
アリババ開発「Wan2.1」の衝撃🔥話題の動画生成AIの全貌を徹底解説💻 コレだけで、使い方・設定方法・ベストプラクティス・LoRA対応などなどが丸わかり💡

どうも皆さん!スーパーでレジ袋有料化以降、エコバッグを忘れた時の焦り、サバイバル能力が試される瞬間ですよね、 葉加瀬あい(ハカセアイ) です!
今回は、話題の動画生成AI「Wan2.1」を使って、高速かつ高品質な動画を生成する方法について解説します!

動画生成AIって、高性能なPCが必要だったり、設定が難しかったり、使いこなすのが大変そう…って思っていませんか?「自分のPCでも、本当にサクサク動いて、しかもキレイな動画が作れるの?」と不安に感じる方もいるかもしれません。
実は、「Wan2.1」とComfyUIなどを組み合わせることで、その悩みを解決できるんです!低スペックPCでも、驚くほど簡単に、ハイクオリティな動画が作れるようになります!
今回はその基礎編ということで、この記事や動画だけで「Wan2.1」がわかるように徹底解説していきたいと思います!

ということで今回お話しする内容はこんな感じです!
① VRAM 8GBのPCでも動く!「Wan2.1」の驚きの性能と、他の動画生成AIとの違いを徹底比較!
② ダンスや猫のボクシング、シネマティックな表現まで!「Wan2.1」の多彩な表現力を活かした動画生成テクニックを大公開!
③ ComfyUIで「Wan2.1」を使いこなす!詳細設定からトラブルシューティングまで、動画生成をマスターするための秘訣を伝授!

ちなみに、私、葉加瀬あいは、今まで約450本(約400万文字)の記事や動画を投稿してきたノウハウをもとに、 Note にて便利なAIワークフローやお得情報をたくさん掲載しております🙌

Youtube では、そのNoteの内容を動画にしていて、一部は、公開後の先着数十名さま限定で無料公開しております🙆♀️✨ チャンネル登録と通知をオンにしておくと見逃しませんよ!
https://www.youtube.com/@AI-Hakase

また、 X (旧Twitter) では、毎日100本程度の 最新AI速報 をお送りしております🚀

よろしければ、 Note 、 Youtube 、 X (旧Twitter) のフォローの3点をしていただけると嬉しいです🙆♀️✨
それでは、本日もよろしくお願いします!
Wan2.1の魅力と、他の動画生成AIとの違いについて!
それでは、まずWan2.1って本当にすごいの?というお話なんですけども⋯結論から申し上げますと、かなりすごいです!⋯というか、みなさん使った方がいいレベルですね!

生成品質の高さと動作速度
生成品質も高いですし、なんと! 今までの動画生成AIと違って、かなり 高速に動作 します!

将来性について
それと、画像生成AIモデルとか動画生成AIモデルって、ここがすごい大事なんですけども、 将来性もすごい んです!

様々な入力形式に対応
テキストからでも、画像からでも、他のビデオからでも⋯
何からでも動画にできますし!

動画編集機能
動画編集もできるんです!

多言語対応
中国語とか英語のテキストも生成できる、初めての オープンソース動画生成AIモデル です!
ちなみに、中国語も書けるということは、ある程度の漢字とかも生成できるということですね!

様々なデバイスに対応
それと、いろいろなデバイスにも対応しているので、ハイスペックなPCから低スペックなPCや、WindowsやMacOS、Google Colabなどのクラウドサービスとかから、 簡単に利用 もできます!
本当にすごすぎますよね!

他の動画生成AIモデルとの比較
それでは、ここから、いろいろと詳しく解説していきたいと思います!
このWan、他のAI技術、つまり、ステイブルビデオディフュージョン(SVD)や、SkyReels、Hunyuan Video、Pika AI、Runway Gen3などの、他の動画生成AIモデルと比べて、何が優れているのかと言いますと⋯
まず、 すごくPCに優しい です! つまり、高性能なGPU(グラフィックボード)と、大量のビデオメモリー(VRAM)を必要としません!

今まで、こういうのが大量に、高性能なものが必要だったので、企業が提供しているクラウドサービスを使ったり、高性能な30万円とか50万円とかするPCを買う必要があったんです。
このWan2.1では、その必要がなくなりました! VRAM 8GBのPCから動作 します! ちなみに、このスペックのPCの価格帯は、だいたい10万円ぐらいです! ちゃんと探せば、もっと安いものもあります!

正直、今まで、いろんな動画生成AIの業界が、少ないモデルサイズや少ないVRAMの消費量で動画を生成するのに躍起になっていたんですけども⋯今回のこのWan2.1は、その問題を結構解決してくれて、しかも、それなのに、 高品質な動画生成と高速な動画生成を兼ね備えている というのが、本当にすごいところですね!
品質について、気になっている方もいらっしゃるかと思います!

それで、実際、どんなことができるかというのも、気になりますよね⋯!

動画生成AI「WAN2.1」の魅力的な機能をご紹介!
次に、この「WAN2.1」が具体的にどのような機能を持ち、どのような動画を生成できるのか、より詳しく見ていきましょう。
先ほども少しお話ししましたが、改めて「WAN2.1」の機能について詳しく解説させていただきますね!

例えば、こんな感じの激しいダンス動画も作成可能です!
それから、猫がボクシングをしているような複雑な動きも、割と得意としているんですよ⋯!

物理法則の理解度がすごい!
こちらをご覧いただくと分かりやすいと思うのですが⋯ 物理法則 をきちんと理解している点が、本当に優秀なポイントなんです!
料理をしたり、水面から人や物を出現させたり、アーチェリー、水が弾ける様子など⋯。
こういった表現は、従来のAIでは難しいとされていたのですが、「WAN2.1」は見事に対応してくれていますね!

シネマティックな表現も得意!
さらに、ご覧の通り、 シネマティックな雰囲気 も非常に綺麗に表現できます!
ダイバーが潜っている様子、人の瞳の色が変わる瞬間、モンスターズインクのようなキャラクターがベッドで跳ねているところ、カラスの描写など、本当に美しいですよね⋯!
少年が宙に浮いているシーンなど、こういったシネマティックな表現も「WAN2.1」は得意としているんです!

多様な入力ソースに対応!
「WAN2.1」は、テキスト、画像、動画から動画を生成することができます!
これから、その詳細について解説していきますね。

①テキストから動画を生成
まずは、 テキストから動画を生成 する機能です。具体的には、このような動画が作成できます!

②画像から動画を生成
次に、 画像から高品質な動画を生成 する機能です。
ご覧ください!このような感じになりますね。

③動画から動画を生成(動画編集機能)
そして3つ目は、 動画から動画を生成 する機能、つまり 動画変換 や 動画編集機能 です!

先ほど少し触れましたが、「WAN2.1」は 動画編集機能 も備わっています!具体的には、このような動画編集が可能です。
ビデオを別のものに変換する、 インペインティング で指定した場所のライオンをクマに変換する、 アウトペインティング で動画の左右にオブジェクトを追加する、 リファレンス機能 で2枚の画像を指定してキャラクター動画を作成するなど、様々な編集ができます!
ここらへんは後々解説する、動画生成のやり方ではちょっとまだできないんですけど、おそらく動画版のControlNetのようなものが出てきて、それで実装するみたいな雰囲気になると思います!

音楽の追加も可能!
さらに、「WAN2.1」では 音楽の追加 も可能です!
水のフェレットが水に入る音、オーケストラの音楽、氷が落ちる音など、とてもリアルですよね⋯!
参考: https://x.com/ai_hakase_/status/1896453831900491893

文字生成にも対応!
そして、ここが他の動画生成AIとは違う、特に素晴らしい点なのですが⋯なんと、 文字にも対応 しているんです!
具体的には、中国語や英語のテキストを生成できます!
他のオープンソースの動画生成AIでは考えられないことでしたので、この機能が実装されたのは本当にすごいことですね!

LoRA (Low-Rank Adaptation)にも対応!
さらに、「WAN2.1」はなんと LoRA も使えます!
それでは、このLoRAとは一体どういった技術なのでしょうか。次は、このLoRAについて詳しく見ていきましょう。
元のモデルの大部分は変更せずに、小さな追加モジュール(LoRA)を学習させることで、特定のスタイルやキャラクターを生成できるようになるんですよ⋯!
具体例をいくつか挙げますと、LoRAの強さも調整できるので、お好みのキャラクターを動画に登場させたり、お好みの画風で動画生成をしたりといった柔軟性も兼ね備えているんです!

Wan2.1の驚くべき総合力!
ここまでくると、 強くて早くて柔軟性も兼ね備えている ということになります!
しかも、多くの企業やコミュニティの方々に使われて、どんどん改善されていくという⋯本当にすごいAIが誕生したなと感じています!
Alibaba(アリババ)が開発した「Wan2.1」!
さて、この素晴らしい「Wan2.1」を開発したのは、あの有名な中国の巨大企業、 アリババグループ なんです!
中国系の企業といえば、以前にもご紹介した「Shaker AI」のように、他のサイトよりも高品質な画像生成AIモデルを提供しているケースが多いんですよね。
実は中国系の企業は、 AI分野において非常に強い技術力 を持っているんです!
たまに中国系の企業というと少し敬遠されがちな方もいらっしゃるかもしれませんが、私自身も実際に中国系のクライアントと一緒にお仕事をすることがあります。
特にアリババのようなメガテック企業は、 コンプライアンスや契約についてもしっかりとした体制 が整っていて、社会的な信頼性も非常に高いと思います!

オープンソースであることの強み
ちなみにライセンスを自由にすることで、みんなに使ってもらって成長させていくといった利点もあるんです!
結構ここら辺も注目されている理由なんですよね。
WANの最も良いところは、このApache 2.0ライセンスを有するところでして、つまりは商用利用なども認められているので、いろんな企業がこのWANを使用して ビジネスを展開できるんです。

そして、その改善ポイントも一般に広まっていくので、もっと開発されて、いろんな人にオープンソースの強みを生かしていろんなカスタマイズがされて、どんどん魅力的な動画生成AIモデルになっていく⋯しかもそれが無料で使えるようになるというのが、すごい注目ポイントなわけですね!
これだけ聞くと、ただすごく新しい動画生成AIモデルというわけではなくて、本当に将来性のある動画生成AIモデル、オープンソースの動画生成AIモデルだということが分かっていただけましたでしょうか?

低VRAM環境でも高品質な動画生成が可能!
それで、先ほど8GBのVRAMから動作するということをお伝えしたんですけれども、ちょっとそこについても簡単に解説をしていきます。
このWAN2.1の最大の特徴は、 低VRAM環境でも高品質な動画を生成できる点 でもあるわけなんです。

具体的には、8GBのVRAMを搭載したGPUでも、8秒間の480P動画を生成できます。
さらに、14Bモデルを使用すれば、720pの5秒動画も生成可能です。
消費者グレードGPUをサポート - T2V-1.3B モデルでは、 8.19GB VRAM のみを必要としているため、ほとんどの消費者向けGPUでアクセスできるのもすばらしいですね!

ベンチマークの比較!
次に、ベンチマークの比較を見ていきましょう。
ベンチマークというのは、性能を評価するための指標のことです。
ここでは、LUMA AI、EasyAnimate V5.1、MiniMax Video、Hunyuan Video、Runway Gen3など、他の動画生成AIとの比較結果を見ていきます!
その性能は、他のオープンソースモデルや商用モデルを凌駕すると評価されています。

VBenchによると、総合スコアが86.22%のWAN2.1シリーズは、動的程度、空間関係、色、マルチオブジェクトの相互作用などの主要な次元をリードしています。
つまり、このモデルは、テキストや画像から高品質な動画を生成できる能力を持っているんです。
しかも、低いVRAMでも動作し、高速に生成できるため、総合的な満足度はかなり高いと言えるでしょう!

RIFlux技術: 動画の繰り返し問題を解消!
この高品質な動画生成を支えているのが、RIFlux技術です!
従来の動画生成AIでは、同じ動きが繰り返されたり、不自然な動きが生じたりすることがありました。Wan2.1に統合されたRIFlux技術は、この問題を解決し、より自然で滑らかな動画生成を実現します。
具体的に言うと、RIFluxは、動画の各フレームを「絵コンテ」のように捉え、それぞれのフレーム間の関係性を学習します。これにより、全体の流れを考慮した、一貫性のある動きを生成できるんです!

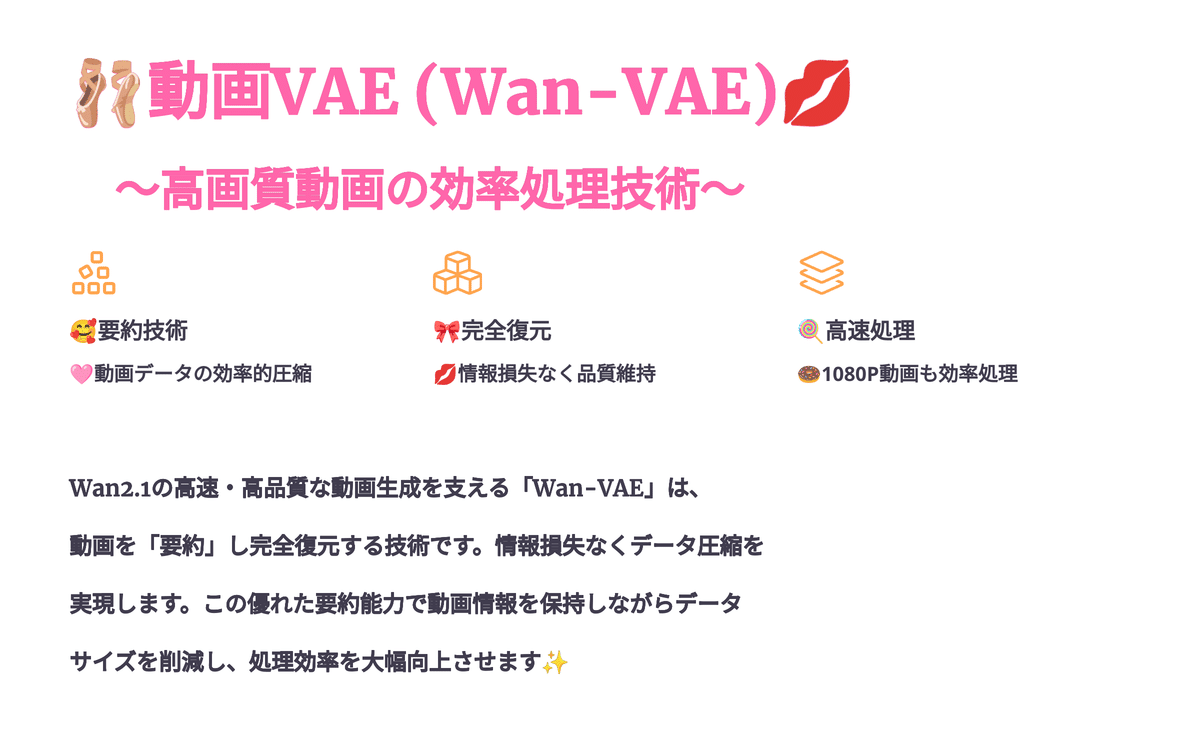
動画VAE (Wan-VAE):高画質動画を効率的に処理する技術!
さらに、Wan2.1の高速生成と高品質な動画生成には、「Wan-VAE」と呼ばれる動画版のVAEも大きく貢献しています。

Wan2.1は、「Wan-VAE」と呼ばれる、 高性能な動画VAE(変分自己符号化器) を採用しているんです!
VAEって聞くと難しそうに感じるかもしれませんが、簡単に言うと、動画データを効率的に圧縮したり、解凍したりする役割を担っているんですよ⋯!
強力なビデオVAE技術 により、Wan-VAEは時間的な情報をしっかり保存しながら、 1080pの高画質ビデオ を効率的にエンコード・デコードできるんです。
これが、AI動画生成の強力な基盤となっているんですね!

分かりやすく例えると…
Wan-VAEは、動画を「要約」して、その「要約」から元の動画を復元するようなものなんです!
例えば、2時間の映画を5分で説明するような感じでしょうか⋯🎬
でも、普通の要約と違うのは、Wan-VAEの要約からは、元の映画の すべての重要な情報 を完全に復元できるんです!
要約が上手ければ、元の動画の情報を失うことなく、データサイズを小さくできるということですね!
Wan-VAEは、この要約と復元が とっても得意 で、1080Pの高画質動画でも効率的に処理できちゃうんです。
本当に、すごいですよね!😊
その他の最新技術:メモリ効率と高速化のヒミツ🚀
Wan2.1は、RIFluxやWan-VAE以外にも、以下のような技術によって、低VRAM化と高速化を実現しているんです!

メモリ効率の改善
GPUメモリの使用量を最適化し、より少ないメモリで動画生成を可能にしています。

コンパイル
モデルを事前にコンパイルすることで、実行時の処理を高速化しています。
高速ロード/アンロード
必要なデータだけを素早くロード・アンロードすることで、メモリ使用量を削減し、処理を高速化しているんですね!
RTX 4090 では、 約4分で5秒の480pビデオ を生成します(最適化なし)。

ここで「最適化なし」と書いたのは、最近このWANの技術がとても進んでいて、コミュニティの作成したカスタムノードやプログラミングコードを利用すると、50%の速度アップなどが見込めるようになってきているからです!
本当に、そういう意味では将来性がありますよね⋯!
ちなみに、このメモリ効率の削減とか、コンパイルとか、高速ロードとか、アンロードとかは、かなり最近のコミュニティでも活発に改善が進められています。
コミュニティの作成したカスタムノードやプログラミングコードを利用すると、50%の速度アップなどが見込めるようになってきているからです!

WANを利用する方法
それで、このWANを利用する方法についてなんですけども、ちょっといろいろあります。

Hugging Face Spaces
Wan2.1のデモが公開されており、Webブラウザ上で手軽に試すことができます!
テキストや画像を入力するだけで、簡単に動画を生成できるんです!
もし、手軽に使ってみたいという方がいらっしゃると、こちらの方からのご利用をお勧めいたします!
こんな感じで、text to Videoにも、image to Videoにも、どちらにも対応しているので、手軽に試すことができるかと思います!
一応、こちらURLになります!
参考: https://huggingface.co/spaces/Wan-AI/Wan2.1

Replicate
クラウド上でAIモデルを実行できるプラットフォームです。
Wan2.1も利用可能で、API経由で動画生成を行うことができます。
https://replicate.com/wavespeedai/wan-2.1-i2v-720p

こちらに関しては、もっと自由に生成してみたい方向け、といった雰囲気になります!
一応、これも開発者向けになっちゃうんですけど、APIとか一応使えるので、アプリケーションとかに組み込んでみたい方とかは、ここら辺を使ってみるといいんじゃないかなと思います。
プロンプトとか画像とかを入れてあげて動画生成したりとか、いろいろとできるみたいなので、よかったら、興味のある方はこちらから試してみてください!
ちなみに、大体2分ぐらいで生成できるんです!すごい高速かなと思います。
それで料金は、大体以下のような雰囲気になっていて、GitHubアカウントというものを持っていれば、誰でも利用することができます。
気になる料金は、ビデオの1秒あたり0.50ドルくらいですね!

ローカル環境
自身のPCにWan2.1のモデルをダウンロードし、ローカル環境で実行することも可能です。
次は、ローカル環境での実行についてです。より詳しく見ていきましょう。

Wan2.1のモデルをローカル環境で実行する方法!
Wan2.1のモデルをご自身のPCにダウンロードして、 ローカル環境で実行 することも可能なんです!
一応、こちらに書いてあることを実行すると、動画生成自体は行うことができます!
⋯ただ、ここは結構開発者向けかもしれないです!
https://github.com/Wan-Video/Wan2.1?tab=readme-ov-file

詳細なやり方について!
こちらの部分に、詳しいやり方は書いてあるので、よかったら見てみてください!
一応、この部分のURLとかも載せておきます!
参考: https://github.com/Wan-Video/Wan2.1?tab=readme-ov-file#quickstart

Discordチャンネルから利用する方法!
はい!そしてもう一つが、 Discordチャンネルから利用する方法 ですね!
こちらに関しては、 完全に無料 で利用できます!
ただし⋯サーバーがこれ以上大きくなってしまうと、参加できなくなる可能性とかもあるので、早めに参加して利用された方が良いかと思います!
こんな感じでDiscordから、 text to Video とかを、試すこととかができるので、よかったら皆さんも使用してみてください!
あと、最近、 image to Video にも、対応したので、image2videoとtext2videoを両方試してみたい方は、こちらのDiscordチャンネルから、ぜひ動画の作成を行ってみてください!
参考: https://discord.com/invite/7tsKMCbNFC

一応コマンドの例としてはこんな感じになります!
こちらのようなコマンドを入力すると生成できます!

ComfyUIを使った動画生成!
ComfyUI: ノードベースのGUIでStable DiffusionなどのAIモデルを操作できるツールです!
Wan2.1にも対応しており、より詳細な設定を行いながら動画生成を行いたい場合に適しています!

ちなみに、私のおすすめの方法がこちらになります!
一応こちらにも書いてあるんですけれども、VRAM 8GBでも、480×480の解像度であれば、だいたい10分くらいで生成は終わるみたいですね!
はい!それで、やり方なんですけども、まずはこちらから、 ワークフローをダウンロード してあげてください!
一応、公式のダウンロードリンクとかも、一緒に置いておきたいと思います!
こちらが テキストから動画を生成する方 のワークフローになりまして⋯
https://comfyanonymous.github.io/ComfyUI_examples/wan/image_to_video_wan_example.json

2つ目が、 画像から動画を生成するため のものになります!
https://comfyanonymous.github.io/ComfyUI_examples/wan/text_to_video_wan.json
ちなみに、ワークフローを開きますと、こんな感じの画面になるかと思いますので、この画面になったら Ctrl+"S"など でダウンロードしてあげてください!

ComfyUIでの動画生成手順!
以下の手順で必要なモデルをダウンロードして配置すれば、動画生成できるようになります!

テキストエンコーダーとVAEの配置:
テキストエンコーダーモデル:
1. umt5_xxl_fp8_e4m3fn_scaled.safetensors をダウンロード
2. ダウンロードしたファイルを `ComfyUI/models/text_encoders/` フォルダに配置

VAEモデル:
1. wan_2.1_vae.safetensors をダウンロード
2. ダウンロードしたファイルを `ComfyUI/models/vae/` フォルダに配置

動画生成モデルの配置
次に動画生成用のモデルをダウンロードして配置します:
テキストや動画を生成したい場合は、まずはこちらのモデルをダウンロードしてください!
fp8モデルファイル を使用するのがおすすめです。
画像から動画を生成するモデル
画像から動画を生成したい場合は、こちらのモデルをダウンロードすると良いでしょう⋯!
wan2.1_i2v_480p_14B_bf16.safetensors : `ComfyUI/models/diffusion_models/` に配置
clip_vision_h.safetensors : `ComfyUI/models/clip_vision/` に配置

フレームレートや生成時間について
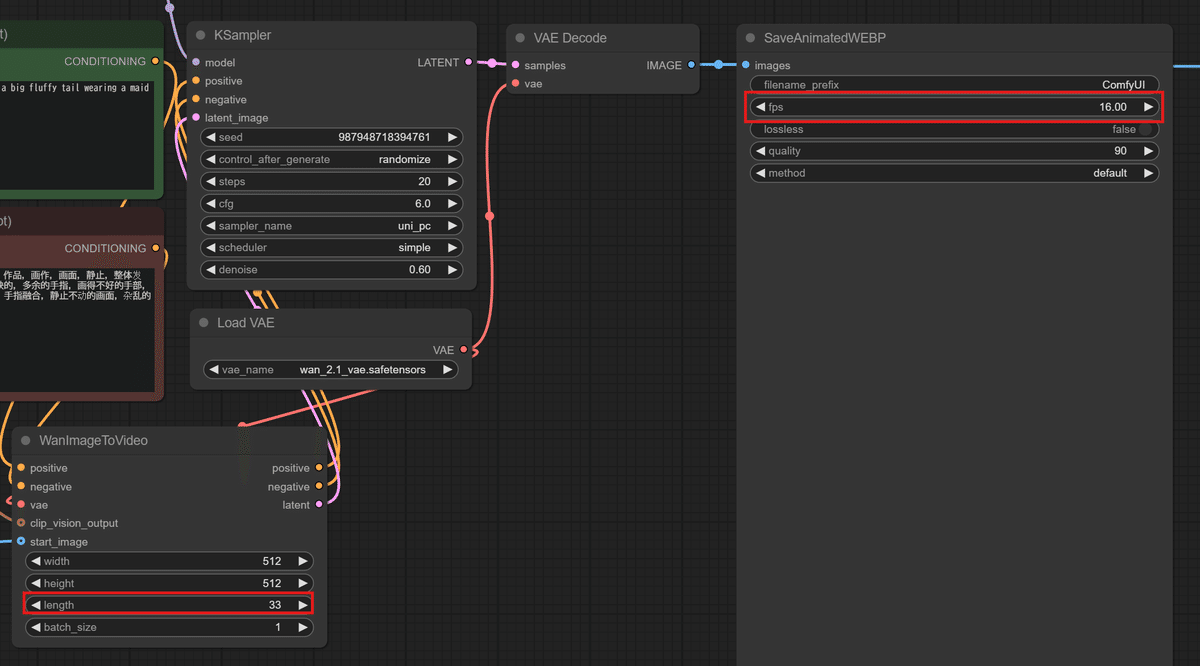
モデルを配置したら、ComfyUIに先ほどのダウンロードしたワークフローをドラッグ&ドロップしてあげます!
そうするとこちらの画面になるんですが、赤枠で囲った部分、実は とっても重要 なんです!

デフォルトでは、 16fps で 33フレーム (Length)、つまり約2秒間の動画が生成されます。
Lengthの値は、最初は少し分かりにくいかもしれませんが、
Length ÷ FPS = 生成時間(秒)
という計算で、おおよその生成時間を把握できます。
例えば、33フレームを16fpsで割ると、約2秒になります!

モデルやVAEをきちんと適用したら、一番下の「 Queue 」ボタンを押して、生成を開始してください!

ワークフローの例
ちなみに、Image2Video (画像をビデオに変換) のワークフローは、このような感じになっています!

生成される動画の雰囲気
テキストから動画を生成すると、こんな感じの雰囲気になります!

画像から動画を生成する場合は、こんな感じになります!

その他のモデル
他のモデルもこちらからダウンロードできますので、ぜひチェックしてみてください!
参考: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/diffusion_models

各モデルの選び方について
ちなみにこの他にも、GGUFの量子化モデルなど、色々なモデルが登場していますが、基本的な選び方を簡単に解説します!

VRAMが6GBから12GB程度の場合は、 1.3Pの軽量版モデル を使用することが多いです!
FP8版とFP16版がありますが、FP16版の方が少しRAM (メモリー) を多く使用します。
32GB程度のRAMを搭載しているPCであれば、FP16版でも大丈夫でしょう⋯!

VRAMが16GBや24GB程度の場合は、480ピクセル版のFP8版またはBF16版を使うと良いでしょう!
こちらも、 メモリーの要件に合わせて 選んでみてください。
ちなみに生成方法は異なるのですが、12GB VRAMでも動作する、 量子化版のGGUF形式 のモデルもあります!ここについてはまた今度解説しますね!

VRAMが40GB以上の場合
720P版の14Bモデルは、VRAMが40GBでも足りない場合があるようです⋯!
かなりハイスペックなPCか、RunPodのような50GBや100GBのVRAMを使えるクラウドサービスを利用しないと、生成は難しいかもしれません。

NIMで使用されているモデル
ちなみに、前回ご紹介した動画生成AIサービス「NIM」で使用されているモデルは、おそらくこの720ピクセル版の14Bモデルだと思われます!
有料の動画生成AIサービスは、高性能のサーバーを使っているので、このようなハイスペックモデルも動かせるんですね!
https://note.com/ai_hakase/n/n963d888fc0d6
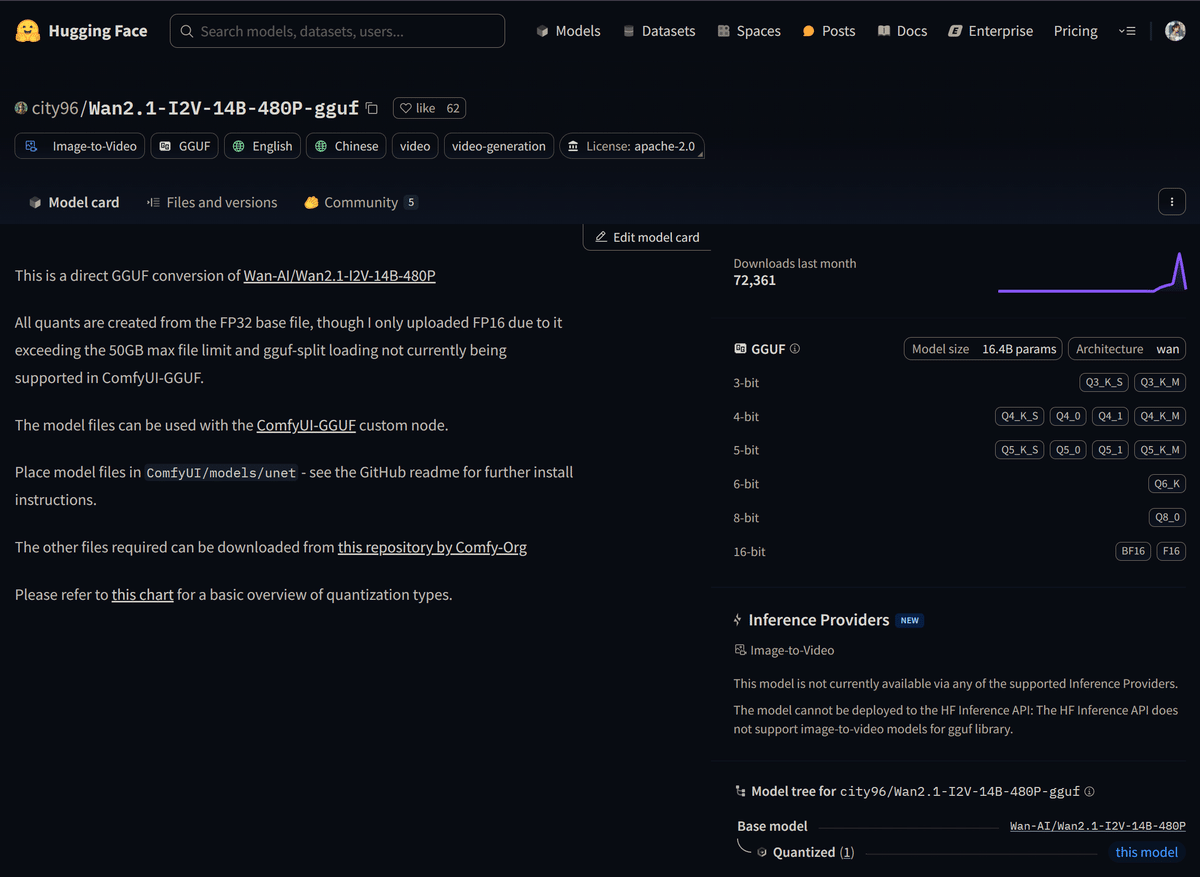
GGUF量子化版について
ちなみに、ちらっとご紹介したように、GGUFの量子化版も色々と出てきています!
こちらを見ていただくと分かりやすいかもしれませんが、14Bの480ピクセルモデルで、各PCのVRAM (例えば12GBや6GB) に合わせて 量子化 (単純な圧縮) を行い、 低いVRAMでも実行できるように軽量化 されたモデルが利用可能になっています。
参考: https://huggingface.co/city96/Wan2.1-T2V-14B-gguf

WAN2.1については、量子化版モデルのリリースに加えて、さらに効率的なアルゴリズムで生成する技術も登場しています。
そのため、ここでお伝えしたモデルの選択方法が全てではない、ということを覚えておいてください!
これらのモデルを活用することで、より手軽に動画生成を楽しめるようになってきました。さらに、ComfyUIでの生成においては、いくつかの設定を最適化することで、より高品質な動画を得られます。

ComfyUIでのWan2.1生成!ベストプラクティスをご紹介!
ちなみにここからは、ComfyUIでWan2.1を使って動画生成する際の、とっておきの情報をお届けします!⋯といっても、公式のワークフローだと、デモ動画ほど品質が良くならないこともあるかもしれません。でも、ご安心ください!もっときれいな動画にする方法があるんです!

Wan2.1生成の推奨設定!
まずは、ざっと基本的な設定から解説します!
CFGスケール (Guidance): 5〜7程度が適切です!開発者の方の推奨は「約6」とのこと。高すぎるとフレーム間の変化が大きくなって、ちらつきの原因になることがあるんです⋯。逆に低すぎると、プロンプトから外れたり、ランダムな結果になったりすることも。
サンプリングステップ: 20ステップ程度が基本です!もし、もっと高精細にしたい場合は、25〜30ステップを試してみてください!ただ、30ステップを超えると効果が薄れてくることもあるので注意が必要です。

解像度とアップスケーリング: これはもう、ハードウェアが許す限り、 最高解像度 で生成しちゃいましょう!Wan2.1の14Bモデルなら720pですね!そして、必要に応じてアップスケールするのがベストな方法です。

ちなみに、Wan2.1の14Bモデルには、480p (832x480) と 720p (1280x720) の2つの解像度があります。
なんと、16GB以上のVRAMがあれば、720pモデル(1.3Bモデル)も利用可能とのことです!

でも、ここだけの話、実は今、GGUFとか、低いVRAM向けの設定のWan2.1の生成アルゴリズムなど、色々出てきているんです! 量子化モデル とかを使ってもいいかもしれません!この辺りは、また今度詳しく解説します!

フレームレート (FPS): Wan2.1のモデルは16FPSでトレーニングされているんです。ですから、生成も16FPSで行って、後処理で24FPSや30FPSに変換するのがおすすめです!
このあたりの詳しいやり方、例えばアップスケーリングと合わせて行うワークフローとかも、また今度じっくり解説します!

Image-to-Imageのベストプラクティス!
次は、Wan2.1のImage-to-Imageの書き出しに関する、とっておきのテクニックをご紹介します!これを使うと、さらに一貫性を高めて、アーティファクト(ノイズや歪み)を防ぐことができるんです!

Denoising Strength: img2imgアプローチを使う場合は、0.4〜0.6程度が最適です!
それから、これはText-to-Videoを使うときにも言えることなんですが⋯
Camera Movement vs. Object Movement: プロンプトで指定するときは、 カメラの動きとオブジェクトの動きを区別 して制御することが重要です!
Preventing Distortions: 「deformed, distorted, disfigured」などの ネガティブプロンプト を効果的に使って、歪みを防ぎましょう!

トラブルシューティング!よくある問題と解決策!
最後に、動画生成でよくある問題と、その解決策をまとめてご紹介します!
フレーム間のちらつき: CFGスケールを下げる、プロンプトを一定に保つ、ネガティブプロンプトを追加するなど、色々な方法があります!
詳細の不一致/オブジェクトのドリフト: プロンプトで詳細を強調したり、LoRAを使用したりしてみてください!
ぼやけ/詳細の損失: サンプリングステップを増やす、VAEを確認する、解像度を上げるなど、試してみてください!

歪んだ形状/アーティファクト: ネガティブプロンプトを効果的に使うのがおすすめです!
VRAMクラッシュ/フリーズ: モデルを軽量化する、解像度を下げる、VAEタイリング(例えば256とかになっていたら96や128とかに下げるなど)を使用するなど、PCへの負担を減らしてあげましょう。
生成時間が長い場合: 動画を短くするのが一番!3〜5秒程度の短いClipで生成するのがおすすめです!

生成される動画の長さの指定がよくわからないという方もいらっしゃるかもしれませんが、先ほども説明した通り、大体は レングスの部分とFPS (フレームレート) の割り算 で動画の秒数が決まります!
例えば、レングスが33でFPSが16だったら、33割る16で約2秒、といった感じですね!
GGUFの量子化版について
それとこちらも繰り返しになりますが、GGUFの量子化版も色々と出てきています!こちらを見ていただくと分かりやすいかと思いますが、14Bの480ピクセルモデルで、各PCのVRAM (例えば12GBや6GB) に合わせて 量子化 (単純な圧縮) を行い、 低いVRAMでも実行できるように軽量化 されたモデルが利用可能になっています。
参考: https://huggingface.co/city96/Wan2.1-T2V-14B-gguf
Wan2.1の活用方法と関連技術について
ちなみにここも大事なことなので繰り返しになるのですが、Wan2.1に関しましては、 量子化版モデルのリリース だけでなく、さらに効率的なアルゴリズムで生成する技術も登場しているんです!

ですから、ここでお伝えしたモデルの選択方法が全てではない、ということを覚えておいてください!

今回、Wan2.1の基礎知識については、できるだけ丁寧にご説明してみました!

量子化モデルとWan2.1の利用
その中で量子化モデルなどをしてきたと思うのですが、実はその他にもワンクリックでWan2.1を利用する方法もあるんです!

また、 Wan2.1の720モデル のような高性能なモデルを使えるようにするアルゴリズムなども登場してきたとも申し上げたと思うのですが、それらについてもまた今度詳しく解説していこうかと思います!

動画生成AIの最新技術とComfyUI
ちなみに、こういった動画生成AIや画像生成AIなどの最新技術に対応するには、ComfyUIの使い方がとても重要になってきます⋯!
ですが、ノードベースなので使い方が分かりづらいという方もいらっしゃるかもしれません。
そのような方のために、こちらの記事で「サクッと回らずComfyUI」と題して、簡単に最低限必要な知識を解説しています。記事と動画で解説していますので、よろしければご覧になってみてください!
https://note.com/ai_hakase/n/n5486e3a98997?magazine_key=m574f2e03ca50&from=membership-magazine

ComfyUIをクラウド環境で使う
もしComfyUIを使ってみたい!と思っていただけたら、こちらの記事で、クラウド環境から簡単にComfyUIをインストールして実行する方法を解説しています。ご自身のPCのスペックに余裕がない方は、こちらからComfyUIを使えるようにしてみてください!
https://note.com/ai_hakase/n/n12b1ddf1e372?magazine_key=m574f2e03ca50&from=membership-magazine

ComfyUIをローカル環境にインストール
ご自身のローカル環境、つまり 自分のPCにComfyUIをインストールする方法 については、こちらで解説しています。だいたいVRAMが12GBくらいあれば、ローカルにインストールしても良いかと思いますので、当てはまる方はぜひこちらをご覧ください!
https://note.com/ai_hakase/n/n0c099ec9f96e?magazine_key=m574f2e03ca50&from=membership-magazine
ちなみに、 VRAMの確認方法 ですが、CtrlキーとShiftキーとESCキーを同時に押してタスクマネージャーを開きます。そこの「パフォーマンス」から「GPU」欄を見ていただくと、ご自身のPCのVRAMがどのくらいか確認できます!

AI初心者向けの情報
最後に、AIをどのように使えば良いか分からない、始めてみたけれど右も左も分からない⋯という方のために、「AI始めましてセット」として、初心者の方におすすめの記事や動画をまとめています。
動画で見たい方は、記事の中に動画版のURLが記載されていますので、ぜひチェックしてみてください!
https://note.com/ai_hakase/m/m574f2e03ca50

🎈おわりに
いかがだったでしょうか!今回は、低スペックPCでも高品質な動画生成が可能な動画生成AI、Wan2.1についてでした!
1. テキスト、画像、動画など多様な入力形式に対応し、動画編集機能や多言語対応も備えている。
2. VRAM 8GB程度のPCでも動作し、物理法則を理解した表現やシネマティックな動画生成が得意。
3. ComfyUIと連携することで、CFGスケールやサンプリングステップなどを調整し、より高品質な動画を生成できる。
ぜひWan2.1を試して、皆さんだけのオリジナル動画を作成してみてください!!

今回の記事と動画、お楽しみいただけましたか?
「参考になった!」と思っていただけたら、 Note のフォロー、いいね、グッドボタンの3点をぜひお願いします✨

Youtubeの方 も、まだの方はチャンネル登録していただけると嬉しいです☺️
https://www.youtube.com/@AI-Hakase

それと、実は最近、公式LINEを始めました!
Noteのメンバーシップ の入門者さん限定で、質問対応なども行っています。
『NoteのID + 質問したいNote記事のURL』 を添えていただければ対応いたしますので、よろしければご利用ください🙌

マガジン でもジャンルごとに記事や動画をまとめていますので、質問の前にご覧いただくとスムーズかと思います🙌
参考: https://note.com/ai_hakase/magazines

それでは、また次回の記事か動画でお会いしましょう!
葉加瀬あいでした!バイバイ!
☑️ 関連リンク一覧
(※ AI生成です。リンクは正しいですが、タイトルは間違っていることがあります。)
X(Twitter)での音楽追加に関する投稿 - 音楽の追加,音楽の追加,https://x.com/ai_hakase_/status/1896453831900491893
🔗:https://x.com/ai_hakase_/status/1896453831900491893LINE公式アカウント - LINE,公式LINE,https://line.me/R/ti/p/
🔗:https://line.me/R/ti/p/YouTubeチャンネル - Youtube,Youtube,https://www.youtube.com/
🔗:https://www.youtube.com/Note(葉加瀬あい)- Note,Note,https://note.com/ai_hakase
🔗:https://note.com/ai_hakaseNote マガジン一覧 - Note,Note記事のURL,https://note.com/ai_hakase/magazines
🔗:https://note.com/ai_hakase/magazinesDiscord サーバー - Discord,text to Video,https://discord.com/invite/7tsKMCbNFC
🔗:https://discord.com/invite/7tsKMCbNFC最新AI動画生成ツール「Nim」徹底解説 - Note,動画生成AIサービス「NIM」,https://note.com/ai_hakase/n/n963d888fc0d6
🔗:https://note.com/ai_hakase/n/n963d888fc0d6AI・はじめましてセット - Note,AI始めましてセット,https://note.com/ai_hakase/m/m574f2e03ca50
🔗:https://note.com/ai_hakase/m/m574f2e03ca50Hugging Face Space (Wan2.1) - Hugging Face,text to Video,https://huggingface.co/spaces/Wan-AI/Wan2.1
🔗:https://huggingface.co/spaces/Wan-AI/Wan2.1Hugging Face (GGUF量子化版) - Hugging Face,GGUFの量子化版,https://huggingface.co/city96/Wan2.1-T2V-14B-gguf
🔗:https://huggingface.co/city96/Wan2.1-T2V-14B-ggufReplicate (Wan 2.1 image to video) - Replicate,Wan2.1,https://replicate.com/wavespeedai/wan-2.1-i2v-720p
🔗:https://replicate.com/wavespeedai/wan-2.1-i2v-720pGitHub (Wan2.1) - GitHub,開発者向け,https://github.com/Wan-Video/Wan2.1?tab=readme-ov-file
🔗:https://github.com/Wan-Video/Wan2.1?tab=readme-ov-fileGitHub (Wan2.1 Quickstart) - GitHub,詳しいやり方,https://github.com/Wan-Video/Wan2.1?tab=readme-ov-file#quickstart
🔗:https://github.com/Wan-Video/Wan2.1?tab=readme-ov-file#quickstartComfyUI ワークフロー (画像→動画) - ComfyUI,画像から動画を生成するため,https://comfyanonymous.github.io/ComfyUI_examples/wan/text_to_video_wan.json
🔗:https://comfyanonymous.github.io/ComfyUI_examples/wan/text_to_video_wan.jsonComfyUI ワークフロー (テキスト→動画) - ComfyUI,テキストから動画を生成する方,https://comfyanonymous.github.io/ComfyUI_examples/wan/image_to_video_wan_example.json
🔗:https://comfyanonymous.github.io/ComfyUI_examples/wan/image_to_video_wan_example.jsonさくっと学ぼうComfyUI! - Note,ComfyUI,https://note.com/ai_hakase/n/n5486e3a98997?magazine_key=m574f2e03ca50&from=membership-magazine
🔗:https://note.com/ai_hakase/n/n5486e3a98997?magazine_key=m574f2e03ca50&from=membership-magazineComfyUIをクラウドで使い倒す! - Note,ComfyUIをクラウド環境,https://note.com/ai_hakase/n/n12b1ddf1e372?magazine_key=m574f2e03ca50&from=membership-magazine
🔗:https://note.com/ai_hakase/n/n12b1ddf1e372?magazine_key=m574f2e03ca50&from=membership-magazineComfyUIらくらくインストール - Note,ComfyUIをインストールする方法,https://note.com/ai_hakase/n/n0c099ec9f96e?magazine_key=m574f2e03ca50&from=membership-magazine
🔗:https://note.com/ai_hakase/n/n0c099ec9f96e?magazine_key=m574f2e03ca50&from=membership-magazineHugging Face (テキストエンコーダー) - Hugging Face,テキストエンコーダーモデル,https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/text_encoders
🔗:https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/text_encodersHugging Face (その他モデル) - Hugging Face,他のモデル,https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/diffusion_models
🔗:https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/diffusion_modelsHugging Face (VAEモデル) - Hugging Face,VAEモデル,https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/vae/wan_2.1_vae.safetensors
🔗:https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/vae/wan_2.1_vae.safetensorsReddit (LoRA) - Reddit,LoRAの強さも調整できる,https://www.reddit.com/r/StableDiffusion/comments/1j1w9s9/teacache_torchcompile_sageattention_and_sdpa_at/?rdt=36848
🔗:https://www.reddit.com/r/StableDiffusion/comments/1j1w9s9/teacache_torchcompile_sageattention_and_sdpa_at/?rdt=36848Reddit (VRAM 8GBでの動作) - Reddit,VRAM 8GB,https://www.reddit.com/r/StableDiffusion/comments/1j209oq/comfyui_wan21_14b_image_to_video_example_workflow/?rdt=37071
🔗:https://www.reddit.com/r/StableDiffusion/comments/1j209oq/comfyui_wan21_14b_image_to_video_example_workflow/?rdt=37071Comfy-Org/Wan_2.1_ComfyUI_repackaged at main - fp8モデルファイル,fp8モデルファイル,https://tinyurl.com/2afhlcb6
🔗:https://tinyurl.com/2afhlcb6split_files/clip_vision/clip_vision_h.safetensors · Comfy-Org/Wan_2.1_ComfyUI_repackaged at main- ComfyUI/models,clip_vision_h.safetensors,https://tinyurl.com/2xkhh8zc
🔗:https://tinyurl.com/2xkhh8zcHugging Face (画像→動画生成モデル) - Hugging Face,画像から動画を生成したい場合,https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/diffusion_models/wan2.1_i2v_480p_14B_bf16.safetensors
🔗:https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/diffusion_models/wan2.1_i2v_480p_14B_bf16.safetensors
ここから先は
この記事が参加している募集
この記事が気に入ったらチップで応援してみませんか?