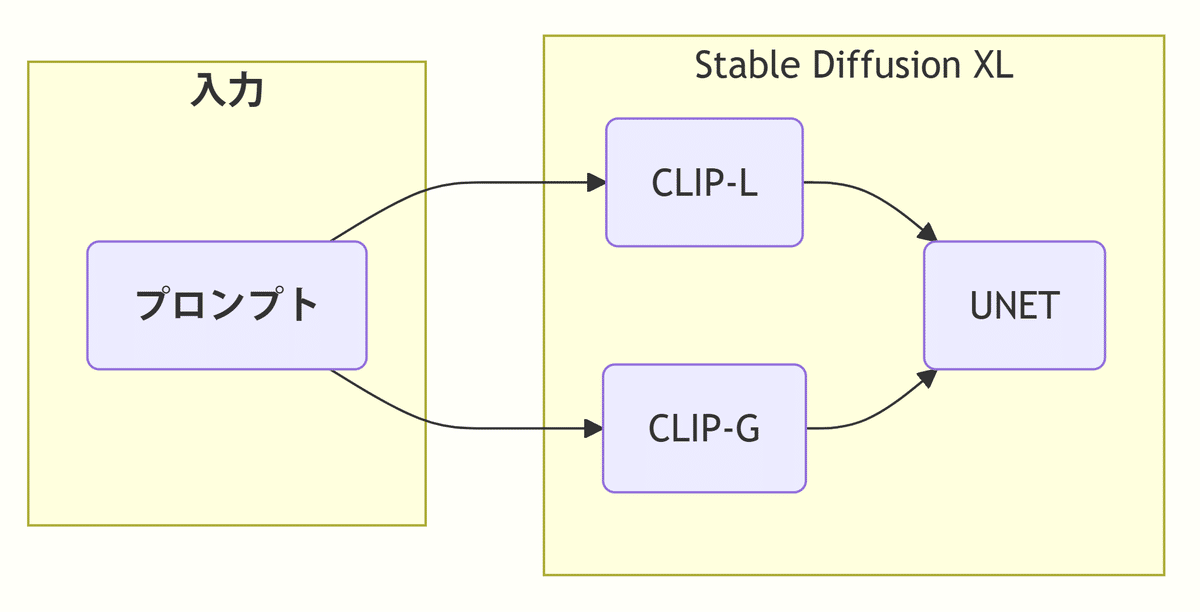
2023年7月に登場した Stable Diffusion XL は、テキストエンコーダーを従来の CLIP-L に加えて新しく CLIP-G も搭載しました。
CLIP-G は CLIP-L より性能が高く、さらに長い文章も理解できるようになり、プロンプトを 自然言語の長文 で入力できるようになりました。

SDXL モデルの容量は 7GBですが、CLIP-G をはじめとしたテキストエンコーダーはそのうち 1.8 GB を占めていて、SDXL がプロンプトの理解を重視していることが分かります。
Stable Diffusion 3:文脈を理解

2024年 6月に登場した Stable Diffusion 3 は、CLIP-L と CLIP-G に加えて新たに T5xxl も搭載することで、文章の理解力が向上しました。
T5xxl は高性能ですが、その分容量も大きく、エンコーダー部分だけでもサイズが 9GB もあります。

テキストエンコーダーが巨大化したことで、Stable Diffusion 3 から テキストエンコーダーを全体と分けて運用する のが一般的になりました。
Flux.1:CLIP-G が搭載されていない

2024年8月に登場した Flux.1 は、テキストエンコーダーは CLIP-L と T5xxl の 2つになっていて、CLIP-G は搭載されていません。
これはおそらく、CLIP-G の機能は T5xxl で十分にカバーできるという考えから来ているのだと思います。
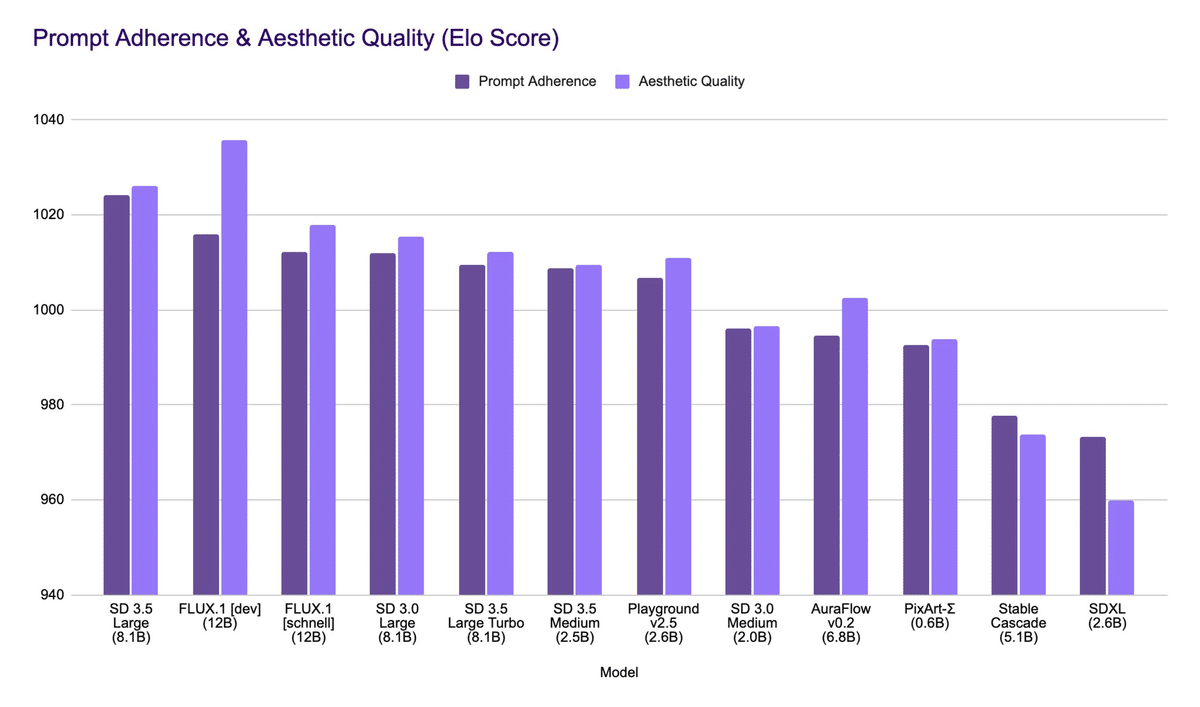
CLIP-G の有無から、Stability AI 社は Stable Diffusion 3.5 が Flux.1 よりも言語理解に優れていると主張していますが、実際のところ Flux.1 でプロンプトの理解力の不足を感じる場面はほとんどありません。
なお、前世代の CLIP-G でも、長文のプロンプトを入力しても実用上の理解力は十分 にあります。
改良型のテキストエンコーダー!
それでは、今回利用した改良型のテキストエンコーダーのリンクを紹介します。
改良型 CLIP-L
CLIP-GmP-ViT-L-14
CLIP-GmP-ViT-L-14 は、Zer0int 氏が個人が開発して無償で公開しているCLIP-L の改良モデルです。
開発の理由は CLIP が好きだから だそうで、自宅の PC で RTX 4090 を使ってトレーニングをしているそうです。
CLIP-GmP-ViT-L-14 は Global mean Pooling(GmP:幾何学的パラメータ化)という方法で従来の CLIP-L より精度を高めていて、ImageNet / ObjectNet というベンチマークで、オリジナルの CLIP-L の正答率 85% に対して 正答率が 90% と大きく性能が向上しています。
Zer0int 氏によると、CLIP-GmP-ViT-L-14 は CLIP-L の 画像理解における過度なこだわり が改善しているそうです。

CLIP-GmP-ViT-L-14 のダウンロードページには複数のファイルがありますが、オリジナルの FP32版に加えて、さらに改良を行った ViT-L-14-BEST-smooth-GmP-TE-only-HF-format.safetensors の FP16 版も公開されています。

どれを使うか迷ったら、この FP16版をダウンロードすれば良いでしょう。
Long-CLIP-GmP-ViT-L-14 (ComfyUI のみ)
Long-CLIP-L は、標準の CLIP-L モデルの 77トークン という制限を拡張して、最大248トークンの入力に対応できるように改良したモデルで、これにより CLIP-L でも長いプロンプトにも対応できるようになっています。
今のところ Long-CLIP-L を使えるのは ComfyUI のみ で、Stable Diffusion webUI Forge では利用することができません。

ダウンロードページには、オリジナルの FP32版に加えて、FP16 は性能向上版の Long-ViT-L-14-BEST-GmP-smooth-ft.safetensors も配布されています。
2024.12.31 追記
改良型 CLIP-L の効果を実際の画像で比較してみました。
Flan-T5xxl (改良型T5xxl)
次は T5xxl の改良型です。Flan-T5xxl は、通常のT5xxl に追加学習を行なって、精度を上げたモデルです。
Flan-T5xxl オリジナル(分割版)
Google が公開しているオリジナルの Flan-T5xxl は、容量が大きいため分割して配布されています(FP32形式は 44GB)。
Flan-T5xxl 結合版
オリジナルをもとに、画像生成AI で使えるように結合したファイルです。
FP32、FP16 形式を配布しています。
Flan-T5xxl GGUF 版(軽量版)
こちらは、有志が公開されている GGUF形式 に変換したモデルです。
GGUF形式の使い方は、前回の記事 を参考にしてください。
GGUF 版 をダウンロードするときは、右側の形式から自分の PC の性能にあったモデルを選択します。

ここで紹介した Flan-T5xxl はいずれもフルモデルなので容量が大きいですが、私の環境では ComfyUI・RAM 64GB・VRAM 16GB で Flan-T5xxl の FP32 形式を利用することができました。
ファイルの設置場所
ダウンロードしたファイルは次のフォルダに配置します。
インストールフォルダ/Models/CLIP
使うときは、それぞれ T5xxl と CLIP-L の代わりに選択すれば利用できます!

FP32 形式のテキストエンコーダーを使用する
テキストエンコーダーは、通常は FP16 形式で処理が行われます。
FP32形式で処理を行う場合は、ComfyUI の起動時に --fp32-text-enc の設定をする必要があります。

なお、この設定では FP32 と FP16 形式の両方のテキストエンコーダーを使用している場合、いずれも FP32 形式で処理されてしまいますが、通常はエンコードの処理自体は数秒以内に終了するので、大きな問題はないでしょう。
SDXL はテキストエンコーダーのアップグレードが難しい
今回は、Flux.1 でテキストエンコーダーをアップグレードしてみました。
Flux.1 と SD 3.5 はテキストエンコーダーを分けて運用しているので簡単にアップグレードすることができますが、SDXL と SD 1.5 は本体に結合 されているのでアップグレードはやや難しくなります。
この点については、次回改めて記事にしたいと思います!
まとめ:テキストエンコーダーを変えてみよう!
CLIP は文字をベクトルに変換する
T5xxl は文脈を理解する
改良型のテキストエンコーダーが公開されている

画像生成のクオリティーについて考えるとき、画像を生成するトランスフォーマー部分に注目して、テキストエンコーダーは後回しにすることが多かったと思います。
今回の検証で、テキストエンコーダーもかなり画質に影響を与えている ことが分かりました。

今回ご紹介した 改良型 CLIP-L は、小さな容量にも関わらず明らかに画質が改善するので、みなさんも一度試してみることをお勧めします。
最後までお読みいただきありがとうございます!
クリエイター紹介
さて、今回ご紹介するクリエイターは Shiki さんです。Shiki さんはかわいい猫耳のキャラクターと、きれいな色使いで独自の世界を表現されています。
イラストは、Leonardo AI をで画像を生成したあと、Google フォトアプリで色を調整して仕上げているそうです。
色の表現でイラストの印象は大きく変わってきます。特にきれいな肌色の表現は必見です!
Flan-T5xxl と T5xxl_v1.1 の比較記事の紹介
matataByy さんが、Flan-T5xxl と T5xxl_v1.1 を含めて T5xxl を詳細に比較する記事を公開されました。
それによると、
プロンプトの理解力は Flan-T5xxl-FP32 が良い傾向にある
Flux.1[dev] より Flux.1[shnell] の方がプロンプトの追従性が良い
のようです。皆様もぜひ一度ご確認ください!
更新履歴
2024.12.15 FP32形式のテキストエンコーダーの使用法を追記しました
2025.1.12 matataByy さんの記事の紹介を追加しました