
アメリカのトップ企業はどのように生成AIを導入・活用しているか?

昨今はさまざまな企業で生成AIの導入が進んでいますが、アメリカのトップ企業ではどのように生成AIを導入、使用、計画しているのでしょうか。「a16z」というベンチャーキャピタルがその状況をまとめ上げて調べてくれています。
自社に生成AIを導入する際にも非常に有用となるデータが含まれており、私にとっては非常に参考になる知見がたくさんありました。
ただ、非常に有用な内容ではあるものの、普段から生成AIに精通していない場合は理解が難しい部分もあるかと思いますので、本記事にて重要な部分について内容をかみ砕いて説明を付け加えながら解説いたします。
上記の記事は、アメリカのベンチャーキャピタル「a16z」がフォーチュン500企業やトップ企業のリーダー数十人と話し、さらに70人を調査し、取りまとめたものになります。
取りまとめた結果として、過去6か月の変化は驚くべきものでした。生成AIに対する予算をほぼ3倍に増やし、より小さなオープンソースモデルを使用して生成AIの適用業務の数を拡大し、初期の実験から本番環境への作業負荷の移行も進めているということです。
以下に具体的な内容を説明していきます。
1.生成AIへの予算は急上昇している
「2023年、私たちが話を聞いた数十社の企業を通じて、ChatGPTやGeminiなどの基盤モデルのAPI、セルフホスティング、モデルのファインチューニングにかかる平均支出が700万ドルでした。
さらに、私たちが話を聞いたほぼすべての企業が、生成AIの実験の初期段階で有望な結果を見ており、2024年にはこれらの支出を2倍から5倍に増やして、より多くの業務を本番環境に展開することを計画していました。」
説明
セルフホスティングとは、企業が自分たちのインフラストラクチャ上で直接モデルを運用している状況を指します。
セルフホスティングでは、オープンソースモデルを使用するか、企業が独自に開発したモデルを運用する場合がありますが、私の知る限り日本でセルフホスティングを行うケースはまだ少ないです。

2.トップ企業はAI投資を継続的なソフトウェア予算項目に再配分し始めている
「昨年、企業の生成AI支出の大部分は、驚くことなく「イノベーション」予算やその他の典型的な一回限りの資金提供から来ていました。
しかし、2024年には、多くの企業がその支出をより恒久的なソフトウェア項目に再配分しています。今年の生成AIの支出がイノベーション予算から来ると報告したのは、全体の1/4未満でした。
はるかに小規模ながら、顧客サービスにおいて、特に一部の企業が生成AI予算を人件費節約に対して使用し始めたのも見受けられます。この傾向が続けば、将来的に生成AIへの支出が大幅に増加する前兆と見ています。
ある企業は、LLMを活用した顧客サービスにより通話ごとに約6ドルの節約ができ、総コストの節約が約90%に達したとして、生成AIへの投資を8倍に増やす理由を挙げています。」

3.ROI(投資収益率)の測定に関しては、直感的な部分もあり、データ分析に基づく部分もある
「企業は現在、AIによって生成される生産性の向上によってROIを測定しています。NPS(*ネットプロモータースコア)や顧客満足度を良い代理指標として頼りにしている一方で、彼らは収益生成、節約、効率性、および精度の向上など、より具体的な方法でリターンを測定することを求めています。これはそれぞれのユースケースに依存します。近期的には、企業は依然としてこの技術を展開し、リターンを定量化するための最適な指標を見つけ出そうとしていますが、次の2〜3年間でROIはますます重要になります。
企業はこの問いに対する答えを模索ながらも、従業員が自分の時間をより良く利用していることを信じることにしています。」

説明
NPSは、Net Promoter Score(ネット・プロモーター・スコア)の略称です。顧客ロイヤルティや満足度を測定するために使用される指標の一つです。
NPSの計算方法は以下の通りです:
1. 顧客に対して、「あなたは当社のサービスを友人や同僚に推奨する可能性はどの程度ありますか?」という質問を、0(全く推奨しない)から10(必ず推奨する)までの11段階で評価してもらいます。
2. 回答者を以下の3つのグループに分類します:
- プロモーター(推奨者):9〜10と回答した顧客
- パッシブ(受動的満足者):7〜8と回答した顧客
- デトラクター(批判者):0〜6と回答した顧客
3. NPSを計算するために、デトラクターの割合をプロモーターの割合から引きます:
NPS = プロモーターの割合 - デトラクターの割合
NPSは-100から+100の範囲で表現され、高いスコアほど顧客ロイヤルティや満足度が高いことを示します。
企業はNPSを継続的に測定し、顧客体験を改善するための指標として活用します。
先進的な企業でもROIをしっかりと測定しているところは少ないようです。それにはROIの測定自体に人と時間のコストがかかるということもありそうで、今は方向性を信じて進んでいるというところが多いようです。
4.生成AIを実装およびスケーリングするには、適切な技術系の人材が必要だが、現在多くの企業ではその人材が社内にいない
「単にモデルプロバイダーへのAPIを持っているだけでは、生成AIソリューションを大規模に構築して展開するのに十分ではありません。必要なコンピューティングインフラを実装、維持、スケーリングするには、高度に特化した人材が必要です。実装だけで、2023年のAI支出の最大の領域の一つを占め、場合によっては最大でした。ある経営者は「LLMは、生成AIを業務に適用させてケースを構築する際のコストの約4分の1です」と述べており、開発コストが予算の大部分を占めています。
企業が自社のモデルを稼働させるために、基盤モデルプロバイダー(OpenAIやGoogleなど)は、カスタムモデル開発に関連するプロフェッショナルサービスを提供し、現在も提供し続けています。私たちは、これが2023年のこれらの企業の収益のかなりの部分を占めたと推定しており、パフォーマンスに加えて、企業が特定のモデルプロバイダーを選択した主要な理由の一つです。企業内で適切な生成AIの人材を得ることが非常に困難であるため、生成AIの開発を社内に取り入れやすくするツールを提供するスタートアップは、おそらくより迅速な採用を見ることでしょう。」
説明
上記については非常によい考察だと思います。実際、多くの企業ではLLMを使用するコストなどを気にすることが多いですが、それ以上に重要なのはどうやって業務適用させるかという部分です。この部分について考えずにただLLMを導入するだけではそれに見合った使い方をすることは非常に困難になると予測されます。
5.マルチモデルの未来
「わずか6ヶ月前、大多数の企業は1つのモデル(通常はOpenAI系)か、多くても2つのモデルでテストしていました。しかし今日、企業の経営者たちと話をすると、彼らはすべて複数のモデルをテストしており、場合によっては本番環境で使用しています。これにより、彼らは1) パフォーマンス、サイズ、コストに基づいて適用業務に合わせる、2) 1つの企業に頼りきることを避ける、3) 素早くこの急速に進化する分野の進歩を取り入れることができます。この第3のポイントはリーダーにとって特に重要であり、モデルのリーダーボードは動的であり、企業は最新の最先端モデルとオープンソースモデルの両方を取り入れて最良の結果を出すことに興奮しています。」

「さらに多くのモデルが普及することが予想されます。下記の表は、調査データから作成されたもので、企業のリーダーたちはテスト中のモデル数を報告しており、これは本番環境でのワークロードに使用されるモデルの先行指標となります。本番利用のユースケースでは、予想通りOpenAIが依然として支配的な市場シェアを持っています。」

説明
ChatGPTのOpenAIが非常に強いものの、GoogleやLlamaなどの台頭が見て取れます。また、このレポートを作成しているときはまだClaude 3が発表されていなかったようですので、Claude 3がある今ではAnthropicが伸びてきていることは容易に想像できそうです。
OpenAIは確かに非常に強いですが、それだけに頼らない方向で各企業が動いているのですね。
6.オープンソースが急成長している
「これは過去6ヶ月間の変化の中で最も驚くべき変化の一つです。2023年の市場シェアは80%~90%がクローズドソースで、その大部分がOpenAIに帰属していると推定しています。しかし、調査回答者の46%が2024年に入ってオープンソースモデルを好む、あるいは強く好むと言及しました。インタビューでは、AIリーダーの約60%が、オープンソースの使用を増やすことや、ファインチューニングされたオープンソースモデルがクローズドソースモデルの性能におおよそ匹敵した場合に切り替えることに興味があると指摘しました。したがって、2024年以降、企業はオープンソースへの使用の大幅なシフトを期待しており、一部は明確に2023年の80%クローズド/20%オープンの割合から50/50の分割を目指しています。」

説明
現時点で、日本ではオープンソースの利用の傾向はほとんど見受けられませんが、今後そちらの方向にシフトしうる可能性は十分あり得そうです。また、日本の場合、日本語のLLMなども少しずつ盛り上がってきているので、それらには目を光らせておいた方がよいかもしれません。
7.オープンソースにとって、コストは魅力的な要素だったが、重要度としてはコントロールとカスタマイズより下に位置づけられた
「制御(独自のデータのセキュリティとモデルが特定の出力を生成する理由の理解)とカスタマイゼーション(特定のユースケースに対して効果的にファインチューニングする能力)は、オープンソースを採用する主な理由としてコストをはるかに上回りました。コストが最優先事項ではなかったことに私たちは驚きましたが、それはリーダーシップが現在、生成AIによって生み出される付加価値がその価格を大きく上回る可能性が高いという確信を反映しています。ある経営者は次のように説明しました。”正確な回答を得ることがお金に値する。”」
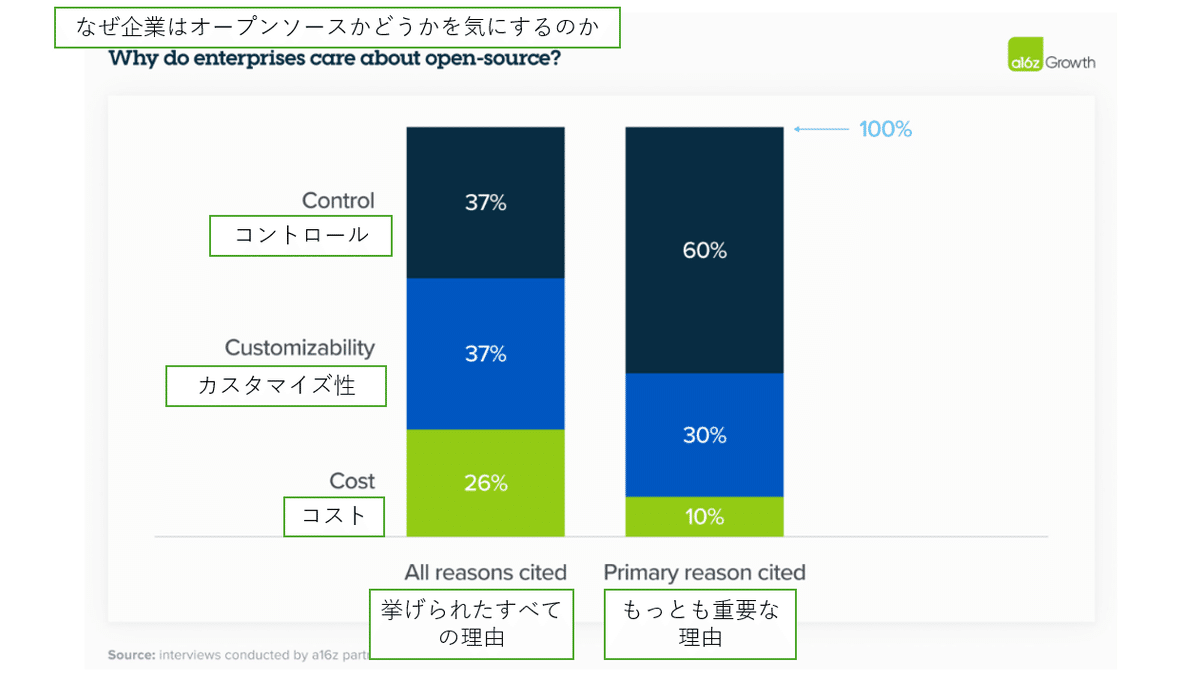
説明
多くの企業は、生成AIが正しくコントロール、カスタマイズすることができれば、その価値が非常に高くなるということに確信を得ているようです。
8.コントロールへの要求は、機密性の高いユースケースと企業データのセキュリティに関する懸念から生じている
「企業は、規制やデータセキュリティの懸念から、独自のデータをクローズドソースのモデル提供者と共有することに依然として心地よいと感じてはいません。そして驚くべきことではありませんが、知的財産がビジネスモデルの中心である企業ほど特に保守的です。
一部の企業はこの懸念に対処するために、オープンソースモデルを自社でホスティングするという方法を取りましたが、他の企業は仮想プライベートクラウド(VPC)統合を備えたモデルを優先していると指摘しました。」
9.企業は、一般的にモデルをゼロから構築するのではなく、ファインチューニングを通じてモデルをカスタマイズする
2023年には、BloombergGPTのようなカスタムモデルの構築に関する多くの議論がありました。2024年においても、企業はモデルのカスタマイズに興味を持っていますが、高品質なオープンソースモデルの台頭により、ほとんどの企業は自分たちのLLMをゼロから訓練するのではなく、検索拡張生成(RAG)を使用するか、特定のニーズに合わせてオープンソースモデルをファインチューニングすることを選択しています。」

説明
2024年3月に発表された、金融専門のBloombergGPTです。↓
ファインチューニングとは、特定のタスク用のデータセットで事前学習済みのモデルに追加学習を行います。その結果、モデルは特定のタスクに関連する知識を獲得し、そのタスクでの性能を向上させることができます。
例えると、大学生(事前学習済みのモデル)に法律のことを勉強させ、法律に詳しくさせるようなイメージです。
RAGとは、外部ナレッジベースから情報を検索して言語モデルに提供します。
例えると、大学生(事前学習済みのモデル)に六法全書を渡して、そのモデル自身が法律に詳しいわけではないけれども法律に関する知識で装備させるイメージです。
ファインチューニングは、データの準備であったり、その結果の確認にコストが高くなりがちだと思われますがインタビューの企業ではファインチューニングが多いのは意外でした。
10.クラウドはモデル購入の決定において依然として大きな影響力を持っている
「2023年、多くの企業がセキュリティ上の理由から既存のクラウドサービスプロバイダー(CSP)を通じてモデルを購入しました。企業は、CSPよりもクローズドソースモデルがデータを誤って扱うことにより懸念を抱いており、CSPを変更する手続きを避けるためでもありました。
この状況は2024年も変わっておらず、CSPと好まれるモデルとの間にはかなり高い相関関係があります:Azureのユーザーは一般的にOpenAIを好み、AmazonのユーザーはAnthropicやCohereを好む傾向にあります。下記のチャートから分かるように、APIを使ってモデルにアクセスする企業の72%のうち、半数以上がCSPにホストされたモデルを使用しています。(1/4以上の回答者がセルフホスティングを行っており、これはおそらくオープンソースモデルを実行するためです。)」

11. 顧客は依然として市場投入の早さを重視している
「企業は、あるモデルを採用する上での主要な理由として推論能力、信頼性、アクセスの容易さ(例えば、自社のCSP上で)を挙げていますが、他にも差別化された特徴を持つモデルにも関心を示しています。例えば、複数のリーダーがAnthropicを採用した主要な理由として、以前の200Kコンテキストウィンドウを挙げています。一方、市場投入の早さや使いやすいファインチューニングの提供を理由にCohereを採用している企業もあります。」
12. それにもかかわらず、ほとんどの企業はモデルの性能が収束していると考えている
「AI技術業界では、モデルの性能を公開ベンチマークと比較することに焦点を当てていることが大部分です。一方で、企業の経営者は、ファインチューニングされたオープンソースモデルとファインチューニングされたクローズドソースモデルの性能を、自社の内部ベンチマークセットで比較することの方により重要視しています。興味深いことに、クローズドソースモデルが外部のベンチマーキングテストで一般に優れた性能を示すにもかかわらず、企業の経営者はオープンソースモデルに比較的高いNPS(かなり高い場合もある)を与えています。
その理由は、特定のユースケースに対してファインチューニングが容易だからです。ある企業は、「ファインチューニング後、MistralとLlamaはOpenAIとほぼ同じくらいの性能を発揮するが、はるかに低いコストである」と発見しました。これらの基準によれば、モデルの性能は私たちが予想していたよりもさらに迅速に収束しており、リーダーたちに非常に能力の高いモデルの幅広い選択肢を提供しています。」
説明
新しいモデルが出てくれば、再度ファインチューニングをしなければならず、それにもそれ相応のコストがかかるはずなのですが、モデルの性能が収束していると考えているのであればファインチューニングを実施していることに納得できます。
また、コストが高いChatGPT-4を使用するよりもファインチューニングされたMistralを使う方がコスト的にもメリットがあります。


13. 選択肢の最適化
「ほとんどの企業は、モデル間の切り替えがAPIの変更だけで済むように、アプリケーションを設計しています。一部の企業では、切り替えが文字通りスイッチ一つで行われるよう、事前にプロンプトをテストしているところもあります。また、別の企業では、”モデルガーデン”を構築し、必要に応じて異なるアプリにモデルをデプロイできるようにしています。
企業がこのアプローチを採用しているのは、クラウド時代からプロバイダーへの依存を減らす必要性について苦い教訓を学んだ部分もあれば、市場が非常に速いペースで進化しているため、単一のベンダーにコミットするのが賢明でないと感じている部分もあります。」
14. 現在、企業はアプリを購入するのではなく、構築している
「企業は圧倒的に、自社内でアプリケーションを構築することに集中しています。実践的に認められ、カテゴリを破壊するような画期的な企業向けAIアプリケーションがまだ出現していないことをその理由の一つとして挙げています。結局のところ、このような、アプリに対して業界を標準化する指標や市場調査レポートは(まだ)存在しません。
基盤モデルはAPIを提供することで、企業が自社のAIアプリをこれまで以上に簡単に構築できるようにもしました。企業は、顧客サポートや内部チャットボットなど、おなじみのユースケースの自社版を構築する一方で、消費財の配合や製造方法作成、分子発見のフィールドの絞り込み、販売推奨のような、より新しいユースケースの実験も行っています。「GPTラッパー」、つまり、よく知られたLLMの出力(例:ドキュメントの要約)に対するおなじみのインターフェース(例:チャットボット)を構築するスタートアップの限られた差別化について多くが書かれていますが、AIが自社内で類似のアプリケーションを構築する障壁をさらに低くしたため、これらが苦戦すると私たちは考えています。
しかし、より多くの企業向けAIアプリケーションが市場に出ると、この状況が変わるかどうかはまだ結論が出ていません。
ある企業経営者は、多くのユースケースを自社で構築しているにも関わらず、「新しいツールが登場するだろう」と楽観視しており、「そこにある最良のものを使いたい」と述べています。
別の経営者たちは、生成AIが、今まで行ってきたように外部ベンダーに依存するのではなく、特定の機能を自社内に取り込むことを可能にする”戦略的なツール”となっていると信じています。
これらのダイナミクスを考えると、「LLM + UI」の公式を超えて革新し、企業の基本的なワークフローを大幅に再考するか、企業が自社の独自データをより良く活用するのを促進するアプリは、この市場で特にうまくいくと我々は考えています。」
説明
文中で挙げられている「おなじみのユースケース」とは、「顧客サポート」や「内部チャットボット」などです。顧客サポートは、顧客の問い合わせに対応し、問題解決を助けるサービスを提供することを指し、内部チャットボットは、従業員が社内の情報を簡単に検索したり、日常の業務を効率化するために利用されます。
これに対して、文中で「より新しいユースケースの実験」と言及されている部分は、従来よりも創造的で、まだ一般的ではない応用例に企業が取り組んでいることを示しています。これらには、「writing CPG recipes(消費財の配合や製造方法作成)」、「narrowing the field for molecule discovery(分子発見の範囲を絞る)」、「making sales recommendations(販売推薦を行う)」などが含まれます。
企業がAI技術を活用して既存のプロセスを強化すると同時に、より革新的なユースケースの探求し、企業が新たな価値を生み出し、競争優位性を確立するチャンスをうかがっているようです。
15. 企業は内部ユースケースについては熱中しているが、外部ユースケースについてはより慎重な姿勢を保っている。
「企業における生成AIに関する2つの主要な懸念が依然として大きく影響しています。
1つ目は、ハルシネーション(生成AIが事実にそぐわない回答をすること)や安全性に関する潜在的な問題、2つ目は、特に敏感な消費者セクター(例えば、ヘルスケアや金融サービス)への生成AIの展開に関する公共関係の問題です。
昨年最も人気のあったユースケースは、内部生産性に焦点を当てたものや、顧客に届く前に人間を介して処理されるもの(例えば、コーディングのコパイロット、カスタマーサポート、マーケティング)でした。
下のチャートで見ることができるように、これらのユースケースは2024年においても大半を占めており、企業はテキスト要約やナレッジマネジメント(例えば、内部チャットボット)のような完全に内部向けのユースケースを、契約レビューや外部向けチャットボット、推薦アルゴリズムのような敏感な人間介入ユースケースや顧客向けユースケースよりもはるかに高い割合で本番環境に移行しています。
企業は、エアカナダのカスタマーサービスの失敗のような生成AIのトラブルから生じる不祥事を避けたいと考えています。これらの懸念がほとんどの企業にとって依然として大きな問題であるため、これらの問題を制御するためのツールを構築するスタートアップは、大きな採用を見る可能性があります。」

説明
エアカナダのカスタマーサービスの失敗とは、以下の件のことです。
Air CanadaのカスタマーサービスにおけるAIチャットボットの問題について、以下のように要約できます:
- Air Canadaは自社のウェブサイト上にAIチャットボットを導入し、顧客の問い合わせに対応していた。
- ある顧客が、親族の死亡に伴う割引制度について問い合わせたところ、チャットボットが誤った情報を提供した。
- 顧客はチャットボットの指示に従って割引付きの航空券を購入したが、後に航空会社から割引は適用されないと告げられた。
- 顧客が裁判所に訴えたところ、裁判所はAir Canadaに対して、チャットボットが提示した割引を適用するよう命じた。
- Air Canadaは自社のチャットボットを「別の法的主体」だと主張し、責任を回避しようとしたが、裁判所はこの主張を退けた。
- この事例を通して、AIチャットボットの誤情報提供が企業にとって大きな問題となりうることが示された。企業はAIの利用に慎重にならざるを得なくなっている。
つまり、Air Canadaのチャットボットの誤情報提供が企業の責任となり、大きな問題を引き起こしたということが分かります。
Citations:
[1] https://www.cmswire.com/customer-experience/exploring-air-canadas-ai-chatbot-dilemma/
[2] https://www.themarysue.com/air-canada-claims-its-not-responsible-for-its-own-chatbots-hallucinations/
[3] https://news.ycombinator.com/item?id=39455131
[4] https://arstechnica.com/civis/threads/air-canada-must-honor-refund-policy-invented-by-airline%E2%80%99s-chatbot.1498930/
[5] https://interestingengineering.com/culture/air-canada-ai-chatbot-debacle
多く企業が内部で実際に運用を行って十分に経験をためてから外部向けにしようする方向性のようですね。
16. モデルAPIとファインチューニングへの総支出は、2024年末までに50億ドルの実績ベースで成長すると我々は信じており、企業の支出がその機会の大きな部分を占めることになるだろう。
「私たちの計算によると、モデルAPI(ファインチューニングを含む)市場は2023年末に約15億~20億ドルの実績ベース収益で終了したと推定されます。これには、Azureを介したOpenAIモデルへの支出も含まれています。全体市場の予想される成長と企業からの具体的な示唆を考慮すると、この分野への支出は年末までに少なくとも50億ドルの実績ベースに成長し、さらなる上昇の可能性があります。私たちが議論したように、企業は生成AIの展開を優先し、予算を増やし標準的なソフトウェアラインへと再配分し、異なるモデルを横断するユースケースを最適化し、2024年にはさらに多くのワークロードを本番環境に移行する計画をしています。これは、企業がこの成長の大きな部分を推進する可能性が高いことを意味します。
過去6ヶ月の間に、企業は生成AIソリューションを見つけて展開するためのトップダウンの命令を出しました。以前は1年以上かかっていた取引が、2か月や3か月で推進され、それらの取引は過去に比べてかなり大きくなっています。
こちらの記事は基盤モデル層に焦点を当てていますが、私たちはこの機会が関連する技術やサービスにも広がっているとも考えています。それには、ファインチューニングを助けるツールから、モデル提供、アプリケーション構築、そして特定用途に作られたAIネイティブアプリケーションに至るまでが含まれます。
私たちは企業における生成AIの変曲点にあり、このダイナミックで成長している市場にサービスを提供する次世代の企業とパートナーシップを結ぶことに興奮しています。」
説明
企業が生成AIソリューションを見つけて展開するプロセス全体が、単にモデル(ChatGPTやGemini, Claudeなど)を使用することだけでなく、それらのモデルをどのように効率的に統合し、最終的な製品やサービスに落とし込むかという広範囲に広がっていることを示しています。
このアプローチによって、企業は自社のニーズに最適化されたAIソリューションを開発し、競争力を高めるための柔軟性と能力を提供することが可能になります。
いいね!やフォローで、ぜひ応援よろしくお願いします!
励みになります!
また、X(旧Twitter)でAIについての雑談を不定期に行っておりますのでフォローをお願いいたします。