
Day9_Azure DataFactoryにデータを入れる(外部API利用)【備忘録】

※今回は僕に時間があったので質問を幾つか抽出し、それについての考察を入れています。
質問と解答、そして考察
クラウドサービスの利用と従量課金のリスク
クラウドサービスを使用する際に、従量課金制による莫大なコストが発生するリスクについての懸念は多くの企業や個人で共通する問題です。
クラウドの魅力は、初期投資を抑えつつ、迅速に環境を整えることができる点にあります。
試験的に小規模から部分的に利用していくことも可能になるでしょう。
よって、最初の内から「使えるのかどうか不明」な状態で設備を購入する必要はなくなります。
もちろん、突き詰めればオンプレミス(自前のサーバー設置)の方が安く済む場合もありますが、未知の部分が多い状態の中で全てを自前で準備する必要がなくなるのは大きなメリットです。
また現実に自前でシステムの構築が不可能な場合も多くあります。
(Microsoft Azureと同じ様なものを自分たちで作れるのか問題)
テクノロジーの民主化という観点で見ても、クラウドサービスの利用に慣れ親しんでおく意味は大きいと言えます。
考察:
クラウドサービスの使用は、特にスモールビジネスやスタートアップにとって強力な武器となる。初期費用が低く、必要な時だけリソースを借りることができるため、柔軟性が高くなるだろう。一方で、利用が進むにつれてコストが増加するリスクも伴うため、適切な利用管理とコスト監視が重要。
Azureのセキュリティーの水準
Azureのセキュリティーは、マイクロソフトの他のプロダクトと同様に高いレベルで維持されています。
具体的には、WordやExcelに社内のデータを保存するのと同等のレベルのセキュリティ対策が施されているとカンパ先生より回答。
これにより、企業の重要データをクラウド上で安全に扱うことが可能です。
考察:
マイクロソフトは、長年にわたりセキュリティへの取り組みを強化してきた実績がある。Azureにおけるセキュリティ対策もその延長線上にあり、クラウド上でのデータ保護がしっかりと行われている。企業がクラウドへの移行を検討する際には、このセキュリティ水準が信頼できる基盤となるだろう。
Pythonでの分析からAzureへの移行の理由
従来はPythonでデータ分析を行っていたのに対し、Azureを使う理由は、データのサイクル全体を管理するためです。
データの収集から蓄積、加工、そして活用に至るまで、各プロセスにパイプライン管理が必要になります。
実際、使える状態のデータにするまでには予想以上の手間がかかることがあり、Azureのパイプライン機能を利用することで、データ管理の効率化が図れ、その結果、迅速かつ効果的なデータ活用が可能になります。
考察:
データサイエンスにおいて、データの準備段階は非常に時間がかかり、また重要なプロセスと言える。Azureのようなクラウドプラットフォームを活用することで、データの取り扱いが効率化され、より高度な分析に集中することが可能になる。特にデータの量が増えると、その管理や整備におけるクラウドの利点が顕著になる。
データパイプラインの導入タイミングとスイムレーン図の役割
データパイプラインの導入時期についての質問は、データの取得が思った以上に困難であるという現実を反映する必要があります。
まず、どの因子が必要なのかを明確にするためにスイムレーン図を作成することが推奨されますが、その後も注意が必要です。
必要なデータが明らかになった後には、データ収集者や提出者との合意形成が極めて重要と言えるでしょう。
これらの合意が成立した後であれば、パイプラインを導入するタイミングとしては適切と言えます。
考察:
データ分析において、データ取得のプロセスは想像以上に複雑で、多くのステークホルダーが関与する。スイムレーン図は、各ステップを明確化し、必要な情報の流れを可視化するための有効なツールである。しかし、それだけでは十分ではなく、関係者間の合意形成と綿密な計画が不可欠と言える。
Azureの選択理由と他サービスとの比較
Azureの使用理由に関しては、初心者にも分かりやすく、世界的に人気が高いという点が挙げられます。
クラウドの複雑な概念や構造についての細かい点を気にする必要がないことも魅力でしょう。
例えば、Microsoft Learnを利用すれば、課金せずにテスト環境を試すことができるという利点があります。
対照的に、Amazon Web Services(AWS)は非常に強力なツールセットを提供していますが、初心者には難解であるため、エキスパート向けと言えるでしょう。
考察:
Azureの利便性と学習コストの低さは、特にクラウドサービス初心者や中小企業にとって大きな魅力だろう。一方、AWSのようなサービスは、その多機能性と柔軟性から、より高度なニーズに対応したい企業や強い専門性を持つ者に向いていると考えられる。
Azureの実務での利用シーン
Azureの多彩な機能は、現時点では主にシステム担当者や情報系の専門家が利用していますが、今後は現場の従業員が積極的に使用し、効果を発揮する場面が増えることが期待されています。
現に新機能である「Copilot」によって、技術的なバックグラウンドがない人でも簡単にアプリを作成できるようなツールが登場しています。
これは、技術の民主化の一環であり、技術の壁を越えて誰でも簡単に利用できる未来を指し示しています。
考察:
技術の民主化が進む中で、クラウドサービスの利用はますます一般化していくと考えられる。現場の人々が自身のニーズに合ったツールを作成できるようになることで、企業全体の効率化や柔軟性が飛躍的に向上する可能性が高い。
Microsoft Authenticatorの導入基準
課金が可能なシステムや金融関連のデータが関わる場合、より強固なセキュリティ対策が求められます。
これらのサービスについてはセキュリティの三要素である「知識情報」「所持情報」「生体情報」のうち2つ以上を組み合わせることが望ましいです。
これにより、システム全体の脆弱性が低減し、信頼性の向上に繋がります。
考察:
今日のデジタル時代において、セキュリティの強化は非常に重要。マルチファクタ認証の導入は、最も基本的かつ効果的な対策の一つであり、特に金融取引や個人情報を扱う企業にとっては必須となる。
リソースグループの役割とその重要性ーAzureでの管理の階層構造
Azureを利用する際、リソース管理は極めて重要なポイントです。
Azureには「管理グループ」「サブスクリプション」「リソースグループ」「リソース」といった階層構造があり、それぞれが異なる役割を担っています。
この構造の理解は、効率的なクラウドサービスの利用に欠かせません。
例えば、「管理グループ」は複数のサブスクリプションを一元管理するための階層であり、その下に「サブスクリプション」が存在します。
サブスクリプションは具体的な課金契約を指し、その下に「リソースグループ」があります。
リソースグループは、仮想マシンやストレージアカウント、ネットワークといった個別のリソースを論理的にまとめたもので、特定のプロジェクトや環境に関連するリソースを管理するために使用されます。
そして最下層に「リソース」が位置し、実際に使用される個々のサービスやアプリケーション、データなどが含まれます。
前回の教訓・リソースグループの共有管理のリスク
前回の講義では、受講生全員が同じリソースグループを共有する形で設定を行いました。
この一元管理のアプローチは、初心者がAzureの基本機能を学ぶには効率的であったものの、セキュリティや管理上のリスクが浮き彫りになりました。
同じリソースグループを共有することで、受講生全員が他の人のリソースにアクセスできる状態になってしまい、誤って削除したり、設定を変更したりする危険性が生じたのです。
この問題は、クラウド環境の柔軟性と便利さが裏目に出る典型例と言えるでしょう。
クラウドの特性上、リソースへのアクセスが容易である反面、適切な管理が行われなければ、セキュリティや運用に重大なリスクをもたらします。
講座受講生の立場なので上記のリスクも大きな問題にはなりませんが、社内で導入する際には注意すべき点として認識を新たにするのが望ましいと言えます。
個別のリソースグループ管理への移行ー安全で効率的なクラウド運用
こうした教訓を踏まえ、今回はリソースグループを個別に切り分けることにしました。
このアプローチにより、各受講生は自身のリソースのみを管理・操作できるようになります。
他の受講生のリソースを誤って操作するリスクが回避され、全体の管理がより安全かつ効率的になるでしょう。
個別のリソースグループを使用することで、各ユーザーが自分のリソースに対する完全なコントロールを持つことができ、リソースの監視や管理も容易になります。
さらに、リソースの可視性が限定されるため、意図しない操作ミスや不正アクセスのリスクが減少します。
クラウド環境での運用において、こうしたセキュリティと運用効率のバランスを取ることが非常に重要です。
外部との連動に関わらず、社内での構築についても「他部署が誤って別のリソースを削除してしまった」というミスを削減する意味は大きいと言えます。
今回の事案から、”分ける意味”を強く理解しておく必要があります。
Azure Data Factoryとは?
※Microsoft LearnのDataFactoryの概要部分を簡略化。
Azure Data Factoryは、マイクロソフトの提供するクラウドベースのデータ統合サービスです。
膨大な量の生データを使いやすい情報に変換するためのプラットフォームで、特にETL(抽出・変換・読み込み)やELT(抽出・読み込み・変換)プロセスを効率化するために設計されています。
Azure Data Factoryの主な機能
データの移動と圧縮→データの移動時にデータを圧縮して帯域幅の使用を最適化し、効率的にデータを転送します。
多様なデータソースとの接続→オンプレミス、クラウドを問わず、多種多様なデータソースと簡単に接続できます。これにより、データのサイロ化を防ぎ、データの一元管理が可能です。
※サイロ化・・・部門や部署間の連携が取れていない状態カスタムイベントトリガー→特定のイベント(例: ファイルのアップロード)が発生したときに、自動でデータ処理を開始できます。
データのプレビューと検証→データのコピー中にプレビューと検証ができるため、データの正確性を確認しながら処理を進めることが可能です。
カスタマイズ可能なデータフロー→ユーザーが自由にデータの処理フローを作成・カスタマイズできます。例えば、データの変換やフィルタリング、結合などの処理を視覚的に設定できます。
統合セキュリティ→Entra IDによる認証やロールベースのアクセス制御を備えており、データの安全性を確保します。
Azure Data Factoryの利用シナリオ
たとえば、ゲーム会社がペタバイト級のゲームログを収集し、顧客の行動や好みを分析する場合が考えられます。
Azure Data Factoryを使えば、オンプレミスやクラウドの様々なデータを統合し、クラウド上のSparkクラスター(例: Azure HDInsight)で処理できます。変換されたデータは、Azure Synapse Analyticsなどのデータウェアハウスに格納され、ビジネスの意思決定に役立つ分析レポートとして使用できます。
※Sparkクラスター・・・大量のデータを高速で処理するための分散コンピューティング環境を提供するシステム
Azure Data Factoryの構成要素
パイプライン
データをどう処理するかを決める「手順書」のようなもの。いくつかの処理ステップ(アクティビティ)をまとめて実行します。アクティビティ
パイプラインの中の「具体的な作業」です。たとえば、「データをコピーする」や「データを計算する」といった作業を指します。データセット
使用する「データの場所や形式」を示すものです。どこにどんなデータがあるかを指定します。リンクされたサービス
外部のデータベースやファイルストレージなどの「データの保存場所」にアクセスするための「鍵」や「住所」のようなものです。データフロー
データをどのように変えるかを決める「設計図」です。視覚的にデータの変換処理を作成できます。統合ランタイム
データを処理するための「作業場所」です。データの移動や変換を実際に行う環境を提供します。
Azure Data Factoryのメリット
柔軟性と拡張性
様々なデータソースに接続でき、企業の規模に関係なく利用可能。自動化と効率化
トリガー設定やパイプライン管理により、データ処理を自動化し、人的リソースを削減。
※トリガー設定・・・特定の条件やタイミングで自動的に処理を開始するための仕組みセキュリティの強化
統合されたセキュリティ機能により、データの保護が保証される。
Azure Data Factoryを利用してパイプラインを作る【序章】
収集→変換→蓄積→活用の流れの中で、収集と蓄積の意味が同じだと感じる場合があります。
実際にこの2つを説明しようとすれば、理解度が分かります。
あなた自身の言葉で、今回の「収集」と「蓄積」が何を意味するのか考えてみましょう。
下記にデータレイクとデータウェアハウスについての解説を入れます。
データレイク (Data Lake) とは?
データレイクは、あらゆる種類のデータをそのままの状態で大量に保存するための「大きな倉庫」のようなものです。データレイクには、次のようなさまざまなデータを保存できます。
構造化データ: 整理された表形式のデータ(例:エクセルデータ)
半構造化データ: 一部が整理されているデータ(例:CSVファイル、JSONファイル)
非構造化データ: 整理されていないデータ(例:テキスト、画像、動画、ログ)
つまり、どんな形のデータでもデータレイクにはそのまま保存できるので、いろいろな種類のデータを集めて保管しておくのに便利です。
データウェアハウス (Data Warehouse) とは?
データウェアハウスは、データを整理して保存し、それを分析したりレポートを作成したりするためのシステムです。ここに保存されるデータは、使いやすいようにきちんと整理されています。データウェアハウスは、主に次の目的で使われます。
分析→ビジネスのパフォーマンスを分析するために使われる
レポート作成→ビジネスの状況を報告するための資料を作成する
データウェアハウスは、ビジネスの意思決定に役立つ「データの整理された保管庫」のようなものです。
実際にAzure Data Factoryを触ってみよう
データストレージアカウントを作ってみる
1.Microsoft Azureの検索窓に「ストレージアカウント」と入力
2.左が緑色になっている【ストレージアカウント】を選択

3.ストレージアカウントで【作成】を選択

4.ストレージアカウントを作成するではリソースグループを自身のもの
5.ストレージアカウント名はハイフンなど無しのものを入力
6.残りはデフォルトで【確認と作成】

7.確認画面が出てくるので下部の【作成】を選択

8.デプロイが進行中と出たら待機

9.「デプロイが完了しました」が表示されたらストレージアカウント完成

実際にデータ処理に必要な取り込みを行う
※リソースグループを作り、データファクトリをリソースとして追加し、スタジオを起動させると下記画面(そこまで前回に行った)。
1.【新規】から【パイプライン】を選択

2.【データフロー】をドラッグして右側の空白部分に入れる
3.【データフロー】が選択された状態で下記タブの【設定】を選ぶ

4.【設定】のデータフローと書かれた右側にある【新規】を選択

5.【ソースを追加】を選択

6.【source】のマークが表示されたら【データセット】から【新規】選択
7.右の検索窓に【REST】を入力し、地球マークの【REST】を選択
8.【REST】を選択後に下部の【続行】を選択

9.プロパティ設定が表示されたら【新規】を選択

10.【ベースURL】に天気予報のAPI情報のURLを貼り付ける
※これは各自の近い場所を探すと良い
【名古屋の場合】
https://weather.tsukumijima.net/api/forecast?city=230010
11.【認証の種類】は【匿名】に変更
12.【サーバー証明書検証】は【無効化】を選択
13.【作成】を選択

14.作ったリンクサービスが表示されていたら【OK】を選択

15.ソースの設定の【説明】にデータがインポートされたことを確認
16.上部の【データフローをデバック】を【オン】にする
17.オンにする時に右側に時間などの選択画面が出るので【OK】を選択

18.データフローのデバックの右側でクルクル処理中マークが出る
19.下部タブから【データのプレビュー】を選択
20.デバックセッション~の待ち表示
21.右上のベルマークで状況が分かる

22.「クラスターの準備が出来ました」の表示が出れば処理完了

23.データのプレビューから【最新の情報に更新】を選択
24.処理中のクルクルマークが出たら待機

25.データフローのデバックに緑のチェックマークが出ていれば完了
26.下部の表示欄にデータが出ている
27.大元のタブに出ている黒丸は『未保存』を意味している

28.矢印ブロックの右下の小さな【+】を選択
29.最下部の【シンク】を選択

30.sink1を選択し、下部に表示される【データセット】の【新規】を選択
31.右側に表示される【Azure Data Lake Storage Gen2】を選択し【続行】

32.形式の選択は【DelimitedText】(CSV)を選択し、【続行】

33.プロパティの設定でリンクサービスから【新規】を選択

34.名前は分かりやすいものを入力(ハイフンは使えない)
35.サブスクリプションは【ai1st】のものを選択
36.ストレージアカウントは先述で作成したものを選択し【作成】

37.プロパティの設定でリンクサービスを確認して【OK】を選択

38.【すべて検証】を選択
39.【すべて発行】を選択

40.すべて発行が表示されたら【発行】を選択
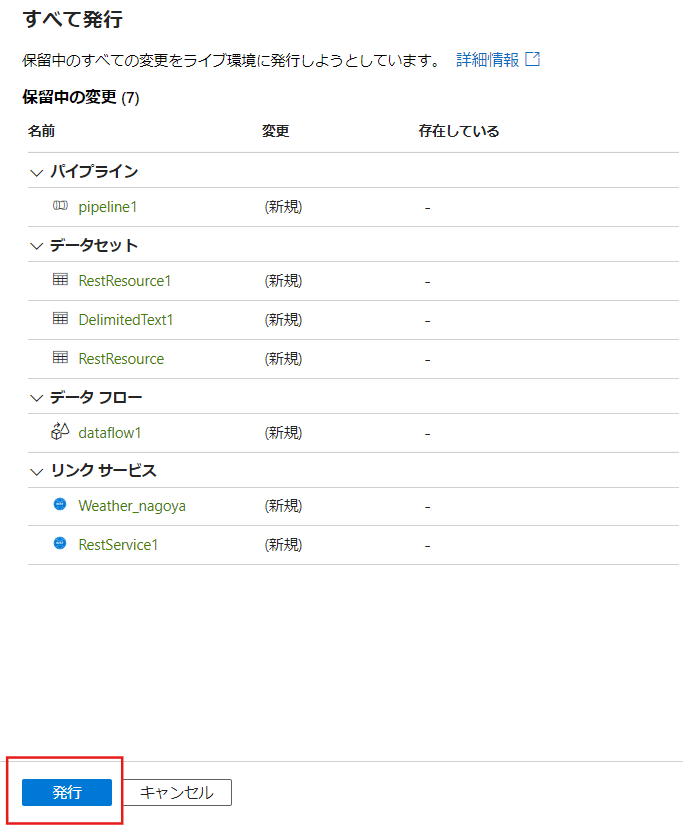
41.タブの中の黒丸(●)が消えていたら保存完了

以上、保存までの流れでした。
マニュアルみたいになったな・・・。
Azureの学びー継続することの重要性
クラウドコンピューティングの分野で、Azureのようなプラットフォームを学ぶことは、もはやエンジニアだけの専売特許ではありません。
技術の進化が早い現代では、あらゆる職種や立場の人々がAzureに触れ続けることが求められます。
それは、単に技術を知っているだけではなく、ビジネスの現場でその価値を理解し、活用するためです。
学びの継続が成功を導く理由
Azureをはじめとするクラウドサービスは、その機能やサービスが絶えず進化し続けています。
新しい機能やサービスの追加、既存サービスの改善や変更が頻繁に行われるため、常にアップデートを学び続けることが求められます。
ある日学んだ機能が、次の日には拡張されていることも珍しくありません。この変化の速度は、もはやエンジニアの専門知識だけでは追いつけないほどです。
多くの人が誤解していることの一つに、「エンジニアだから学びが早い」という先入観があります。
しかし、実際にはAzureのようなクラウドプラットフォームを学ぶ上でのスピードは、職種や肩書きよりも、「どれだけ積極的に触れ続け、実際に使ってみるか」という継続経験に大きく依存しています。
どんなに優れたエンジニアでも、Azureに対する知識やスキルが自然と身につくわけではありません。
日々の利用や実践を通して、段階的に学び、理解を深める必要があります。
実際に触れることで得られる経験値
Azureを学び始めたばかりのビジネスユーザーが、ある程度の頻度でAzure Portalを開き、自ら実験的に環境を設定したり、小規模なプロジェクトを作成したりすることで、実際の運用やトラブルシューティングの経験を積むことができます。
これにより、「使ってみる」ことの価値を実感することができるのです。
Azureの使い方や設定についての本を何冊も読むよりも、実際に触れてみることで得られる学びのほうが圧倒的に効果的です。
これは、プールサイドで水泳の理論を学ぶよりも、実際に水に飛び込んで泳ぐことから得られる学びのほうが多いのと似ています。
Azureの設定や構築の過程で、どうしてそのような設定が必要なのか、なぜ特定のサービスが選ばれるのかといった実際の現場のニーズを理解できるようになるでしょう。
学び続けることの価値
Azureについて継続的に学び続けることは、技術的な成長だけでなく、業務の効率化やイノベーションの促進にもつながります。
新しいサービスや機能の活用方法を知ることで、より効率的なプロセスを構築し、コストを削減し、ビジネスの競争力を高める方法を思いつく可能性も高まるでしょう。
また、学び続けることにより、より多くの人々がAzureの可能性を最大限に引き出すことができるようになります。
三人集えば文殊の知恵は、まさにこういった場合に発生するものです。
クラウドサービスの価値を最大化するためには、エンジニアだけでなく、ビジネスリーダー、データサイエンティスト、さらには非技術的なスタッフも含めて、すべての人がAzureに触れ続けることが重要です。
とにかく触れ
Azureは、技術者だけでなく、あらゆるビジネスの現場で利用されるべきツールです。
学び続けることで、誰でもその力を引き出すことができるようになります。
またAzureに触れ続けることで、個人のスキルだけでなく、チームや企業全体の成長をもたらすことができるでしょう。
習うより慣れろ、その典型が、こういったツールだとも言えそうです。
Day9を受けての総括
クラウドの魅力は、初期投資を最小限にしつつ、迅速に環境を整える力にあります。
小さな船でまず出航し、少しずつ大きな船に乗り換えるように、少しずつスケールアップができるのです。
初めから巨大な船を建造する必要はありません。
もちろん、最終的にはオンプレミスの方が安くなる場合もあるでしょう。
しかし、広大な海のどこに目的地があるか分からないうちは、自前の船で全てをまかなう必要はないのです。
Azureの使用理由についても、初心者には分かりやすく、世界的に人気が高いという点が強調されます。
Microsoft Learnを活用すれば、課金なしでテスト環境を試すことができるのは航海練習をするようなものです。
対照的に、AWSは複雑な装備を持つ豪華な船ですが、初心者にとっては操作が難しく、熟練した船員向けと言えます。
Azureの利用シーンも広がっています。
現在は主にシステム担当者が利用していますが、今後は現場の従業員も積極的に使う時代が来るでしょう。
「Copilot」などのAI機能は、航海のための自動操縦装置のようなもので、技術の壁を取り除き、誰でも使える未来を指し示しています。
これにより、企業全体の効率性と柔軟性が大きく向上するでしょう。
Azure Data Factoryも、膨大なデータの海を航行するための重要なツールです。
多様なデータソースに接続し、データを圧縮・移動し、必要な形に変える機能を持っています。
これにより、企業はデータという無限の資源をうまく活用し、新たな知見を得ることができるのです。
そして何よりも重要なのは、Azureを使い続けることです。
クラウド技術は常に進化しています。
継続的に学び、実際に触れ続けることで得られる知見は多くなります。
技術を学ぶことは、ただの知識の蓄積ではなく、新しい航路を切り開くための準備です。
学び続けることで、あなたはいつでも次の波を乗り越える準備ができるのです。
これは、どんな船乗りにとっても必要な心構えであり、Azureを使う私たちにも当てはまるのではないでしょうか。
<Day10の復習まとめはこちらから>