
Day11&12&13&14_AzureDataFactoryの続きとPowerBI【備忘録】

始まる前に少しカンパ先生からあった解説。
Azure Data Factoryのデータフローにおける「sink(シンク)」は、データの出力先を意味します。データは「ソース」から取り込まれ、さまざまな変換や処理を経て、最終的に「シンク」に書き出されます。
クラウドサービスでは従量課金制を採用しているため、処理が完了したデータのみが保存されます。途中段階のデータを自動的に保存すると、その分も課金対象となってしまうため、自動保存は行われません。これにより、未完成のデータによる不要なコスト発生を防いでいます。
またデータレイクとデータウェアハウスを分かりやすく説明するために、2つを「大量の積本」と「本棚」に例えて解説を試みます。
データレイク=大量の積本
データレイクは、部屋に無造作に積み上げられた大量の本の山のようなものです。
これらの本(データ)はジャンルや種類を問わず混在しており、あるものは整理されているかもしれませんが、多くはそのままの状態で積まれています。
専門書、漫画、小説、雑誌などが一緒くたになっており、必要な本を見つけ出すには時間と労力が必要となります。
つまり、データレイクは大量の未処理データをそのままの形式で保存し、後で必要に応じて取り出し、処理・分析できるものと解釈することが出来ます。
すべてのデータが「そのままの形で保管」されている点がポイントです。
データウェアハウス=仕分けされた棚
一方、データウェアハウスは、きちんと仕分けされた棚に整理された本のようなものです。
ジャンルやテーマごとに本が並べられ、ラベルや番号が付けられているため、探したい本をすぐに見つけることができます。
この棚にある本は、特定の目的や利用のために事前に分類・整理されており、必要な情報に迅速にアクセスできます。
つまり、データウェアハウスは、整理されたデータを格納し、効率的にレポート作成や分析を行うためのデータベースであり、データが「整理されて」保存されています。
【注意点】データウェアハウスでのデータ欠損
データウェアハウスでは、データを事前に整理・加工して保存するため、元のデータから一部の情報が除外される可能性があります。
不要と判断されたデータや形式に合わないデータが削除されることで、後から必要になる情報が欠落し、分析結果に影響を与えるリスクがあります。
この例から分かるように、データレイクは柔軟性が高いものの、データの整理や検索には手間がかかります。
一方、データウェアハウスは、特定の目的に最適化されたデータを迅速に扱えますが欠損データが発生してしまう可能性があります。
前回までのAzureDataFactory利用の続き
前回の状態からのスタートになります。
まだの方はDay10からの見直しが必要です。
まずは前回の状態から始めますが、データフローのデバックが出来ていなければ、それを操作しておきましょう。
下記の様に前回つくった新しい列が出ている状態を確認します。
データフローのデバッグって、つまり何のこと?(僕なりの解釈)
デバッグ=プログラムやデータ処理において発生するエラーや問題点を見つけて修正する作業。
つまり、処理が正しく動作しているかを確認し、不具合を取り除くためのプロセスを指す。作業が正しく行われているかをテストする機能。各ブロックでデータがどのように変化するかをリアルタイムで確認できる。エラーや問題を作業工程ごとに発見し、それに応じて修正が可能。運用本番となる前段階でデータフローを検証しながら作成することができる。
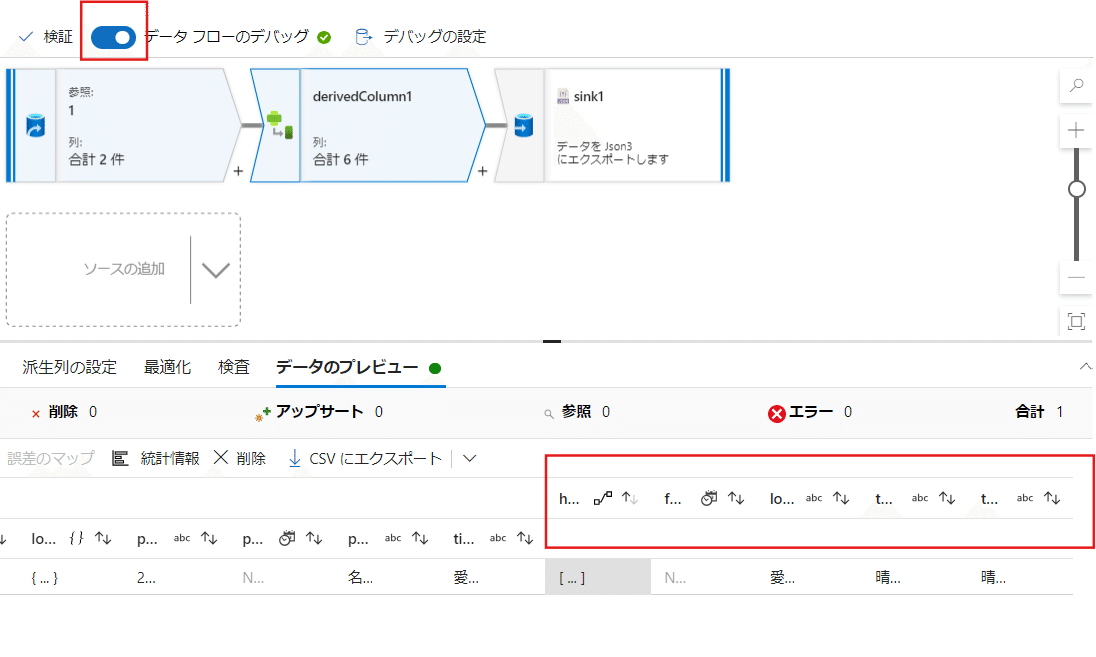
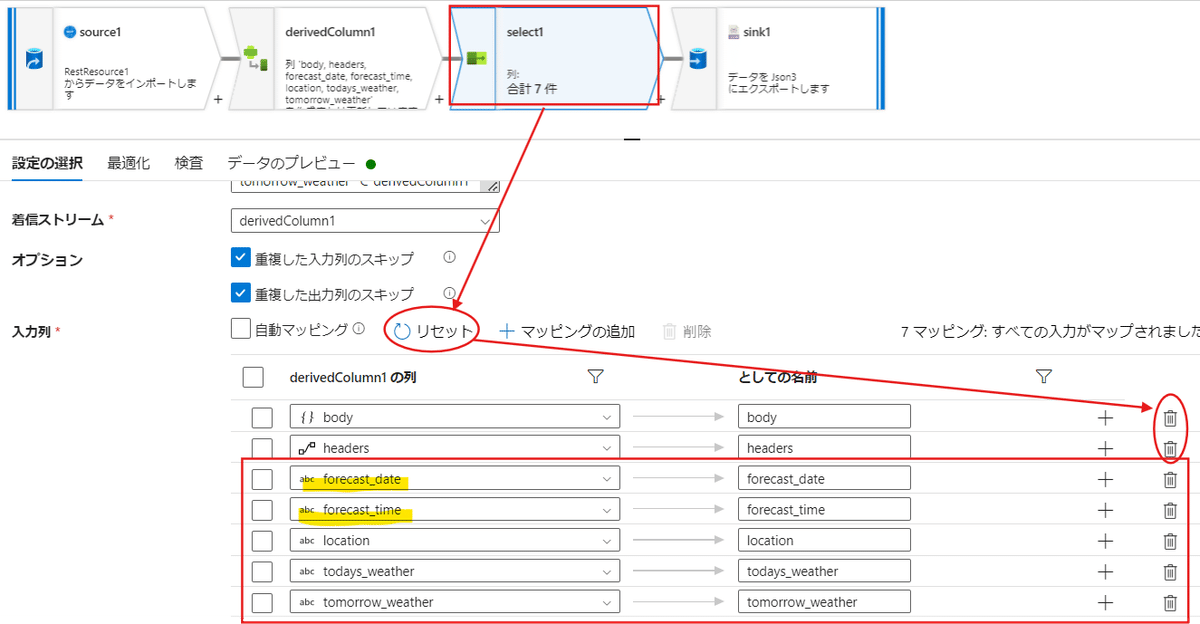
ここから、次は選択を行って必要な列だけを残す手順を行います。

付け足すと第一階層に何が記されているかが出てきます。

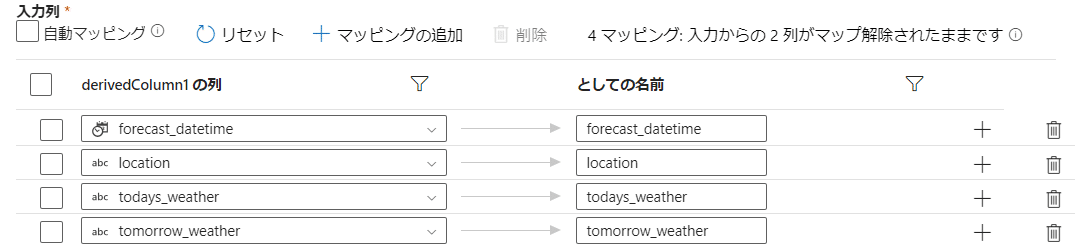
「としての名前」はどう表示するかという意味になります。
※Asを意味するものでSQL(後述)の名前変換などに使われるとのこと。
【ワンポイント調べ】
DataFactoryでの「としての名前」は、SQLのASと同じように、別名を付けることを意味します。データフローの中で、特定のデータ列や変数に対して別名を付けて扱う際に使われます。これにより、後の処理や表示でその名前を使ってデータを簡潔に参照できます。
今回は【body】と【headers】は不要なので、右のゴミ箱マークで捨ててしまいましょう。

表示としては残るのが下記画像の4つとなります。
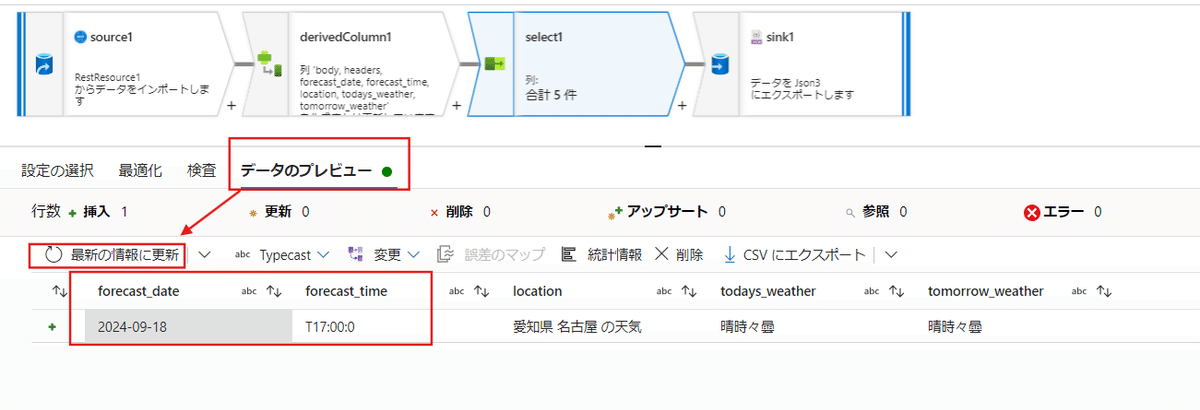
データのプレビューを最新にすると、必要な項目だけが残されて表示されるようになりました。
こういった形で状況確認が工程の途中で出来るのも、先のデータフローのデバックを行っていたからです。
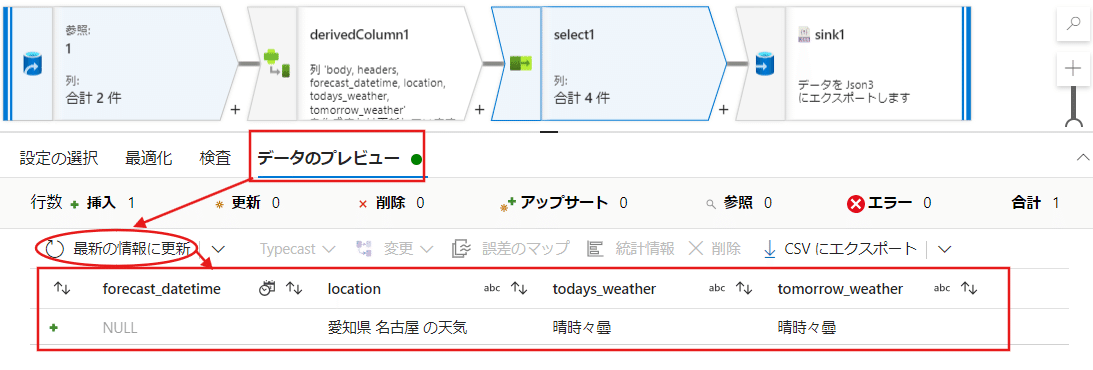
今回は元の天気予報APIから取得したデータが4つの項目で整理された状態に変換されたことになります。
もし必要なデータが他にある場合は、元データであるデータレイクから変換の手順を変えていく必要があります。
NULLがあるデータ部分を修正していく
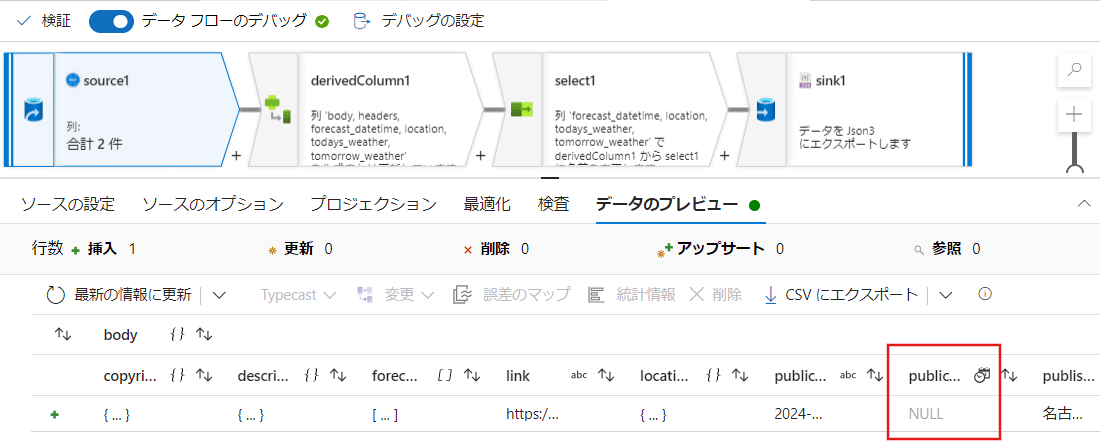
今はNullと表示されているデータがあります。
それを修正していきましょう。
Null(ヌル)は「値が存在しない」または「未定義」であることを示す。空やゼロとは異なります。
例えば、ある銀行口座があったとして、まだ何も入力されていない状態が「空」となります。
そして残高0円が「ゼロ」を意味します。
Nullは「口座そのものがない」ような状態を指します。
【端的に言うと】
Null=データの不存在
空=データが未入力
ゼロ=0というデータ
今回は、元データの中から取れている左側のpublicTimeから情報を取るようにします。
これをderivedColumnから修正を行います。
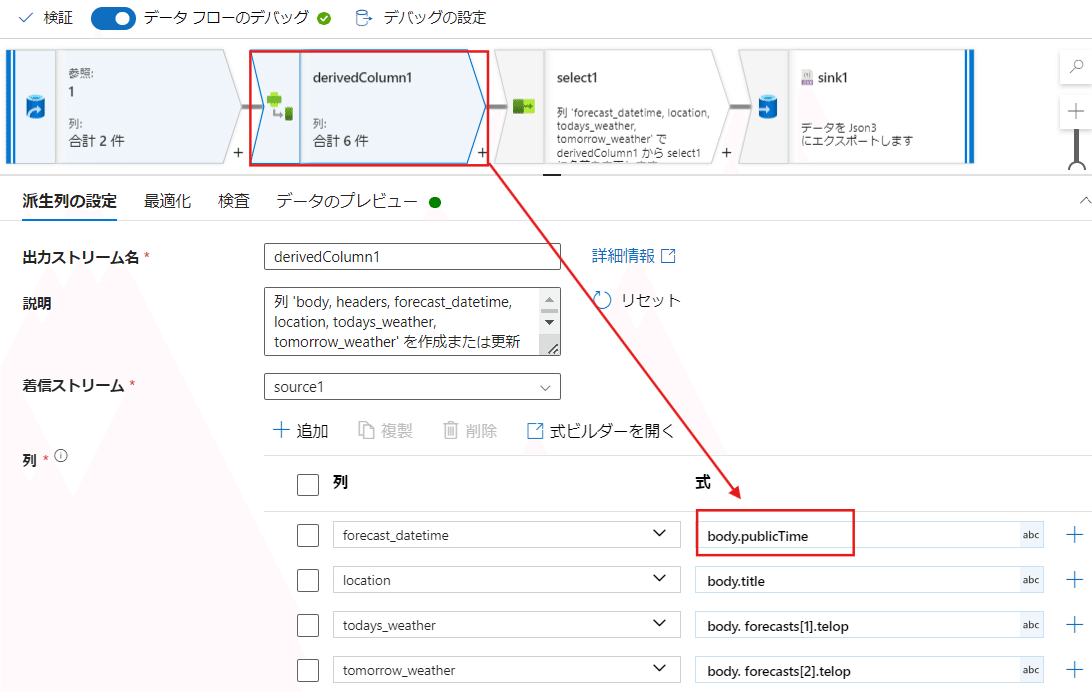
Nullだった時間が修正されて表示されるようになりました。
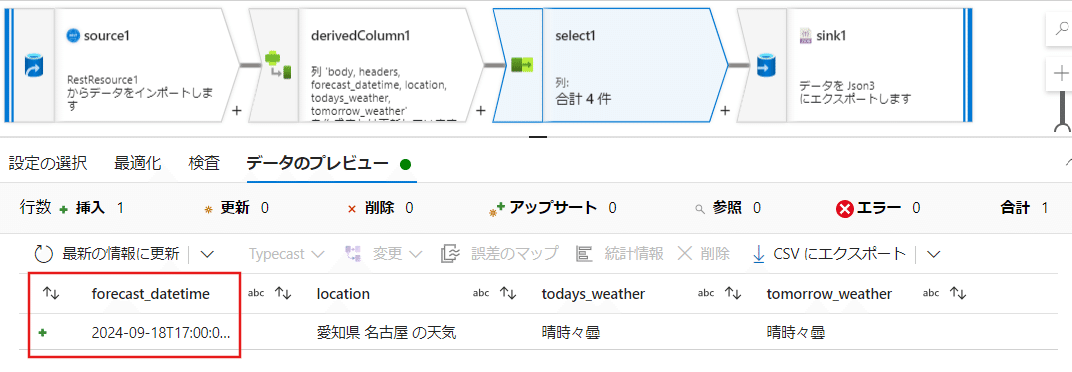
日付と時間を分離させて表示させる
どうやればいいのか分からない時、Googleで検索するのが今までの流れだったと思います。
しかしながらマイナーな作業を行っている場合は調べても最適解が出ない可能性もあります。
その場合はChatGPTに聞いて確認してみましょう。
※特にプログラミング類に強いと言われるChatGPTなので、積極的に利用してみると良いです。
一度でChatGPTが正しい回答が出るか分からないので、エラーが出たら修正を依頼して何度も試すことになります。
今回は僕が成功した数式の下記を利用します。
カンパ先生がSlackでも表示しているので、それを利用しても良いです。
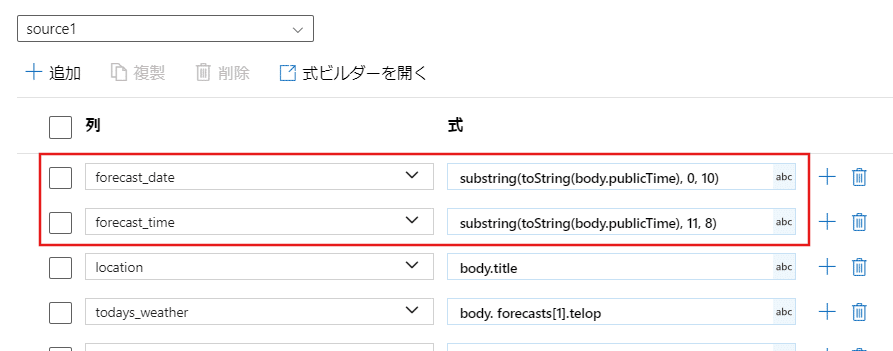
●日付だけを表示する
substring(toString(body.publicTime), 0, 10)
●時間だけを表示する
substring(toString(body.publicTime), 11, 8)【式ビルダーを開く】からコードを入れられるページを開きます。
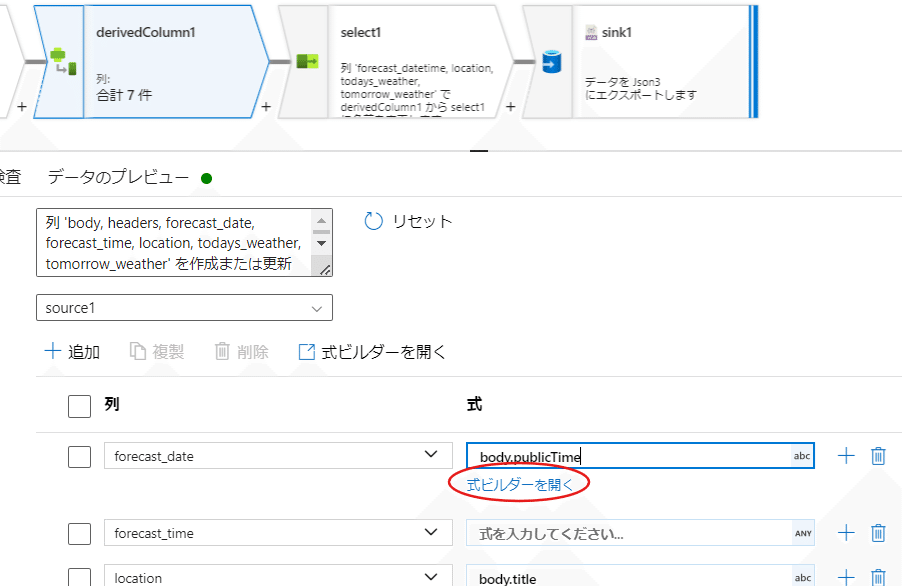
この式の部分にChatGPTに指示されたものを入れます。

timeの方も同じ様に実施しましょう。
それが出来たら、次に【設定の選択】を一度リセットして、新たな【forecast_date】と【forecast_time】を残して、完了です。
データのプレビューを行うと、日付と時間が分離された状態で表示されているのが分かったと思います。
ChatGPTに作業を依頼することで、たとえば時間の部分の「T」の表示や、ロケーションの「の天気」を「天気」に修正することも出来ます。
ここは作業工程が分かりやすいように、新たなブロックを作って表示を変化させています。
(同じ様にこれに該当する数式をChatGPTが教えてくれます)

SQLデータベースを作る
次にデータベースを作ります。
データベースと、前回作ったコンテナは概念が違うものとなります(まっちゃんさんの質問から)。
コンテナ=データレイク。生のデータを管理している。
例:「大量の積み上げられた未整理の本」
データベース=整理されたデータを管理している。
例:「整理された本棚」
※ちなみにデータウェハウスは更に必要な情報が統合されたもので、言ってみれば「ビジネス分析のために整理された大規模な書店」のイメージです。
今回作るのはSQLと呼ばれるデータベースです。
SQLはテーブル形式(エクセルのような形)で構造管理するデータベース。WEBサイト作成をしたことがある人ならMySQLというデータベースを聞いたことがあるかもしれません。
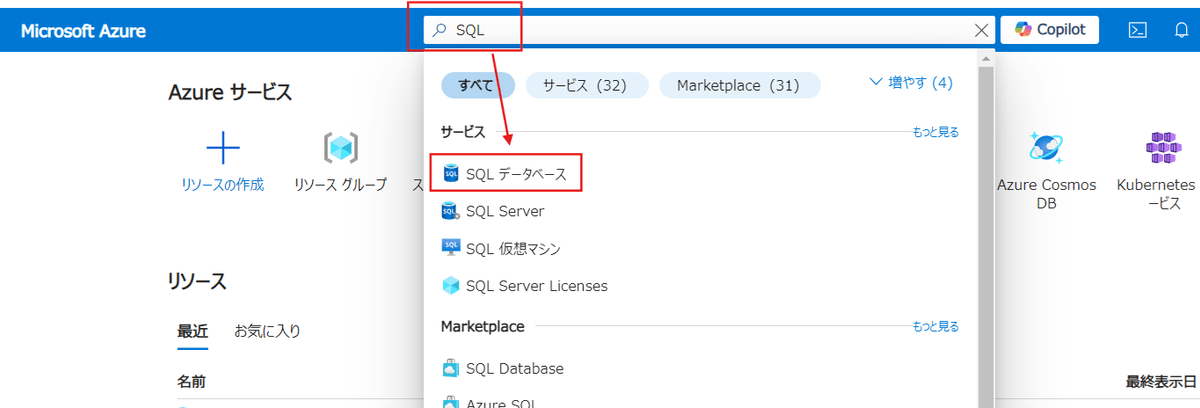
まずはAzureポータルのトップ画面から検索窓に「SQL」と入力し、SQLデータベースを選択する。
SQLデータベースを新規で作成します。
リソースグループはいつも通り、自分のものを検索して入力。
次にデータベース名も本来は分かりやすくプロジェクト名などにしますが、今回はai1stとして名前と番号を入れておきます。
そして【サーバー】の部分のみ新規作成を選択しましょう。
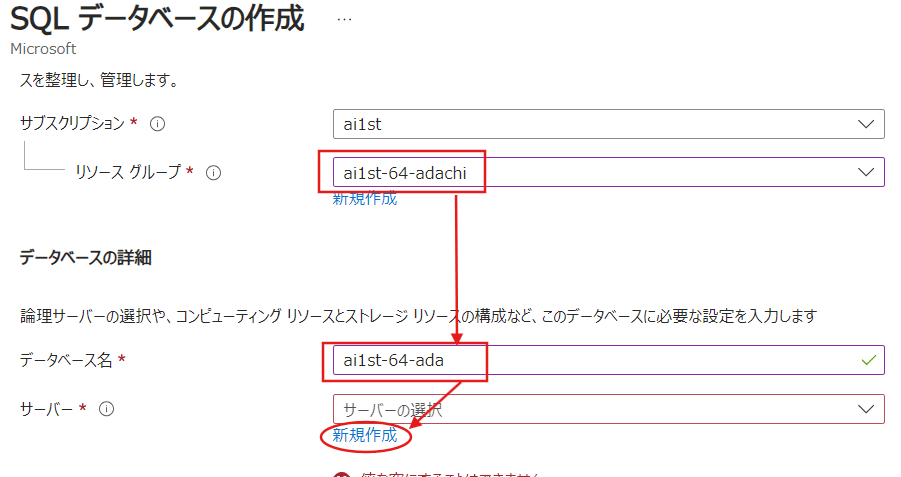
サーバー名は過去の入力(世界の誰とも)と被らないものを入力します。
今回はいつも通りai1stから番号と名前を入れています。
そして場所は自分の住所と近い場所にしておきましょう。

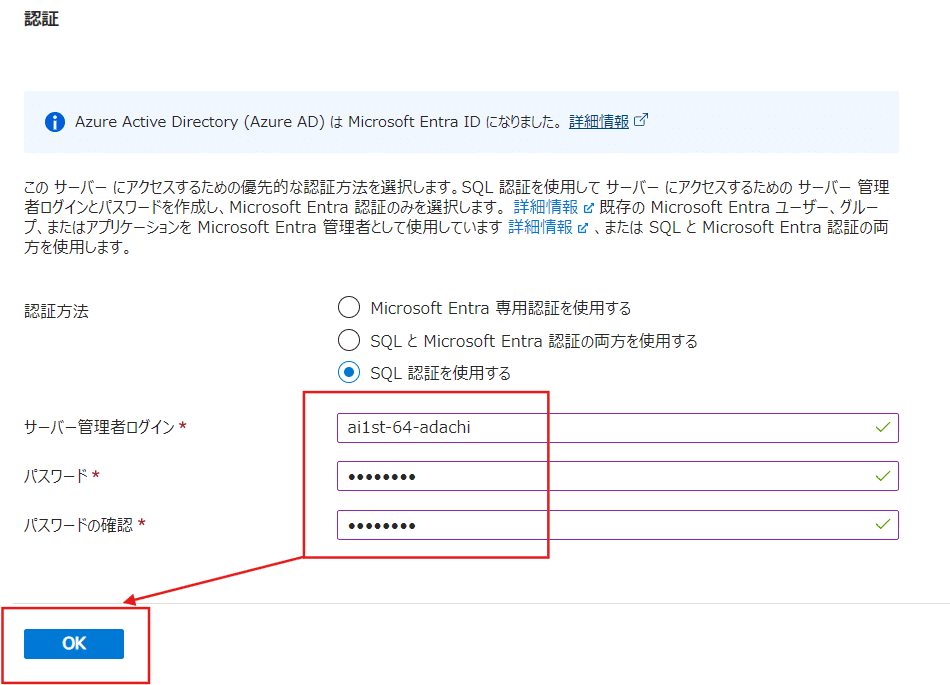
下にスクロールしていき、認証を今回は【SQL認証】を使用します。
要するにIDとパスワードによる認証です。
※IDとパスワードを忘れないように(パスワードは生成ツールを検索して利用すればOKです)
次に表示される部分で【ワークロード環境】については確実に【開発】にしておきます(金額が上がるため)。
次にコンピューティングとストレージについては【汎用目的】になっているかを確認しましょう。
その確認が終わったら【確認および作成】を押します。
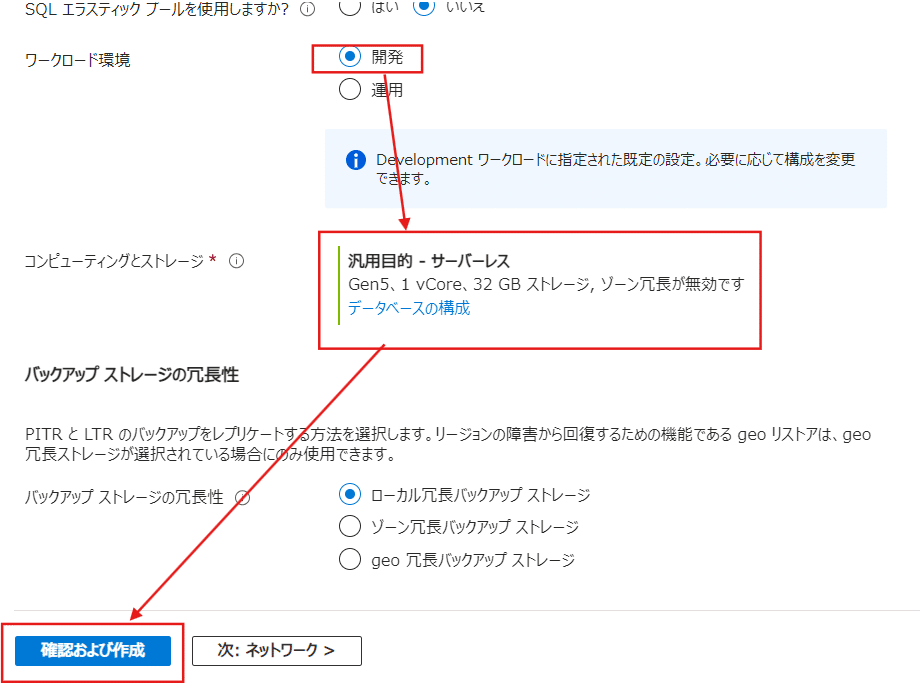
確認の画面で右側に推定の費用が出ているので確認しておきましょう。
問題が無ければ【作成】を実施。

デプロイが進行するので、待機です。
デプロイとは、ソフトウェアを開発環境から実際に利用される本番環境に移すプロセスを指す。要するに、作ったソフトウェアをユーザーが実際に使えるようにすることです。
完了画面が出たらこれでMicrosoft社のサーバーの中に自分の使うリソース部分を手にしたことになります。
確認したらリソースに移動します。

作成したSQLが出来上がっていることを確認しましょう。

次にSQLへのアクセスを許可する権限付与を行います。
まずAzureポータルのメイン画面を表示させましょう。
その中で自分自身の【リソースグループ】を選択します。
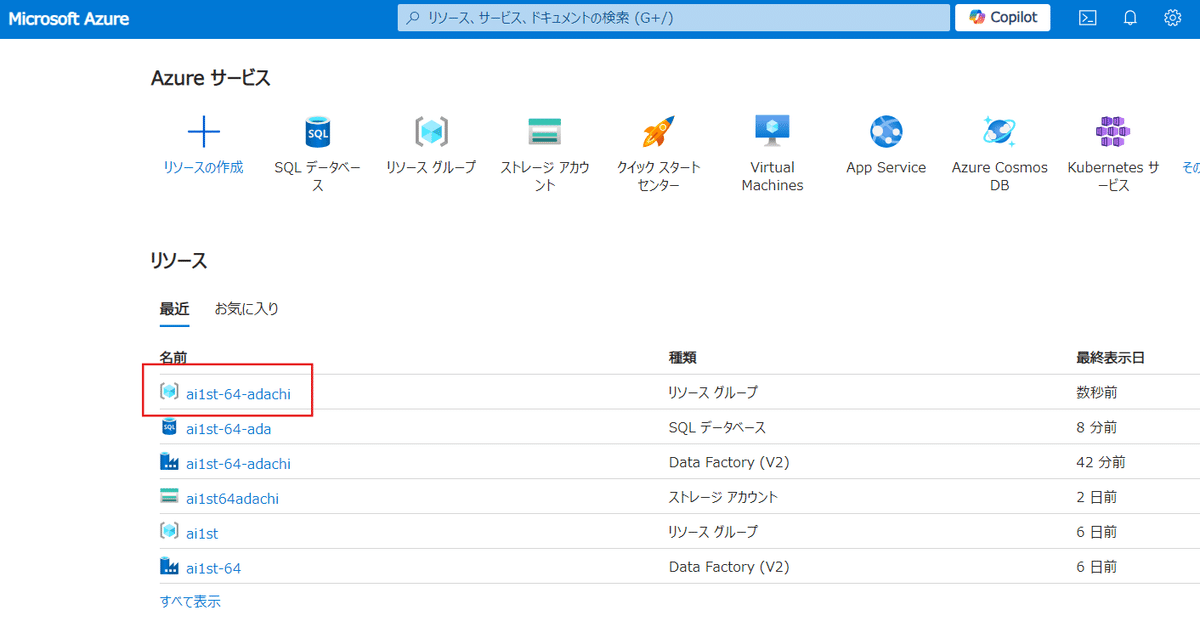
そこで新たに、先程つくったSQLデータベースと、SQLServerが出来ています。
この【SQLServer】の方を選択します。

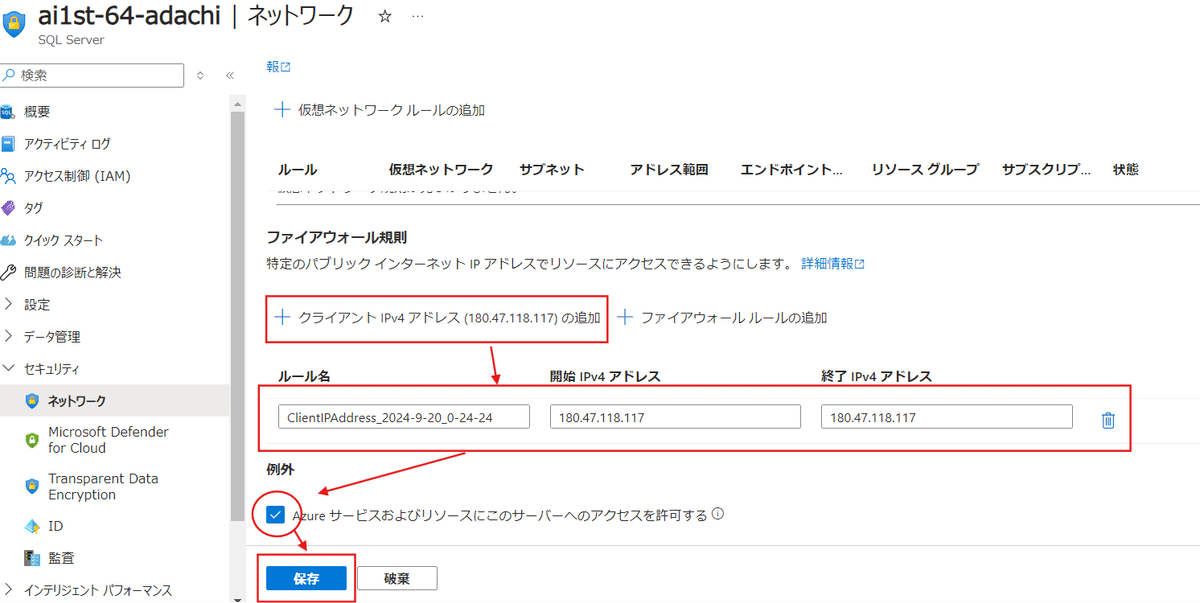
SQLServerの中の【セキュリティ】タブから【ネットワーク】を選択します。
デフォルトでは【無効化】になっているので、ここで【選択したネットワーク】を選択しましょう。
これによって「アクセス出来ません」という状態から「この環境からなら接続可能」という状態に変更できます。

画面をスクロールして【ファイアウォール規則】にある【クライアント~】を選択して、今接続している環境からのアクセスを許可します。
次に【Azureサービスおよびリソースにこの~】の部分にチェックを入れます。
それが出来たら【保存】を選択しましょう。
これで今の環境下でもSQL上の作業が可能になりました。
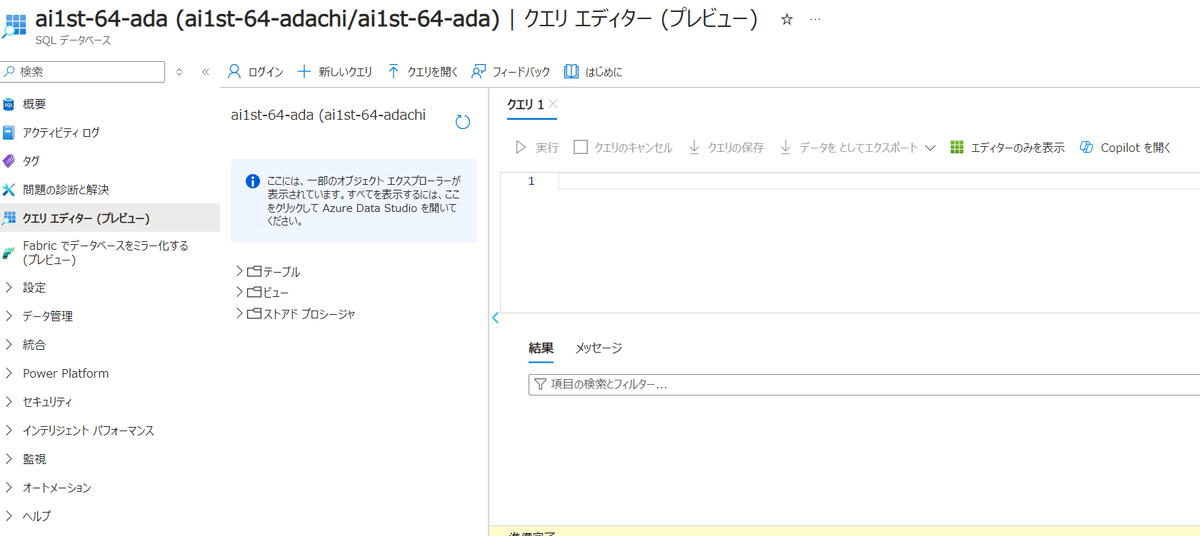
次に先ほど作成したSQLデータベースから【クエリエディター】のタブを選択し、SQLにログインをしましょう。

ログインが問題なく出来ればOKです。
次回は、データを利用して表やグラフを作成する手順を行っていきます。
Day12_Azure Data Factoryで表を作る
まずはSQLデータベースの【クエリエディター】からログインします。
※別の場所からログインする場合はファイアーウォールの設定を今の自分のIPに変更しなければいけないので、前回を復習しましょう。
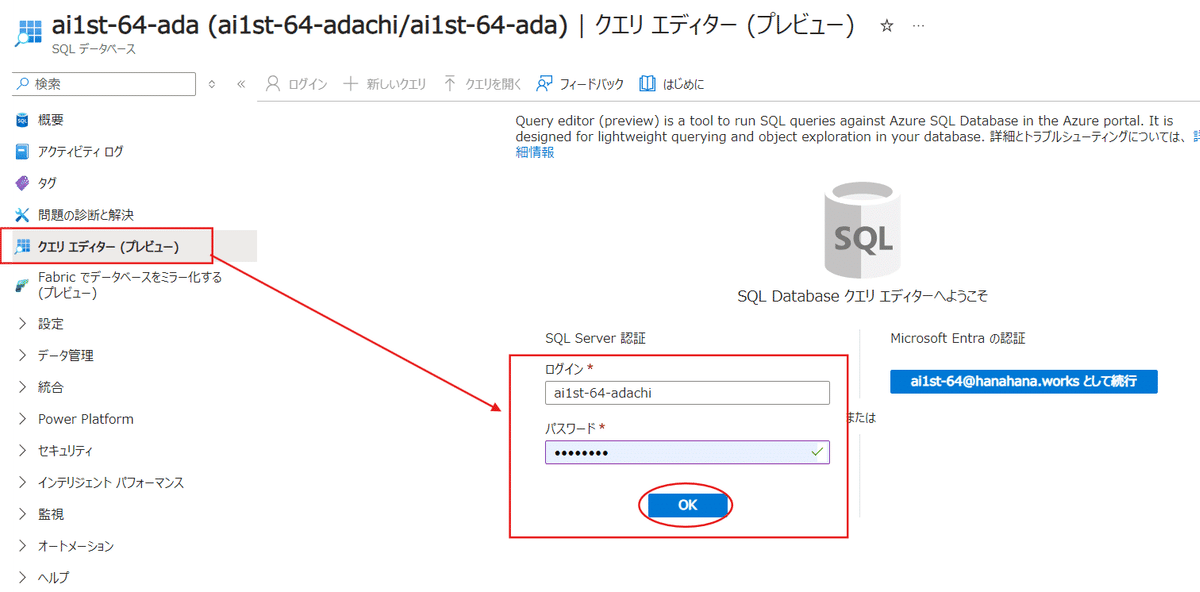
僕はIP6が表示されてしまってファイアーウォールの設定が上手くいかないパターンがありました。
その場合は、ログインする時に出てくる「エラーメッセージ」から現在のIPアドレスをコピーしておくとスムーズにログインできるようになります。
(自分でIPアドレスを調べてもOKだと思います)
今回は表にしていく手順を実施します。
作る表はData Factoryで変換させた表をSQLデータサーバーの方で作っていきます。

ChatGPTでSQLで実行するクエリを書いて貰うことから始めましょう。
その時は必要事項を具体的に示すのが良いです。
【カンパ先生のプロンプト例】
Azure SQL Databaseに、天気予報の情報のテーブルを作成したいです。
作成するテーブルには、以下の列があります。
・forecast_date
・forecast_time
・location
・todays_weather
・tomorrow_weather
また、それぞれの列に入るデータの例は以下のとおりです。
・2024-09-20
・17:00:00
・愛媛県 新居浜
・晴時々曇
・曇時々晴
なお、ここにデータを入れるAzure Data Factoryの時点では、forecast_dateのみ日付型、ほかはテキスト型となっているようです。
これらの情報から、テーブルを作成するSQLを作成してください。上記プロンプトで表示されたプロンプト
CREATE TABLE WeatherForecast (
forecast_date DATE,
forecast_time NVARCHAR(8),
location NVARCHAR(100),
todays_weather NVARCHAR(50),
tomorrow_weather NVARCHAR(50)
);これをSQLデータベースのクエリエディターに貼り付けます。
貼り付けたら【実行】を行い、クエリが成功したら、次に更新ボタンを押します。
テーブルの中に該当するdbo.~の名前が表示されていれば完了。
※名称は入力したクエリ欄を確認すればすぐに分かります。

次に引っ張ってくるパイプラインのデータを確認しましょう。
データフローからsinkの手前のブロックに対して最新として、取り込むデータに問題がないことを確認します。
(僕の場合はこの図で4つ目のブロックが該当します)

問題が無ければ、次にsinkを選んで【データセット】から【新規】を選択します。

今回は先ほど作ったSQLを使用するので、【Azure SQL Datebase】を選択して続行させます。

次にAzureサブスクリプションはSUNABACO講座で使用しているものを選択し、サーバー名には自分のものを使用します。
データベース名も先ほどSQLの場面で作ったものを選びましょう。
IDとパスワードはSQLの時に設定したものとなります。
完了したらテスト接続を行い、接続成功を確認したら【作成】を押します。

プロパティ設定の中のテーブル名に、SQLクエリエディターで作成したものがあれば選択して【OK】で完了です。

続いて、sinkを最新の情報に直し、エラーが出ていないことを確認しておきましょう。
(Nullなどが表示されていた場合は修正が必要になります)
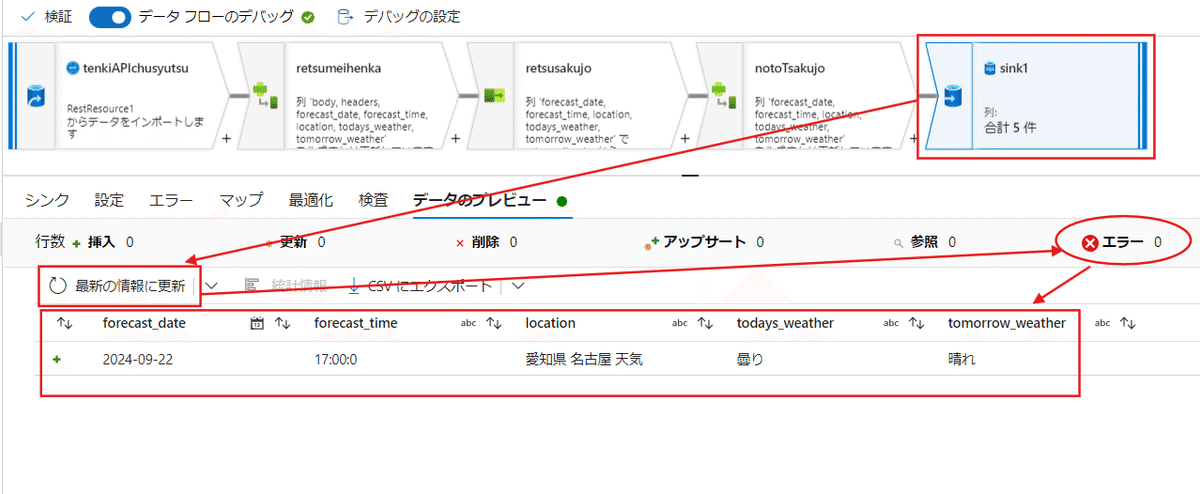
エラーが無ければ、すべて発行を行って、保存をしましょう。
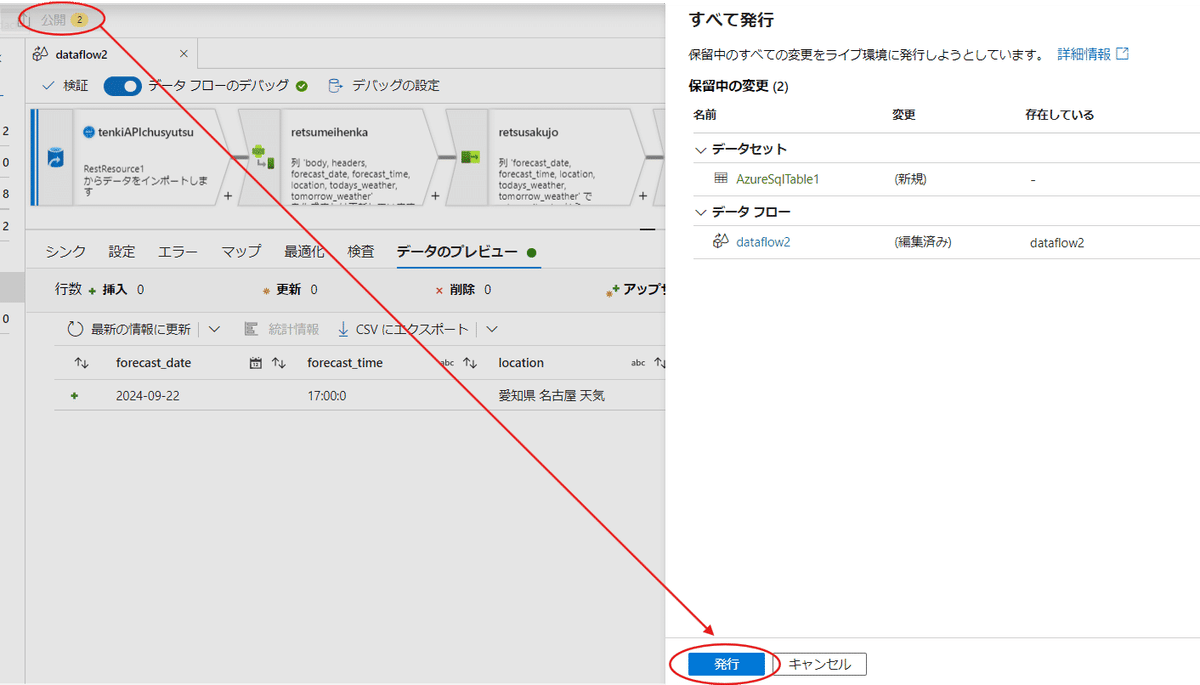
最後にパイプラインから【トリガーの追加】にある【今すぐトリガー】を選択します。

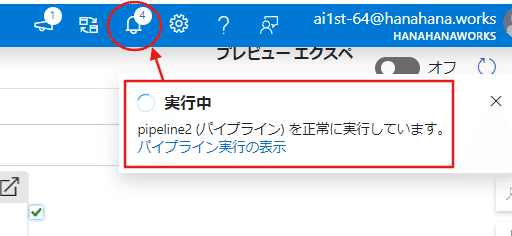
【実行中】のパラメータが出るので、完了まで待ちます。
ベルマークのところでも進捗を確認することが出来ます。
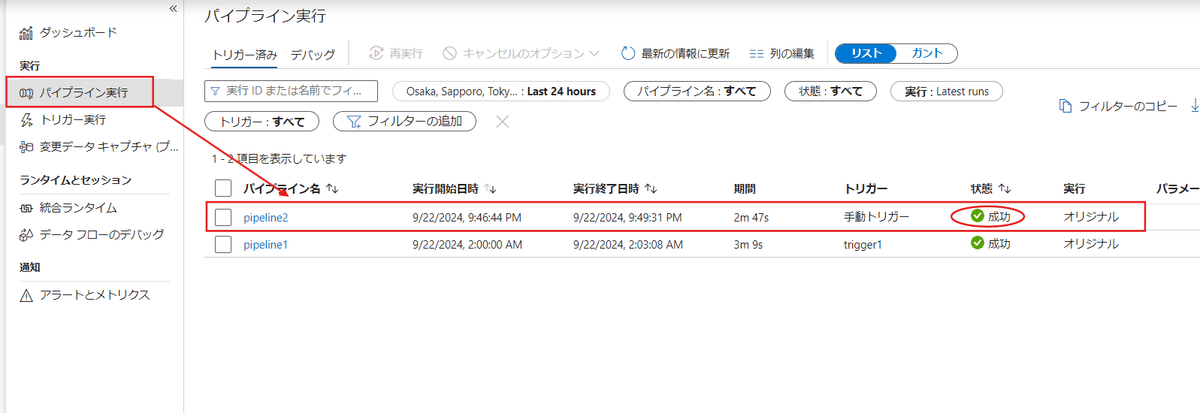
実行が終わると【パイプライン実行】の中で【成功】の表記を確認できます。
次にSQL側でも問題なくデータが取れているかを確認します。
該当するテーブルから【上位1000行を選択】を選びましょう。
(下記画像はテーブル名を囲っていますが、実際の選択枠はその名前の右側にある【・・・】の部分をクリックすると表示されます)
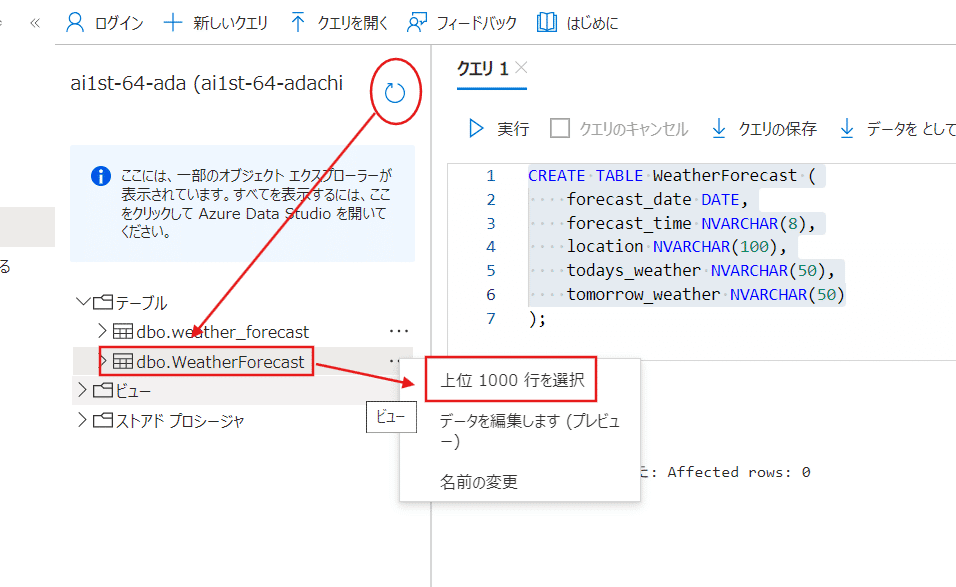
想定した表が出てきたら問題なく完了です。

Day13_PowerBIを使う
MicrosoftのPowerBIを利用して可視化されたものを作成していく工程です。
BI=ビジネスイノベーションとは何を意味するのか。
ビジネスインテリジェンス(BI)とは、企業や組織が持つデータを分析し、経営判断や意思決定に役立つ情報を提供するための技術や手法の総称です。BIを活用することで、過去のデータを整理し、現在の状況を正確に把握し、将来の傾向や予測を行うことが可能になります。
1・データ収集と統合
企業のさまざまな部門やシステムからデータを収集し、データを統合して全体像を把握できるようにします。
2・データの可視化
収集されたデータをグラフやチャートなどの視覚的な形で表示し、誰でも簡単に理解できるようにします。
3・分析とレポート作成
さまざまな指標やフィルターを適用してデータを分析し、意思決定に必要な情報をレポートとして提供します。
4・予測分析
過去のデータをもとに、将来のトレンドや結果を予測し、戦略的な計画立案に役立てます。
まずは前回のお弁当のデータをPowerBIに読み込ませていきます。
サインインしたら【新しいレポート】を選択していきます。

今回はコピペで作るので【データを貼り付ける】を選びます。

弁当データを全選択してコピーします。
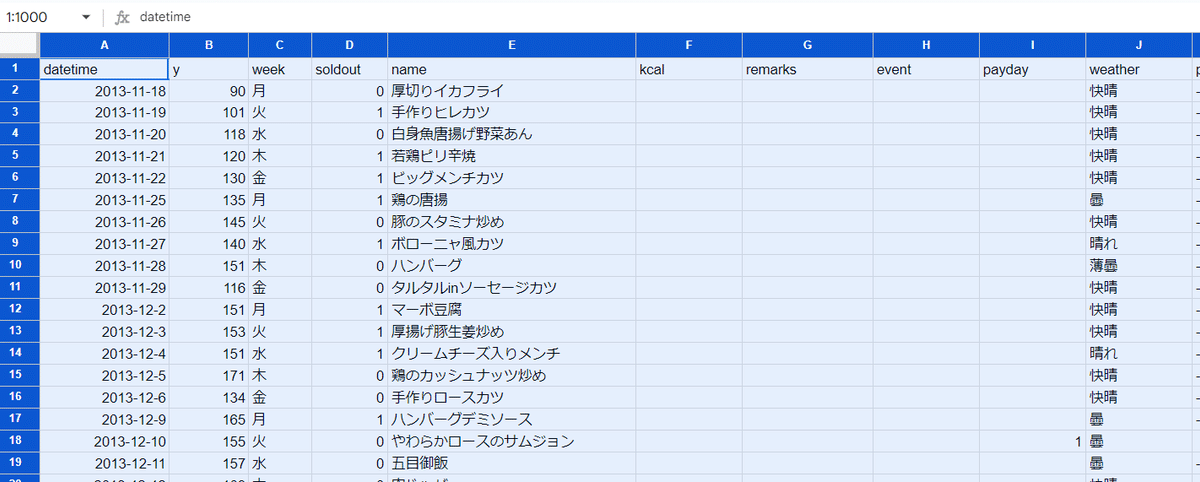
データの入力の欄にペーストを行いましょう。
※貼り付ける時は右の方に列名が何も無いようなところは削除してしまいましょう。そのままにすると【重複エラー】が発生します。
ペーストを行ったら【1行目をヘッダーとして使用】をクリックして、1行目の列名をヘッダーに移行させられます。
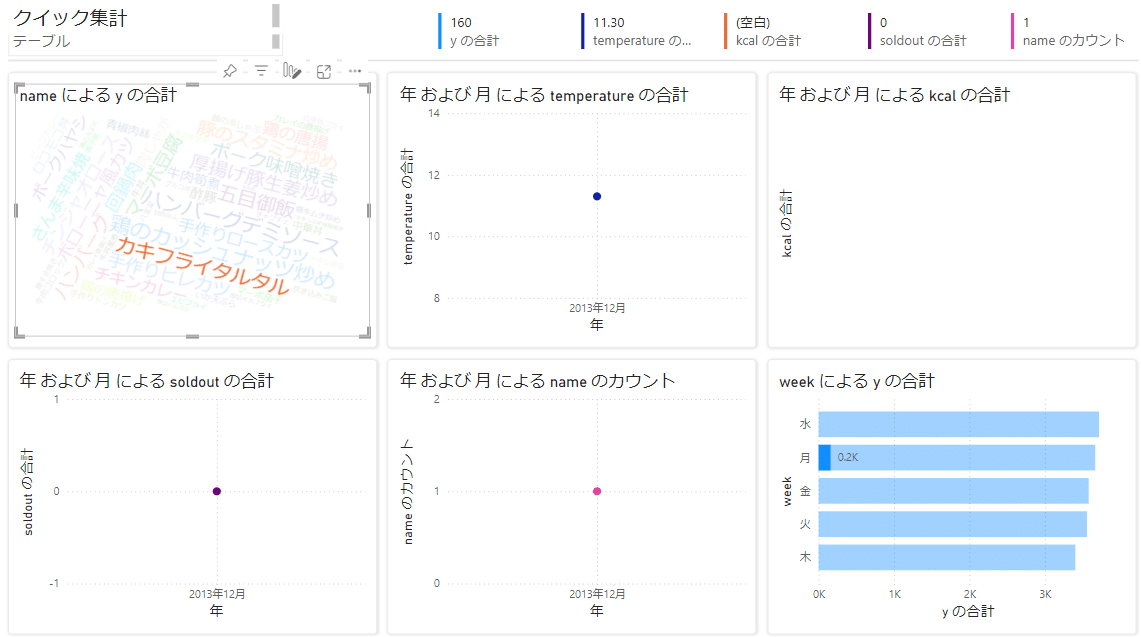
下記画像の状態になったら【レポートを自動生成する】をクリックしましょう。
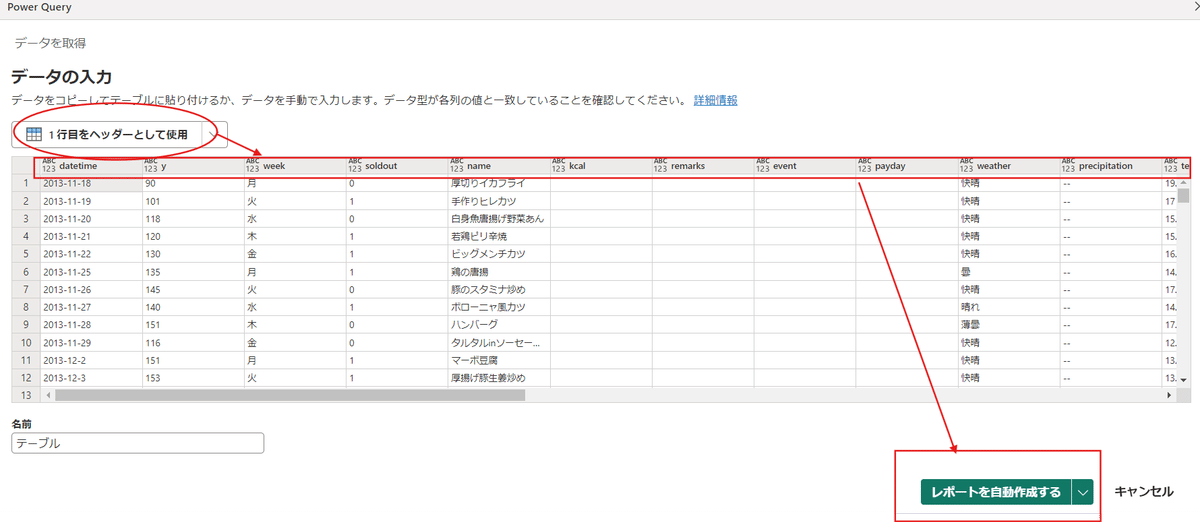
レポートが表示されます。

様々な形にできるので、これについては右側の【お客様のデータ】からチェックを加えると別のグラフなどが表示されます。
例としてweekにチェックを入れてみました。

個別のグラフに変更をしたい場合などは【編集】を選択しましょう。
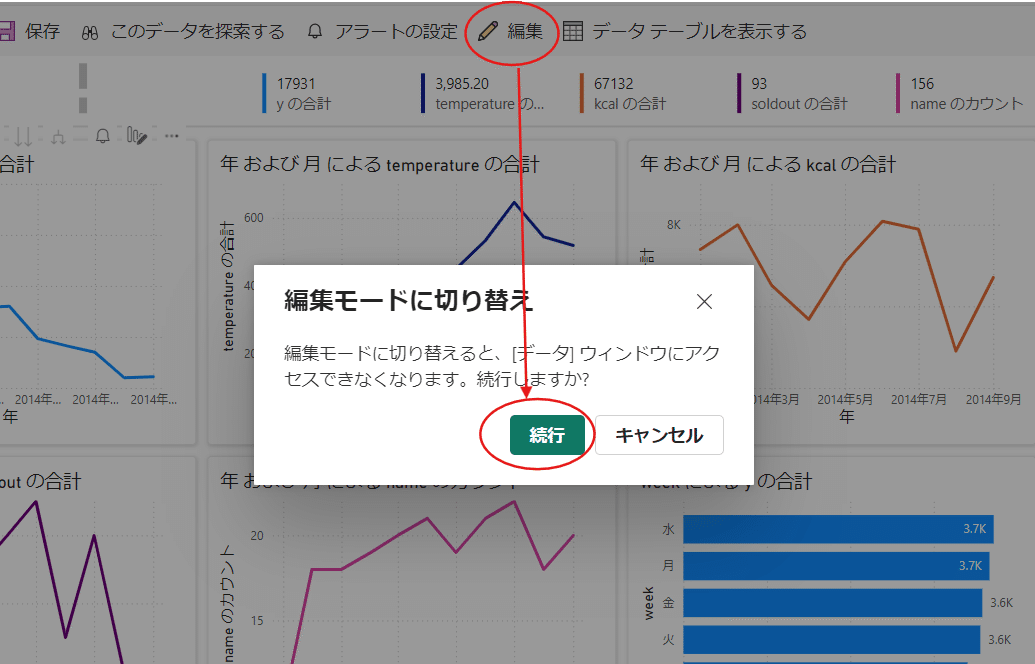
編集で【・・・】から【その他のビジュアルの取得】を選ぶと、複雑な処理を行うようなグラフなども表示することが出来ます。

デフォルトで用意されているグラフ以外にも様々な形の可視化ができるので、自身のデータに最適化されたものを使ってみましょう。

今回は試しに最初の頃に使用した【ワードクラウド】を使ってみます。

追加すると、可視化のメニューの中の下部に【w】と表記されたものが出てきます。
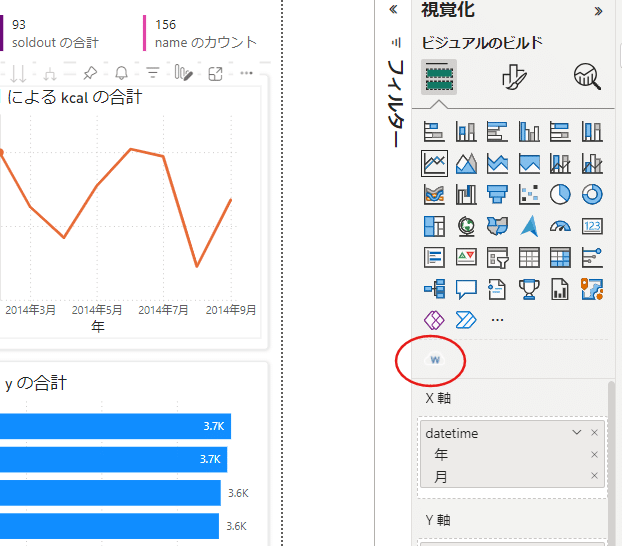
ワードクラウドが生成されます。
中身については【データ】から選択すると必要なものを利用してワードクラウドを生成することが出来ます。
例として弁当名となる【name】と販売数を示す【y】にしてみると、よく売れている弁当名が大きく表示されるようになります。

これらのデータは連動しているので、例えばワードクラウドの中から【カキフライタルタル】をクリックしてみると、他のデータもそれに該当する部分が表示されるようになります。
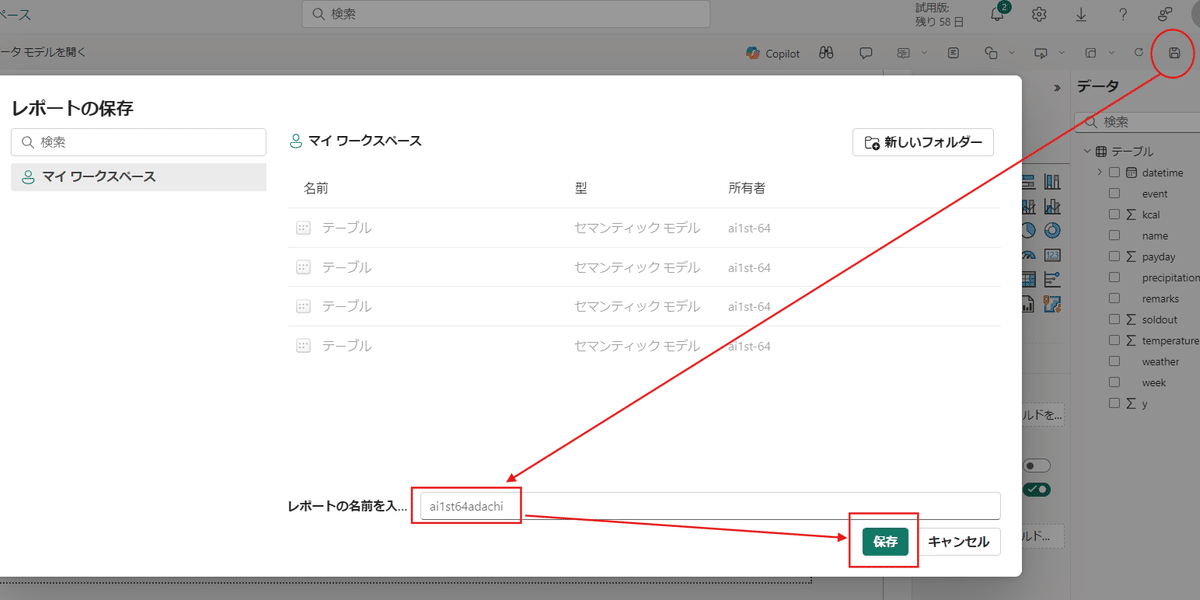
保存する場合は右上のフロッピーマークから名前を付けて保存します。
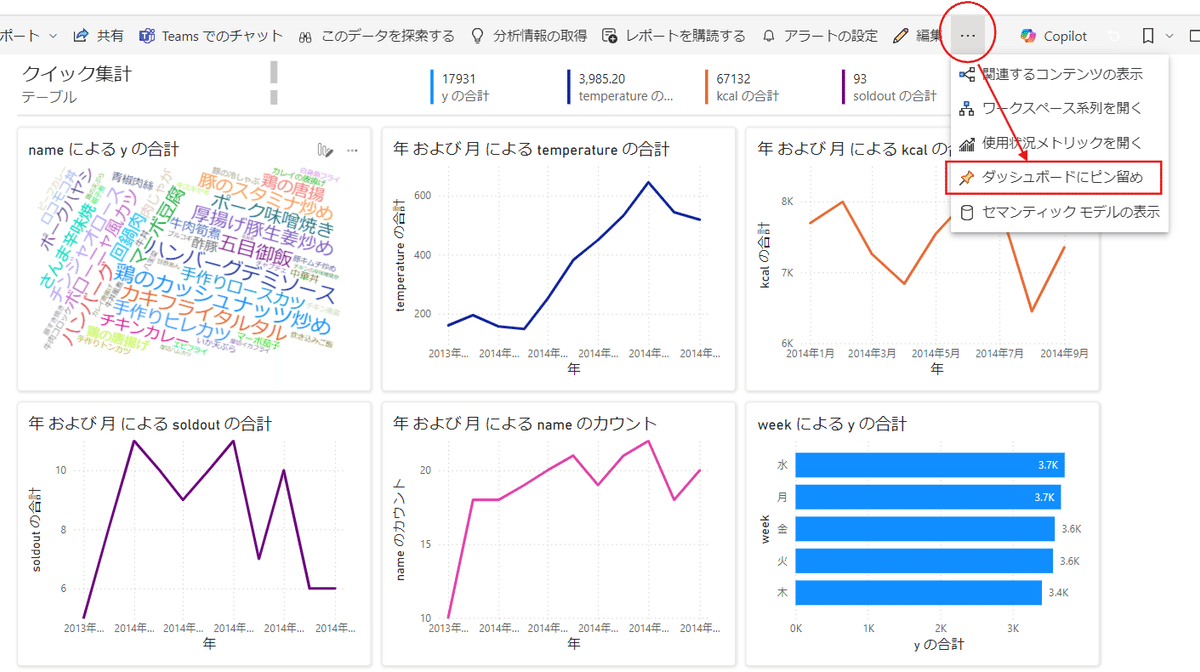
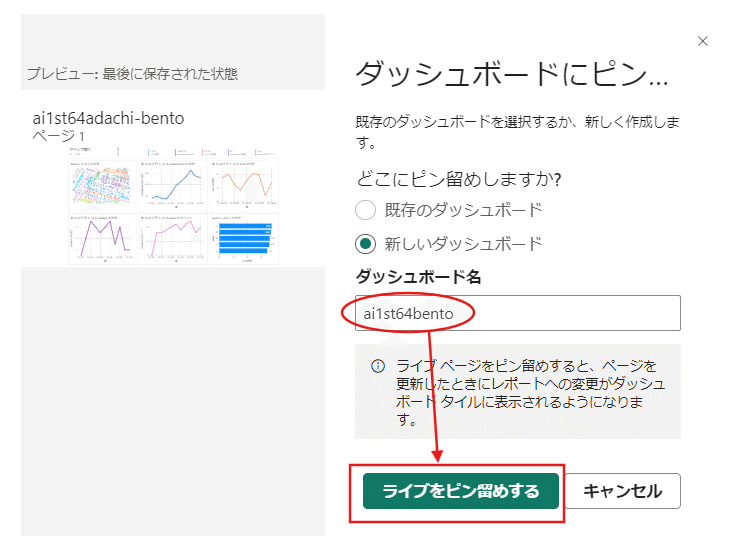
次に編集の隣欄の【・・・】から【ダッシュボードにピン留め】を行います。
これで稼働中の可視化されたデータが見やすくなります。
次にSQLにあるデータを可視化させていきます。
まずはリソースグループを選択します。

次にSQLデータベースを選択します。

アドレスが出ている画面まで出せたら、もう一度PowerBIに戻ります。
PowerBIから左側の【マイワークスペース】を選択します。
次に【新しい項目】を選択。

データ取得の項目から【ミラー化されたAzure SQL Database】を選択しましょう。
現在は権限がないため、これ以降は進めないので次回Day15に持ち越しとなります。
次回スムーズに実施するために、データに主キーの設定だけ行います。
主キー(Primary Key)とは、データベースのテーブルにおいて、各行を一意に識別するための特別な列のことです。主キーは必ず重複せず、空の値(NULL)を許さないというルールがあります。
例えば、社員情報を管理するテーブルで「同性同名」があった場合に「どの〇〇さんなのか」というのが分からなくなります。その時に、社員番号を振っておくことで、この社員番号が主キーとして使われ、一人ひとりの社員を確実に識別します。
まずSQLのクエリエディターにログインします。
次にChatGPTに作成コードを確認します。
【カンパ先生の指示文(プロンプト)】
Azure SQL Databaseを使っているのですが、現在、テーブルにPrimary Keyとなる列がありません。そのため、Primary Keyとなる列を作成したいです。 列の名前はidとし、これまでに作成された行に連番で数字が入り、そして今後作成される行にも自動連番が入るようにしたいです。 そのようなSQL文を作成してください。
ALTER TABLE [dbo].[WeatherForecast]
ADD id INT IDENTITY(1,1);
ALTER TABLE [dbo].[WeatherForecast]
ADD CONSTRAINT PK_your_table_name PRIMARY KEY (id);出力されたコードをSQLに貼り付けて実行を行います。
クエリが成功したら確認をします。

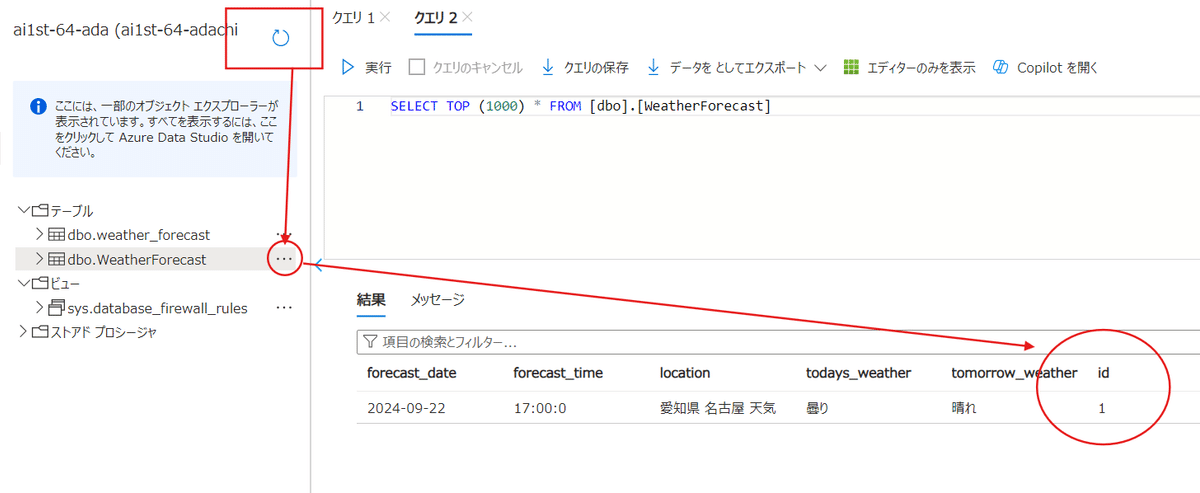
更新ボタンを押して、該当するテーブルの上1000行を表示させると【id】という列が新たに出てきています。
これで準備完了です。
Day14の内容でこの部分は完結するので、ここに記載します。
PowerBIのマイワークスペースから【ワークスペースの設定】を選択します。

【ライセンスの構成】の中の【編集】を選びます。
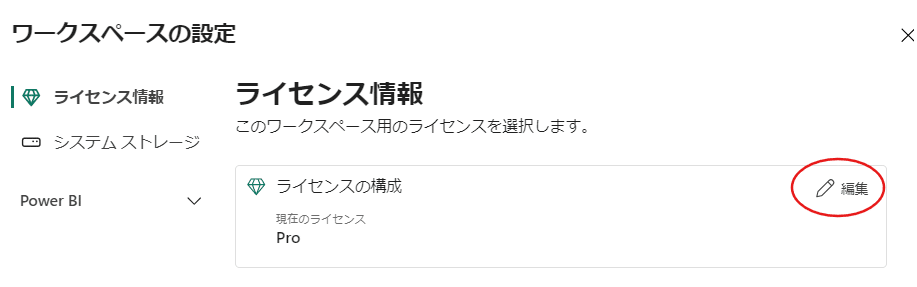
次に【ファブリック容量】を選び、容量については【ai1st】のものを選んで【ライセンスの選択】を行います。

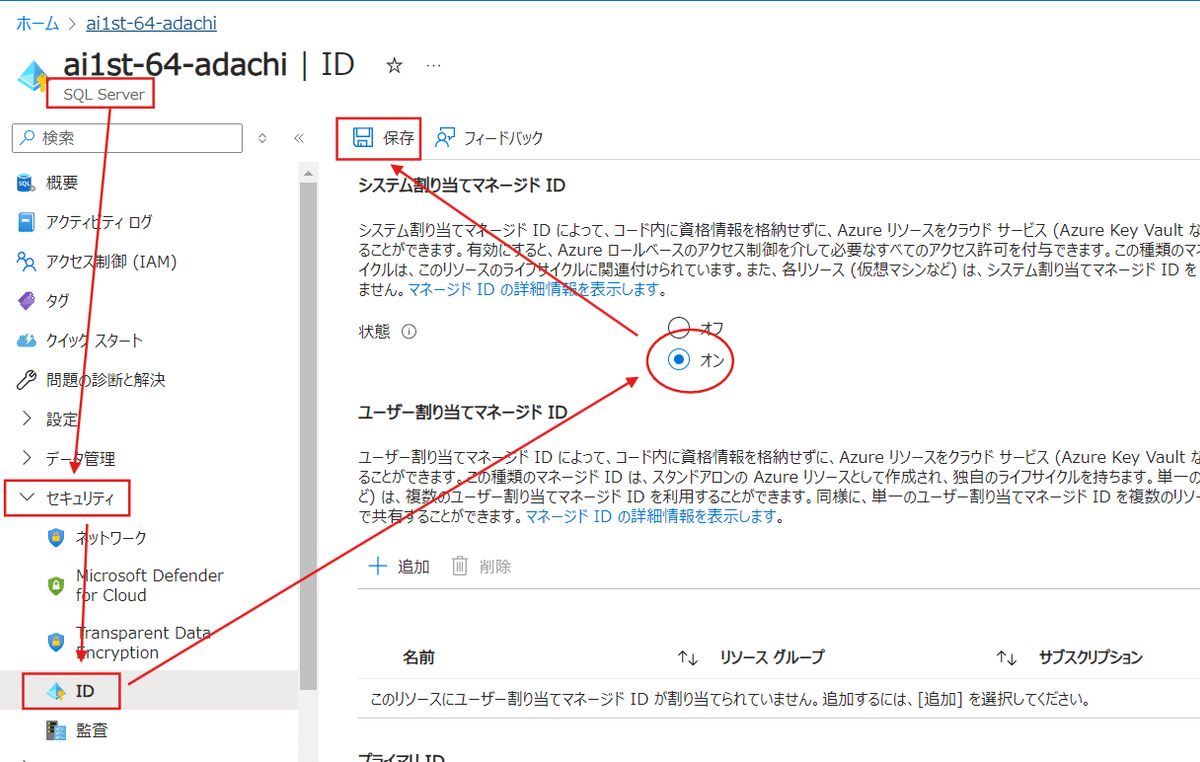
次にAzureポータルからリソースグループを選択し、その中にある【SQLServer】に移動します。
次に【セキュリティ】から【ID】を選択し、【システム割り当てマネージドID】を【オン】にします。
出来たら左上の【保存】を押して準備は完了です。
次にAzureポータルから自身のSQLデータベースを表示させましょう。
次の設定で使うので、この中の【サーバー名】の部分をコピーしておきます。

完了したら次にPowerBIに戻り、【新しい項目】から【ミラー化されたAzure SQL Database】を選択します。

次に新しいリソースの中にある【Azure SQL Database】を選択します。

コピーしてきたサーバー名を貼り付けます。
データベース名は各自講座で使用しているものを利用します。
ユーザー名とパスワードもSQL作成の時に設定したものを入力します。
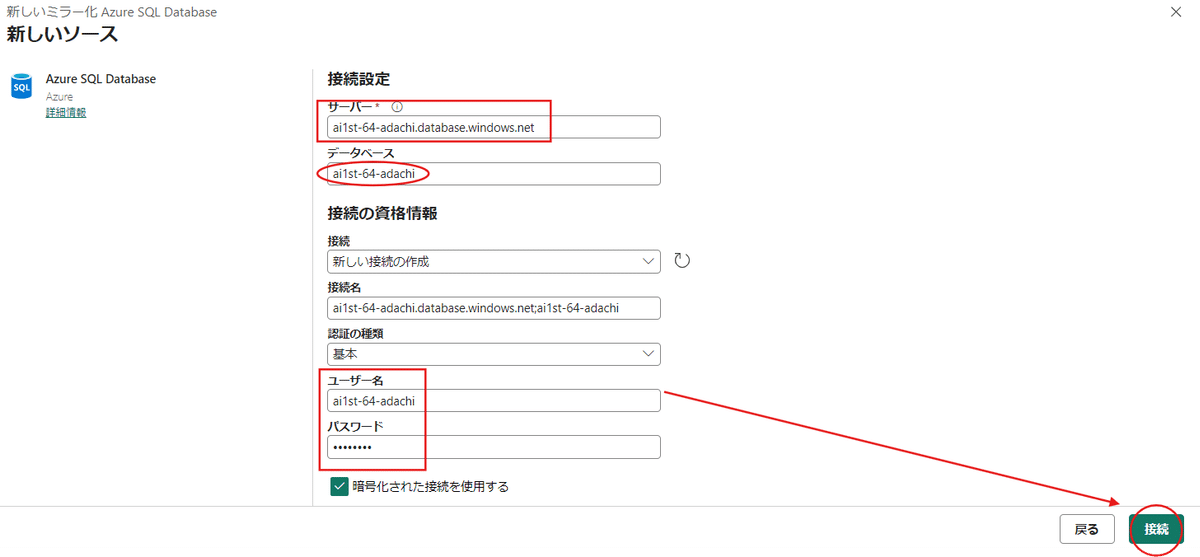
接続が完了したら、必要なデータプレビューで表示されていれば問題ありません。
【接続】を選んで次に進みます。

【ミラー化されたデータベースを作成する】を選択します。
【レプリケーションの監視】を選択します。
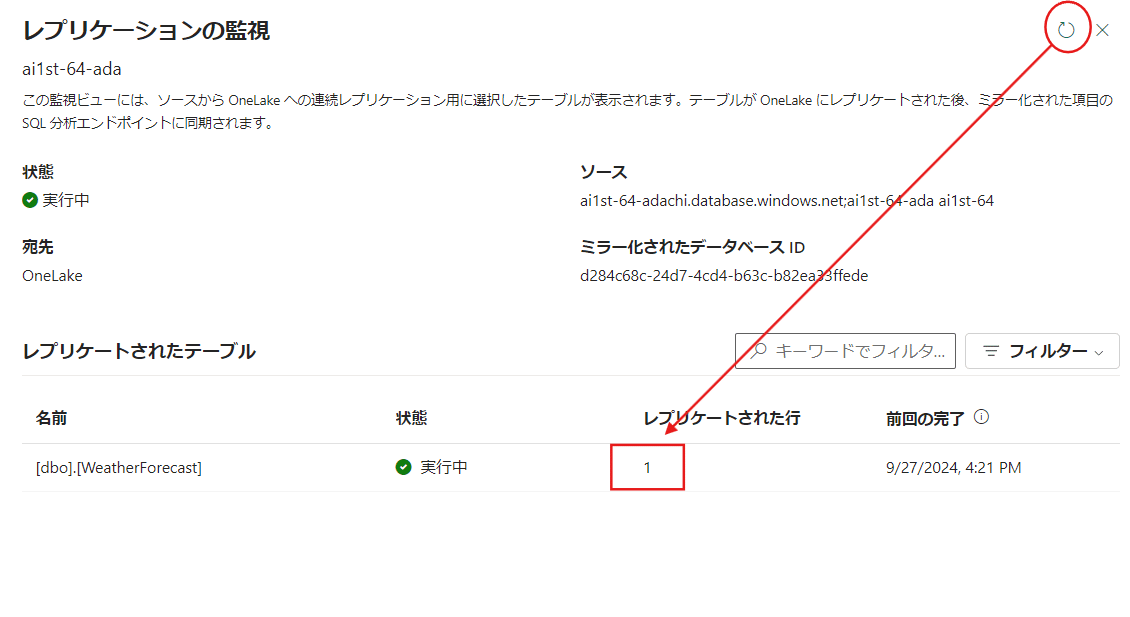
少し時間がかかりますが、待機してから右上の更新ボタンを押して【レプリケートされた行】が表示されたら最後に表を作ります。
右上の【ミラー化AzureSQLDatabase】の中の【SQL分析エンドポイント】を選択します。

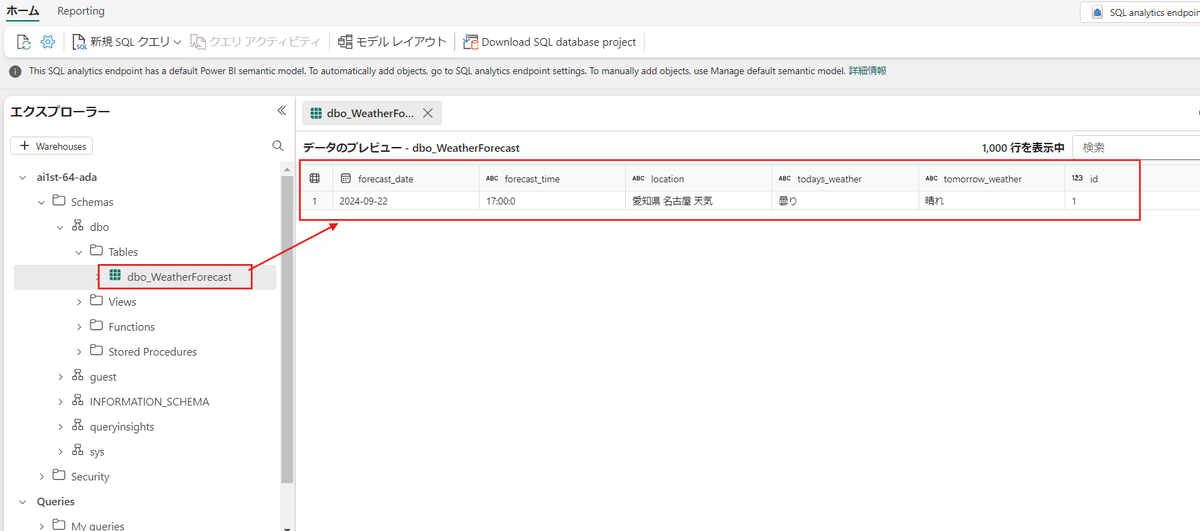
少し時間が表示に時間がかかる場合もありますが、エクスプローラーが表示されたら、設定しているテーブルを選択しましょう。
データのプレビューで想定していた表が出てくることを確認します。
問題なければ、次に左上の【Reporting】から【New report】を選択します。
ポップアップの【続行】を押しましょう。

取ってきたデータから可視化も可能になりました。

以上がデータ抽出から可視化までの流れとなります。
データ分析の意義を再考する
現代のビジネス環境において、データ分析は企業の成長と発展を支える不可欠な要素となっています。
しかし、分析を学び始めたばかりの段階では、手順や作業に集中しすぎて、その本質的な意味や目的を見失いがちです。
今回はデータ分析を学ぶ過程で「作業」に囚われず、俯瞰的な視点を維持する重要性についてお伝えします。
作業ベースはダメ、分析の意味を見失わない
データ分析を学ぶ初期段階では、データの収集や整理、基本的な統計手法の習得といった具体的な作業に多くの時間と労力を費やします。
これらの作業の大枠理解は確かに重要ですが、作業自体に執着しすぎると、分析の本来の目的である「課題の発見と解決」を見失ってしまう危険性があります。言わば組み立て家具の各パーツを丁寧に組み立てることに集中しすぎて、完成図を見ていないような状態と言えます。そうすると「これは一体どの部分だ?」という本末転倒な状態になってしまうでしょう。
作業に没頭すると、最終的な目標を見失いがちです。
これ防ぐためには、常に全体像を意識し、分析の最終目的を明確にすることが重要です。
データ分析は単なる作業の積み重ねではなく、企業の成長を導くための羅針盤として機能するのが望ましいものと言えます。
作業に没頭しすぎず、なぜその作業を行っているのか、その結果何を達成したいのかを常に問い続ける姿勢が求められるのです。
スイムレーン図を活用してボトルネックを探し出す
分析の目的を見失わないためには、まず業務プロセス全体を俯瞰的に理解する必要があります。
ここで有効なのがスイムレーン図などの可視化ツールというのは前半の講座でもありました。
『ザ・ゴール』という著書でも紹介されているように、業務プロセスの中でのボトルネックを見つけ出すことは、全体の効率を向上させるために不可欠です。
例えば、ある製造業の企業が生産ラインの効率を向上させたいと考えたとします。スイムレーン図を用いることで、各工程の担当者や部門ごとの作業の流れを視覚的に把握できます。
すると、特定の工程で作業が滞っていることが明らかになり、その原因を探ることが可能です。これにより、どの部分に改善の余地があるのかを具体的に見つけ出すことができるでしょう。ナビ上で高速道路の渋滞箇所を特定するように、スイムレーン図は業務プロセス全体を一目で理解し、効率化への道筋を見つけ出す手助けをしてくれます。
改善に必要なデータを取得するための合意形成
ボトルネックを特定した後、その改善に必要なデータを取得することが次のステップとなります。
しかし、データは簡単に手に入るものではありません。
多くの場合、異なる部門やチームからデータを集める必要があり、その過程で関係者間の合意形成が不可欠です。
生産ラインの改善を図るためには、生産部門からの詳細な生産データ、品質管理部門からの検査データ、販売部門からの売上データなど、多岐にわたる情報が必要となります。
これらのデータを統合し、信頼性の高い分析を行うためには、各部門の協力と理解が求められるのは言うまでもありません。
合意形成を円滑に進めるためには、分析の目的や期待される成果を明確に共有し、各部門の意見や懸念を尊重しながら進めることが求められます。
以前、ナカマコ氏が語っていた自らの手持ちでヘルメットなどを準備して向かう姿勢などが、それに該当してきます。
これにより、データの取得がスムーズになり、効果的な分析が可能となります。
改善作業の意味を考える
データ分析を行う手順は、単なる作業の連続ではありません。
その背後には、企業の持続的な成長と競争力の維持といった大きな目的があります。
データを分析し、課題を発見し、解決策を実行する一連のプロセスは、企業が変化する市場環境に適応し、常に最適な状態を保つために欠かせないものと言えるでしょう。
レストランがメニューを改善する際に、売上データや提供速度、顧客のフィードバックを分析することで、人気のない料理や厨房リソースを食いすぎている商品を見つけ出し、メニューから外す決断をすることも出来ます。
結果として顧客満足度を高め、売上を向上させることができるのです。
このように、データ分析は具体的な成果をもたらし、企業の成功に直結する重要な活動となります。
また関係者との合意形成を通じて、分析結果に基づいた改善策を実行することで、組織全体の協力体制が強化され、持続的な成長が可能となるでしょう。
データ分析は、企業内のコミュニケーションを促進し、共通の目標に向かって一丸となるための基盤を築く役割も果たします。
改めて考える
作業に囚われず、分析の本質的な意味を見失わないことが、効果的なデータ分析を行うために常に意識すべき点となります。
今やっている作業ベースのものも、すべては後に訪れる航海においての灯台になるべく、マクロな視点での観察を忘れないようにしていきましょう。