
【RVC】MacBook Pro 14 (Apple M1)で学習してみたよ

こんにちは、あるいは、こんばんは!
いろいろあり、RVCの続きを進めるのが遅くなってしまいました。
必要に迫られ、時間にも迫られておりますが、備忘録にまとめつつ進めていきます。
RVC-WebUI
前回の記事で導入しました、だだっこぱんだ様のRVC-WebUIを起動して、音声を学習してモデルの作成をしていこうと思います。
RVC-WebUI起動
起動はいたって簡単です。
前回、AnacondaからPython10の環境を用意したのですが、RVC-WebUIの起動では不要でした。
以下のコードを実行します。初回起動に比べて、今回はとても早く処理が進むと思います。
rvc-webuiが格納されているpathは、皆様で異なると思いますので、自身で修正をお願いしますね。わたしはDropbox内に作成しています。
cd /Users/user/Dropbox/GitHub/local/rvc-webui
./webui.sh実行すると以下のように表示されていくと思います。
VSCodeで実施しましたが、ターミナルでも実施できると思います。
(base) user@MBP14 GitHub % cd /Users/user/Dropbox/GitHub/local/rvc-webui
(base) user@MBP14 rvc-webui % ./webui.sh
################################################################
Running on user user
################################################################
################################################################
Create and activate python venv
################################################################
################################################################
Launching launch.py...
################################################################
Python 3.10.13 (main, Sep 11 2023, 08:16:02) [Clang 14.0.6 ]
Commit hash: b71742809a24cd89eb18081b831c0b1ac11ccb2a
Installing requirements
2024-02-03 15:21:26 | INFO | faiss.loader | Loading faiss.
2024-02-03 15:21:26 | INFO | faiss.loader | Successfully loaded faiss.
WARNING: FP16 is not supported on this GPU
/Users/user/Library/CloudStorage/Dropbox/GitHub/local/rvc-webui/modules/shared.py:16: UserWarning: 'has_mps' is deprecated, please use 'torch.backends.mps.is_built()'
if not getattr(torch, "has_mps", False):
Using MPS
/Users/user/Library/CloudStorage/Dropbox/GitHub/local/rvc-webui/modules/tabs/training.py:381: GradioUnusedKwargWarning: You have unused kwarg parameters in Checkbox, please remove them: {'disabled': True}
fp16 = gr.Checkbox(
/Users/user/Library/CloudStorage/Dropbox/GitHub/local/rvc-webui/modules/tabs/server.py:16: GradioDeprecationWarning: The `style` method is deprecated. Please set these arguments in the constructor instead.
with gr.Row().style(equal_height=False):
/Users/user/Library/CloudStorage/Dropbox/GitHub/local/rvc-webui/modules/tabs/server.py:20: GradioDeprecationWarning: The `style` method is deprecated. Please set these arguments in the constructor instead.
with gr.Row().style(equal_height=False):
/Users/user/Library/CloudStorage/Dropbox/GitHub/local/rvc-webui/modules/tabs/server.py:24: GradioDeprecationWarning: The `style` method is deprecated. Please set these arguments in the constructor instead.
with gr.Row().style(equal_height=False):
/Users/user/Library/CloudStorage/Dropbox/GitHub/local/rvc-webui/modules/tabs/server.py:116: GradioDeprecationWarning: The `style` method is deprecated. Please set these arguments in the constructor instead.
with gr.Row().style(equal_height=False):
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.「Running on local URL: http://127.0.0.1:7860」と出ますので、「⌘+左クリック」でブラウザを立ち上げます。

音声データを学習してモデルを作成する(Training)
WebUIの「Training」タブをクリックします。

設定箇所がたくさんあって、難しそうですね。
Trainingの設定
・Model Name: モデル名
・Dataset glob: 音声データセットのパス
・Speaker ID: 話者の識別のためのID 複数を識別させるには数値を設定
0(default)
・Target sampling rate: 音声の周波数
40k(default)が良さそう 48kではerror頻発
・f0 Model: 基本周波数
yes(default)はピッチあり
・Using phone embedder: 事前学習モデルを選択 比べてみると良さそう
hubert-base-japaneseは日本語特化モデル
contentvec(default)
・Embedding channels: 次元の数(精度)
768(default)で実施
・Embedding output layer: 出力層の設定
12(default)
・GPU ID: GPUの設定
空欄(default) Macbook Pro M1では不明のため
・Number of CPU processes: CPUでの処理回数
5(default)
・Normalize audio volume when preprocess: ボリュームの正規化
yes(default)
・Pitch extraction algorithm: ピッチ抽出方法
hervest: 品質最良?リアルタイムは遅延あり
pmは高速, dioは高品質
crepe(default)は高々品質
mangio-crepeはcrepeの改良版
・Batch size: 学習するデータセットの1回あたりの処理量
4(default)
・Number of epochs: 学習の回数
30(default)
100〜200くらいは必要
・Save every epoch: モデルの保存頻度
10(default) PC保存容量の圧迫に注意
・Cash batch: 高速処理
☑(default) チェック
・FP16: 軽量化(品質低下)
□(default) チェックなし
※ 「Train」ボタンクリック後に「error」となることがあり、色々設定をいじってしまい、default設定が表記と異なっているかもしれません。
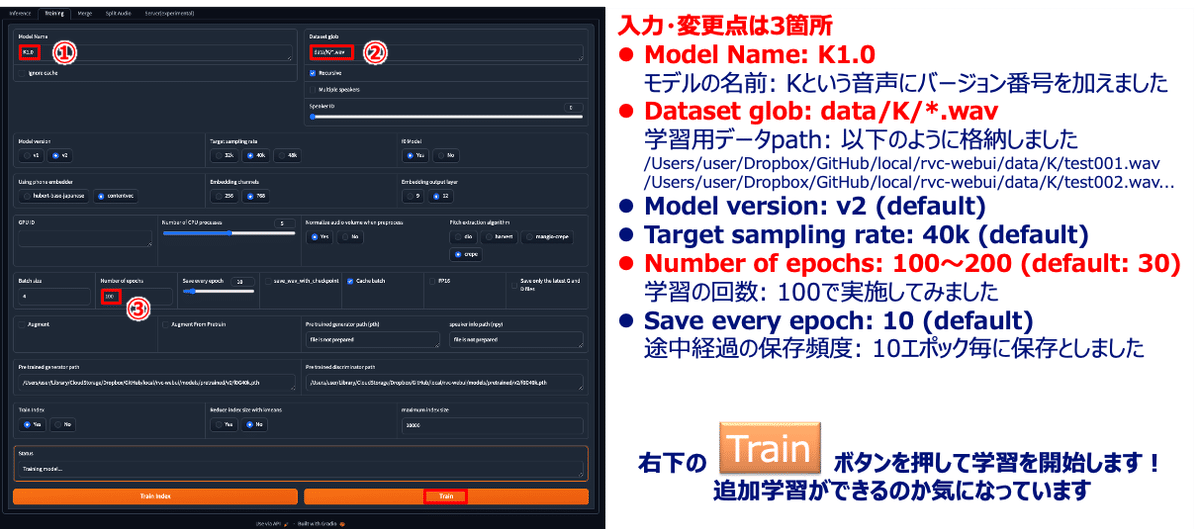
今回、設定箇所は3箇所にしぼって、実施してみたいと思います。
学習用の音声データを準備しておきます。
わたしは、以下のように
「/Users/user/Dropbox/GitHub/local/rvc-webui/data/K」
というフォルダを作成して、音声データを格納しました。
/Users/user/Dropbox/GitHub/local/rvc-webui/data/K/test001.wav
/Users/user/Dropbox/GitHub/local/rvc-webui/data/K/test002.wav
/Users/user/Dropbox/GitHub/local/rvc-webui/data/K/test003.wav
...音声データを録音などして準備する場合には、条件が3つあるようです。
準備するデータは10秒程度の短いもので、30〜40個あると良いようです。
音声データの条件
1)48,000 Hz
2)モノラル
3)「.wav」形式
音声データの長さと数
・10秒程度
・30〜40個
わたしは、以前に撮影した動画の音声を、1人ずつ個別に「.wav」形式で書き出しました。サンプリングレートはよくわからないです。
Adobe Premier Proで音声をモノラルにして、カット編集して地道に書き出しましたので、参考になるかわからないのですがあらためて紹介できればと思います。
学習条件の設定と実行
今回、入力と変更点は3箇所にしました。
①「モデル名」を決めます。
今回はKのバージョン1の初版0として、「K1.0」にしてみました
②「データセットのパス」を指定します。
「/Users/user/Dropbox/GitHub/local/rvc-webui/data/K」以下に格納しておき、ワイルドカード「*」を使用して、「.wav」形式の音声データを読み込めるようにしました。
③「学習の回数」を控えめに100にします。
数を増やしすぎても良くないと思います。
様子をみるため、100にして学習にかかる時間を計測しようと思います。
右下の「Train」ボタンを押して学習を実行します。
生成したモデルの確認
学習が終わると、「/Users/user/Library/CloudStorage/Dropbox/GitHub/local/rvc-webui/models/checkpoints」の中に「K1.0.pth」ができていました!

声質変換
生成した学習モデルを使用して、声質変換を試してみます。
①「Inference」タブ
②「更新」ボタン
③ Model: モデルの選択
K1.0.pthをプルダウンメニューから選択
④ Source Audio: data/H/*.wav
声質変換前のデータパスを入力します
⑤ Transpose: キーの変換
男性から女性: +12, 女性から男性: -12, 同性の変換: 0
⑥ Pitch Extraction Algorithm: ピッチ抽出方法
harvest: 品質重視
⑦⑧⑨: auto
各設定ファイルを自動で認識してくれます
⑩「Infer」ボタンを押して声質変換
変換された音声データは「outputs」フォルダに格納されます

感想
100 epochs(学習時間は約1時間)では、う〜ん、これは声なのか?という出来具合でした。
試しに200 epochs(学習時間は約1時間)でも同様でしたね。
おそらく、もともとのデータセットの質が悪いことが原因かと思いますが、「Using phone embedder:」を「hubert-base-japanese」にしたほうが良いという記事を見かけました。
軽く50 epochsで実施してみたいと思います。
フリー声素材
音声データのサイトを以下に提示させていただきます。
わたしは利用したことはまだないのですが、利用規約を遵守して、ご使用いただければと思います。
展望
モデルの生成まではできるようになりました。
ゆくゆくは、作成したモデルでVG WebUIにてtext to speech (TTS)を動かしたいと考えております。
更新
20240203.1: 初版
おまけ
RVC画像

Negative prompt: (EasyNegative:1.5), (ng_deepnegative_v1_75t:0.75), (worst quality, low quality, normal quality:1.4)
Steps: 20, Sampler: Euler a, CFG scale: 7, Seed: 988825483, Size: 640x335, Model hash: cd8732bdc3, Model: ShiratakiMix-add-VAE, Denoising strength: 0.7, CloneCleaner enabled: True, CC_gender: female, CC_insert_start: True, CC_declone_weight: 1, CC_use_main_seed: True, CC_declone_seed: 2808250294, Hires prompt: "RVC,", Hires upscale: 2, Hires upscaler: Latent, TI hashes: "EasyNegative: c74b4e810b03, ng_deepnegative_v1_75t: 54e7e4826d53", Version: v1.5.1