【Googleタイムライン】端末保存へ移行後のエクスポートデータの解説&Pythonで整形・可視化

Googleのタイムライン(旧名称:ロケーション履歴)のデータは、クラウドではなく端末に保存されることになりました。
この記事では、端末保存に移行したあとのデータエクスポート方法と、エクスポートされるデータについて解説します。また、Pythonでのデータ整形と可視化についても紹介します。
はじめに
2024年6月23日現在、端末保存への移行による不具合の報告が多数あるみたいなので、まだ移行していない人は無理に急いで移行する必要はないと思います。
移行後どうなったか
位置情報の精度が著しく落ちた、といった報告をXで見かけましたが、私の場合は移動手段など多少おかしい部分はありますが前からこんなものだった気もして、まだ精度の著しい低下は感じられてないです。
(6/24追記:私は今年の1月に移行したのですが、移行直後の記録を見返したら、3月末くらいまで移動手段と移動距離が結構おかしくなってました。例えば25kmほどの位置情報の変化があるのに、移動距離の表示が数kmだったり移動手段が違ったり。4月くらいからある程度まともに戻ってそうな感じでした。)
ただ、下記の記事で紹介したような「Google データエクスポート」で取れていたjsonデータは取れなくなりました。(Timeline Edits.jsonというタイムライン編集履歴と思しきファイルだけはエクスポートできました。)
移行後は、移行前に取れていたjsonが簡略化されたようなデータが端末からエクスポートできるようになります。
移行後のデータエクスポート方法
次のような手順でタイムラインの情報をjson形式でエクスポートできます。
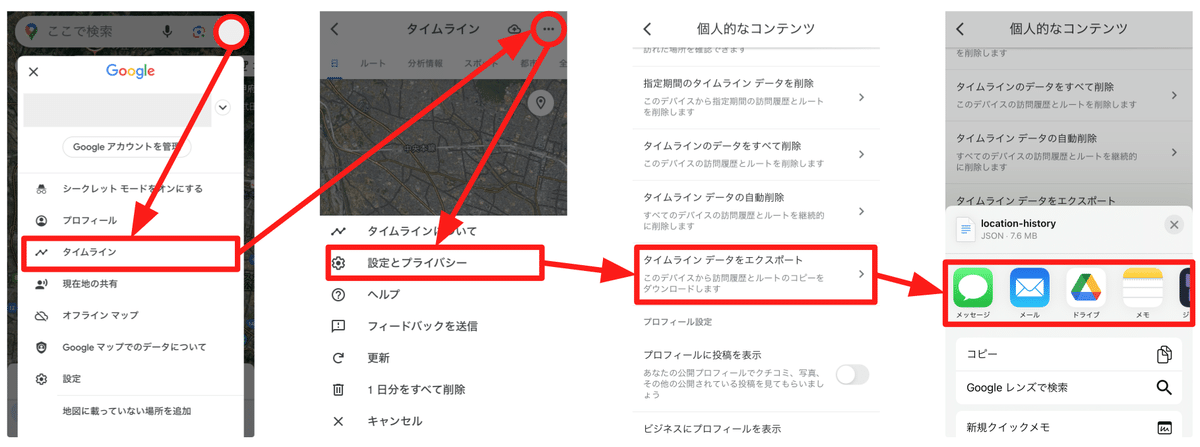
最後はGoogleドライブなど任意のエクスポート先を選択
移行後にエクスポートされるjsonの中身
こんな感じのjsonデータが取得できます。
{
"endTime": "2019-03-22T13:26:00.998+09:00",
"startTime": "2019-03-22T13:20:20.999+09:00",
"activity": {
"end": "geo:32.734080,129.869521",
"topCandidate": {
"type": "walking",
"probability": "0.000000"
},
"distanceMeters": "318.000000",
"start": "geo:32.736933,129.869771"
}
},
{
"endTime": "2019-03-22T16:51:28.999+09:00",
"startTime": "2019-03-22T13:26:00.998+09:00",
"visit": {
"hierarchyLevel": "0",
"topCandidate": {
"probability": "0.249804",
"semanticType": "Unknown",
"placeID": "ChIJ34BEgoRTFTURm9sPe3FbyOs",
"placeLocation": "geo:32.734331,129.869189"
},
"probability": "0.740000"
}
},このjsonは辞書のリストになっています。一つの辞書は次の構成をとります。
startTime
endTime
下記のいずれか
timelinePath:各時点の位置情報
timelineMemory:思い出(長距離移動?)の記録
activity:移動手段と位置情報
visit:訪問地の位置情報
各アイテムの詳細
timelinePath:各時点の位置情報
durationMinutesOffsetFromStartTime
point(緯度経度)
timelineMemory:思い出(長距離移動?)の記録
destinations(市区町村レベルのplaceID)
distanceFromOriginKms(起点(自宅?)からの距離)
activity:移動手段と移動距離と開始終了緯度経度
distanceMeters
probability
start(開始緯度経度)
end(終了緯度経度)
topCandidate
type(移動手段)
probability
visit:訪問地
hierarchyLevel
probability
topCandidate
probability
semanticType(自宅か職場かなど)
placeID
placeLocation(緯度経度)
startTimeとendTimeについて補足
timelinePathのみUTCで時間(hour)までの粒度
YYYY-MM-DDThh:00:00.000Z
そのほかは現地時刻でミリ秒単位の粒度
YYYY-MM-DDThh:mm:ss.sss+hh:mm
placeIDは場所に割り当てられるIDで、GoogleのAPIを使うと場所名などを取得することができます。
Pythonコード
アイテムごとにpandasのDataFrameに変換するコードを書きました。
これにより、各アイテムをテーブル形式に変換できます。
import pandas as pd
df = pd.read_json("location-history.json")
df["tz_info"]=df["startTime"].str[23:]
df["endTime"] = pd.to_datetime(df["endTime"].str[:23])
df["startTime"] = pd.to_datetime(df["startTime"].str[:23])
df.set_index(["endTime","startTime","tz_info"],inplace=True)
# timelinePath
tp = df["timelinePath"].dropna()
tp = pd.json_normalize(tp.explode()).set_index(tp.explode().index)
tp[["path_lat","path_lon"]] = tp["point"].str[4:].str.split(",",expand=True).astype(float)
tp = tp.drop(["point"],axis=1).reset_index()
tp["durationMinutesOffsetFromStartTime"]=tp["durationMinutesOffsetFromStartTime"].astype(int)
tp["pointTime"]=(
tp["startTime"] # startTime+durationMinutesOffsetFromStartTime時点でその緯度経度に居たと解釈する
+pd.to_timedelta(tp["durationMinutesOffsetFromStartTime"],unit='minute')
+pd.to_timedelta(9,unit='hour') # 日本時間に変換する
)
tp["prevTime"]=tp["pointTime"].shift() # 直前の時刻を示す列も用意しておく
# timelineMemory
tm = df["timelineMemory"].dropna()
tm = pd.json_normalize(tm).set_index(tm.index).explode("destinations")
tm["destinations"]=tm["destinations"].map(lambda x: x["identifier"])
tm["distanceFromOriginKms"]=tm["distanceFromOriginKms"].astype(int)
tm.reset_index(inplace=True)
# activity
ac = df["activity"].dropna()
ac = pd.json_normalize(ac).set_index(ac.index)
ac[["start_lat","start_lon"]]=ac["start"].str[4:].str.split(",",expand=True).astype(float)
ac[["end_lat","end_lon"]]=ac["end"].str[4:].str.split(",",expand=True).astype(float)
ac.drop(["start","end"],axis=1,inplace=True)
ac["distanceMeters"]=ac["distanceMeters"].astype(float)
ac.reset_index(inplace=True)
# visit
vt = df["visit"].dropna()
vt = pd.json_normalize(vt).set_index(vt.index)
vt[["place_lat","place_lon"]]=vt["topCandidate.placeLocation"].str[4:].str.split(",",expand=True).astype(float)
vt.drop(["topCandidate.placeLocation"],axis=1,inplace=True)
vt["hierarchyLevel"]=vt["hierarchyLevel"].astype(int)
vt["topCandidate.probability"]=vt["topCandidate.probability"].astype(float)
vt.reset_index(inplace=True)それぞれ次のようなデータフレームが生成されます。




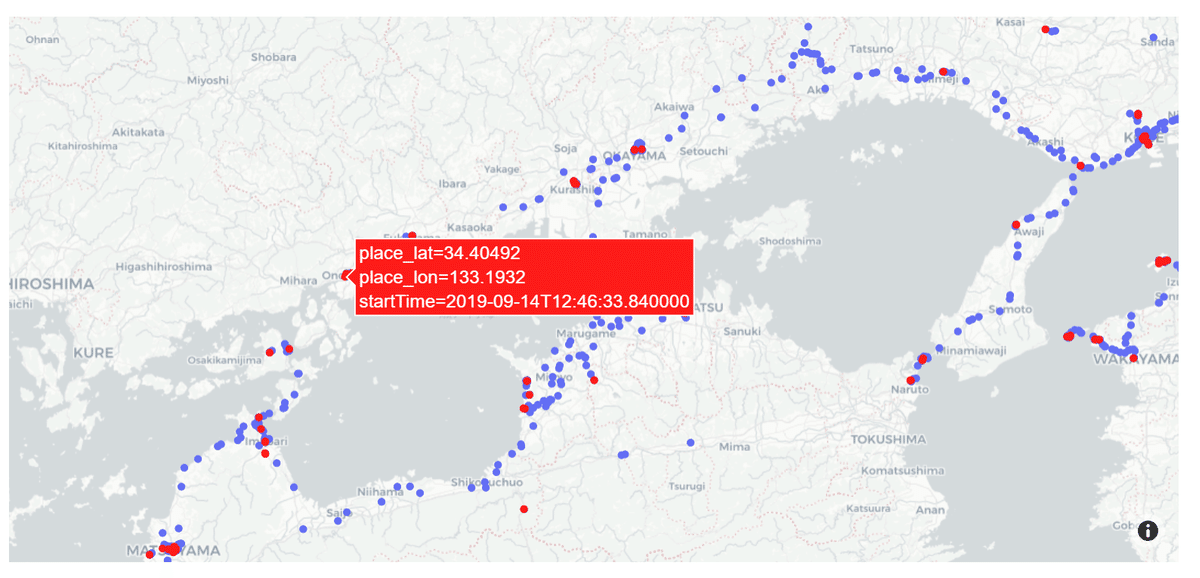
可視化
試しに、timelinePathとvisitのデータを可視化してみました。
import plotly.express as px
fig1 = px.scatter_mapbox(tp,lat='path_lat',lon='path_lon',mapbox_style ='carto-positron')
fig2 = px.scatter_mapbox(vt,lat='place_lat',lon='place_lon',hover_data=["startTime"],mapbox_style ='carto-positron')
fig2.update_traces(marker=dict(color='red'))
fig1.add_traces(fig2.data)