翻訳:LLM Evaluation Metrics: The Ultimate LLM Evaluation Guide

この記事は、先進的な LLM Evaluation プラットフォームである Confident AI を提供する Jeffrey Ip より許諾を受け、彼が執筆した 「LLM Evaluation Metrics: The Ultimate LLM Evaluation Guide」を日本語に翻訳したものです。対応に注意して翻訳していますが、本記事と原文に差異がある場合、常に原文が正しいです。

大規模言語モデル(LLM)の出力評価は、信頼性の高いLLMアプリケーションを開発・提供する上で不可欠なプロセスですが、多くの開発者にとって依然として困難な課題となっています。モデルの精度をファインチューニングで改善する場合でも、RAG(Retrieval-Augmented Generation)システムの文脈的な関連性を高める場合でも、ユースケースに合った評価指標を開発し、選定する方法を理解することは、信頼性の高いLLM評価プロセスを構築するうえで欠かせません。
この記事では、LLMの評価指標について必要な知識をすべて学べるよう、コードサンプル付きで解説します。以下の内容を深掘りしていきます:
LLMの評価指標とは何か、それを使ってLLMシステムをどのように評価するのか、そしてよくある落とし穴や、優れた評価指標がそうである理由。
LLM評価指標をスコアリングするさまざまな方法と、その中でも「LLM-as-a-judge」が評価に最適とされる理由。
DeepEval(⭐https://github.com/confident-ai/deepeval)を使い、コードで適切なLLM評価指標を実装・選定する方法。
長いリストを読む準備はできていますか?それでは始めましょう!
(追記:LLMチャットボットや会話を評価する指標を探している方は、新しい記事もぜひチェックしてみてください!)
LLM評価指標とは何ですか?
LLM評価指標とは、回答の正確性、意味的な類似性、幻覚(誤生成)など、重要な基準に基づいてLLMシステムの出力を評価するための指標です。これらはLLMの評価において欠かせないもので、異なるLLMシステム(場合によってはLLMそのもの)のパフォーマンスを定量化するのに役立ちます。

以下は、LLMシステムを本番環境に投入する前に必要となる、最も重要で一般的な評価指標です:
回答の関連性: LLMの出力が、与えられた入力に対して情報的で簡潔に応答できているかを判断します。
正確性: LLMの出力が、何らかの正解データ(グラウンドトゥルース)に基づいて事実として正しいかを判断します。
ハルシネーション(誤生成): LLMの出力に虚偽や作り話の情報が含まれていないかを判断します。
文脈的関連性: RAGベースのLLMシステムにおいて、リトリーバーがLLMにとって最も関連性の高い情報を文脈として抽出できているかを判断します。
責任ある指標: バイアスや有害性などの指標を含み、LLMの出力に一般的に有害または攻撃的な内容が含まれていないかを判断します。
タスク固有の指標: 要約などのタスクを含み、通常はユースケースに応じたカスタム基準を使用します。
ほとんどの評価指標は汎用的で必要不可欠ですが、特定のユースケースをターゲットにするには十分ではありません。そのため、少なくとも1つのカスタムタスク固有の評価指標を導入することで、LLM評価パイプラインを本番環境に対応できる状態にする必要があります(この後のG-Evalセクションで詳しく説明します)。たとえば、LLMアプリケーションがニュース記事を要約するために設計されている場合、次のような基準でスコアリングを行うカスタム評価指標が必要になります:
要約が元のテキストから十分な情報を含んでいるか。
要約が元のテキストと矛盾している部分や幻覚(誤生成)を含んでいないか。
さらに、LLMアプリケーションがRAGベースのアーキテクチャを持つ場合、リトリーバーが提供する文脈の品質についても評価する必要があるでしょう。要するに、LLM評価指標は、そのアプリケーションが設計されたタスクに基づいてLLMを評価するものです。(なお、LLMアプリケーションは単にLLMそのものを指す場合もあります!)
優れた評価指標の特徴は以下の通りです:
定量的であること
評価指標は、対象のタスクを評価する際に必ずスコアを算出する必要があります。このアプローチにより、LLMアプリケーションが「十分に良い」と判断できる最低合格基準を設定できるほか、実装を改善していく中でスコアの変化を継続的にモニタリングすることが可能になります。信頼性が高いこと
LLMの出力が予測不能なことがある中で、評価指標まで同じように不安定では困ります。そのため、G-Evalのような「LLMを評価者とする手法」(LLM-as-a-judgeまたはLLM-Evals)は、従来のスコアリング方法より正確である一方、一貫性に欠けることが多いのが課題です。これは多くのLLM-Evalが直面する弱点でもあります。正確であること
信頼性のあるスコアであっても、それがLLMアプリケーションのパフォーマンスを正確に反映していなければ意味がありません。優れたLLM評価指標をさらに高品質なものにする秘訣は、人間の期待と可能な限り一致させることです。
では、LLM評価指標はどのようにして信頼性が高く正確なスコアを算出できるようになるのでしょうか?
指標スコアを算出するさまざまな方法
以前の記事で、LLMの出力を評価するのがいかに困難かについて触れましたが、幸いにも、指標スコアを算出するための確立された方法が数多く存在します。一部の方法は埋め込みモデルやLLMなどのニューラルネットワークを利用し、他の方法は完全に統計分析に基づいています。

これらの方法を一つずつ解説し、このセクションの最後に最適なアプローチを紹介しますので、ぜひ最後までお読みください!
統計的スコアリング
まず最初にお伝えしたいのは、統計的スコアリング手法は必須の知識ではないということです。急いでいる場合は「G-Eval」のセクションに直接進んでいただいて構いません。理由としては、統計的手法は推論を必要とする場面ではパフォーマンスが悪く、ほとんどのLLM評価基準においてスコアリングとして不正確すぎるためです。
以下に簡単に説明します:
BLEU(BiLingual Evaluation Understudy):
LLMの出力をアノテーション済みの正解データ(期待される出力)と比較し、マッチするn-gram(連続するn個の単語)の精度を計算して幾何平均を算出します。必要に応じて簡潔性ペナルティも適用されます。ROUGE(Recall-Oriented Understudy for Gisting Evaluation):
主にNLPモデルによるテキスト要約の評価に使われ、LLMの出力と期待される出力間のn-gramの重なりを比較してリコールを計算します。リファレンス内のn-gramのうち、LLM出力に含まれる割合(0~1)を評価します。METEOR(Metric for Evaluation of Translation with Explicit Ordering):
精度(n-gramの一致)とリコール(n-gramの重なり)の両方を評価し、語順の違いを調整してスコアを計算する、より包括的な手法です。WordNetのような外部の言語データベースを活用して同義語も考慮し、精度とリコールの調和平均を最終スコアとして計算し、語順の違いにはペナルティを与えます。レーベンシュタイン距離(編集距離):
1つの単語や文字列を別のものに変換するために必要な最小の単文字編集数(挿入、削除、置換)を計算します。スペル修正や文字単位の整合性が重要なタスクの評価に役立ちます。
純粋な統計的スコアリングは意味をほとんど考慮せず、推論能力も極めて限られているため、長く複雑なLLMの出力を評価するには十分な精度を持ちません。
モデルベースのスコアリング
純粋に統計的なスコアリングは信頼性は高いものの、意味を考慮するのが苦手なため精度に欠けます。一方、このセクションで紹介するモデルベースのスコアリングはその逆で、NLPモデルに完全に依存するため精度は比較的高いものの、確率的な性質ゆえに信頼性が低い傾向があります。
これは驚くべきことではありませんが、LLMベースではないスコアリングは「LLM-as-a-judge」と比べてパフォーマンスが劣ります。その理由は、統計的スコアリングと同じく、意味や文脈を十分に考慮できないためです。LLMベースではないスコアリングには以下が含まれます:
NLIスコアリング
自然言語推論(NLI)モデル(NLPの分類モデルの一種)を使用し、LLMの出力がリファレンステキストに対して論理的に一貫している(含意)、矛盾している(矛盾)、または無関係(中立)であるかを分類します。スコアは通常、含意(1)から矛盾(0)の範囲で提供され、論理的一貫性を測定します。BLEURTスコアリング
BERTのような事前学習済みモデルを利用し、LLMの出力を期待される出力と比較してスコアを算出します。
一貫性のないスコア以外にも、これらの手法にはいくつかの欠点があります。たとえば、NLIスコアリングは長いテキストを処理する際に精度が低下することがあり、BLEURTはその学習データの品質や代表性に制約されます。
では次に、「LLM-as-a-judge」について話していきましょう。
G-Eval
G-Evalは、「NLG Evaluation using GPT-4 with Better Human Alignment」という論文で提案された最新のフレームワークで、LLMを用いてLLMの出力を評価する(いわゆるLLM-Evals)手法です。G-Evalはタスク固有の評価指標を作成する最良の方法の一つとされています。
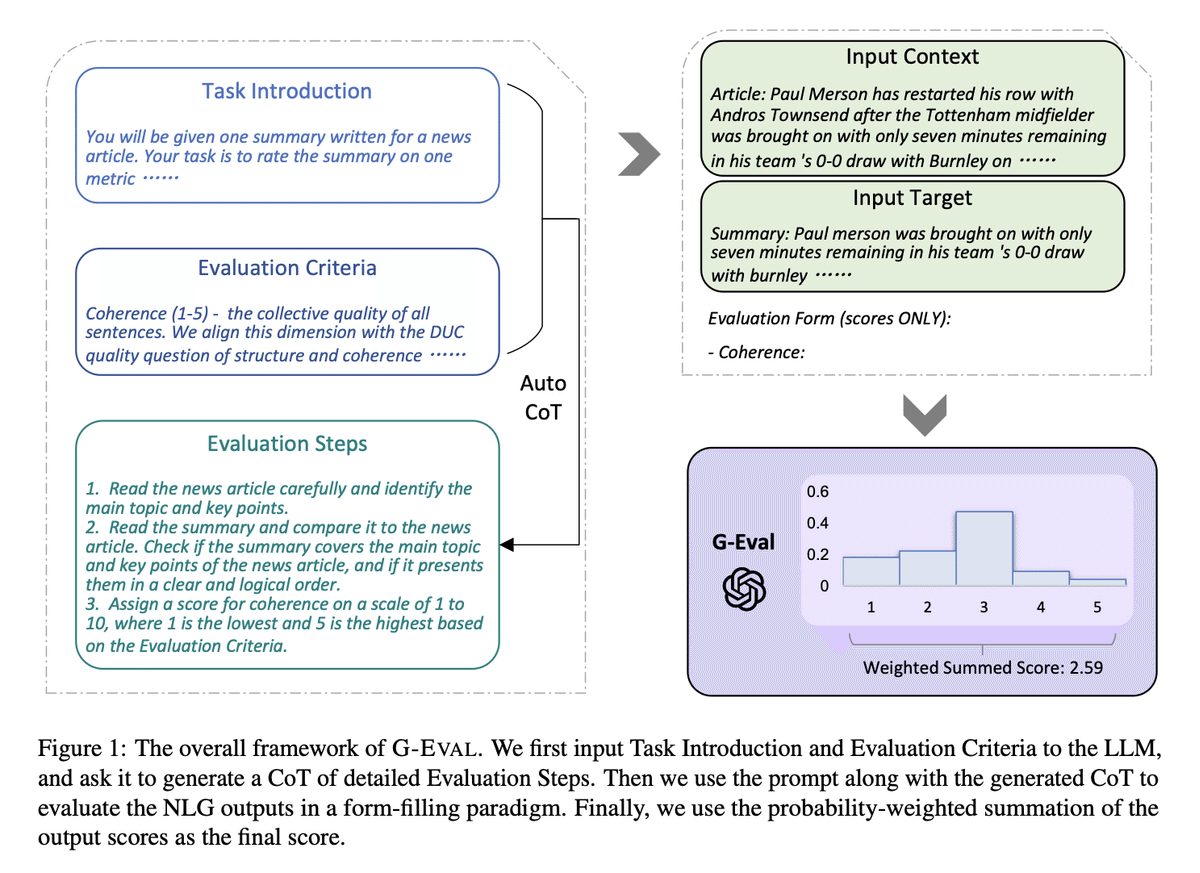
以前の記事で紹介したように、G-Evalはまず「思考の連鎖(CoT: Chain of Thoughts)」を用いて一連の評価ステップを生成し、その生成されたステップを使ってフォーム入力形式で最終的なスコアを決定します(簡単に言えば、G-Evalは評価に複数の情報が必要だということです)。
たとえば、G-Evalを使ってLLMの出力の一貫性を評価する場合、評価基準と評価対象のテキストを含むプロンプトを作成し、それを基に評価ステップを生成します。その後、LLMを用いてこれらのステップに基づいて1~5のスコアを出力します。
この例を使ってG-Evalのアルゴリズムを見ていきましょう。まず、評価ステップを生成する手順です:
評価タスクを選択したLLMに提示する(例:「この出力を一貫性に基づいて1~5で評価してください」)。
評価基準の定義を与える(例:「一貫性 - 出力内のすべての文が全体として調和している品質」)。
(補足:元のG-Eval論文では、著者らは実験にGPT-3.5とGPT-4のみを使用しており、私自身もさまざまなLLMでG-Evalを試した結果、これらのモデルを使用することを強くお勧めします。)
評価ステップを一連で生成した後:
評価ステップと、評価ステップで必要なすべての引数を結合してプロンプトを作成します(例:LLMの出力の一貫性を評価する場合、LLM出力が必要な引数になります)。
プロンプトの最後に「1~5のスコアを生成してください。5が最良、1が最悪です」と指示を追加します。
(任意)LLMの出力トークンの確率を取得し、スコアを正規化した上で、それらを加重平均して最終的な結果とします。
ステップ3は任意です。理由として、出力トークンの確率を取得するには、モデルの生データである埋め込み情報へのアクセスが必要であり、これはすべてのモデルインターフェースで利用可能とは限らないためです。しかし、このステップは論文で紹介されており、より細かいスコアを提供し、LLMスコアリングのバイアスを最小化する利点があります。(論文によれば、「3」は1~5のスケールでトークン確率が高い傾向があることが知られています。)
以下は論文から得られた結果で、G-Evalがこの記事で前述した従来の非LLM評価手法をすべて上回る性能を示していることを示しています:

G-Evalが優れている理由は、LLM-EvalとしてLLMの出力を完全に意味的に理解できるため、非常に高い精度を実現できる点にあります。これは理にかなっています。LLMよりもはるかに能力が劣るスコアリング手法を使う非LLM評価が、LLMによって生成されたテキストの全体像を正しく理解できるはずがないからです。
G-Evalは他の手法と比べて人間の判断との相関が非常に高いものの、LLMにスコアを出させるという性質上、どうしても主観的であり、信頼性に欠ける場合があります。
とはいえ、G-Evalの評価基準の柔軟性を考えて、私は個人的にG-Evalを、現在開発中のオープンソースLLM評価フレームワーク「DeepEval」の指標として実装しました(この実装には、論文に記載されている正規化技術も含まれています)。
# Install
pip install deepeval
# Set OpenAI API key as env variable
export OPENAI_API_KEY="..."from deepeval.test_case import LLMTestCase, LLMTestCaseParams
from deepeval.metrics import GEval
test_case = LLMTestCase(input="input to your LLM", actual_output="your LLM output")
coherence_metric = GEval(
name="Coherence",
criteria="Coherence - the collective quality of all sentences in the actual output",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
coherence_metric.measure(test_case)
print(coherence_metric.score)
print(coherence_metric.reason)LLM-Evalを使用するもう一つの大きな利点は、LLMが評価スコアの理由を生成できる点です。
Prometheus
Prometheusは完全にオープンソースのLLMで、適切な参照資料(正解例や評価基準)が提供されると、GPT-4の評価能力に匹敵する性能を発揮します。また、G-Evalと同様にユースケースに依存しない汎用性を持っています。Prometheusは、Llama-2-Chatをベースモデルとして使用し、Feedback Collection内でGPT-4が生成した10万件のフィードバックをもとにファインチューニングされています。
以下は、Prometheusの研究論文に記載された結果の概要です。

Prometheusは、より具体的で一般的ではないフィードバックを生成しますが、過度に批判的なフィードバックを書きがちな傾向があります。
PrometheusとG-Evalの違い
PrometheusはG-Evalと同じ原則に基づいていますが、いくつかの違いがあります:
モデルの違い
G-EvalはGPT-3.5/4を使用するフレームワークであるのに対し、Prometheusは評価専用にファインチューニングされたLLMです。評価手順の生成方法
G-EvalではCoT(Chain-of-Thought)を使ってスコアのルーブリックや評価手順を生成しますが、Prometheusではルーブリックがプロンプト内で提供されます。リファレンスの必要性
Prometheusでは、参照例や評価結果が必要です。
なお、私自身はPrometheusを試したことがありませんが、Hugging Faceで利用可能です。ただし、Prometheusは評価をオープンソース化することを目的として設計されており、OpenAIのGPTのような独自モデルに依存しないようになっています。そのため、最高のLLM-Evalsを構築することを目指す場合には適合しないと判断しました。
統計的手法とモデルベース手法の組み合わせ
ここまでで、統計的手法は信頼性が高いものの精度に欠ける一方、LLMを用いないモデルベース手法は信頼性が低いものの精度が高いことを見てきました。これを踏まえて、次のような非LLMスコアリング手法も存在します:
BERTScore
事前学習済みのBERTのような言語モデルを利用し、リファレンスと生成されたテキスト内の単語の文脈的埋め込み間のコサイン類似度を計算します。これらの類似度を集約して最終的なスコアを算出します。スコアが高いほど、LLMの出力とリファレンステキストの間に意味的な重なりが多いことを示します。MoverScore
BERTのような事前学習済みの言語モデルを使用して、リファレンステキストと生成されたテキストの深く文脈化された単語埋め込みを取得します。その後、「Earth Mover's Distance(EMD)」を用いて、LLM出力内の単語分布をリファレンステキストの単語分布に変換するために必要な最小コストを計算します。
BERTScoreやMoverScoreのスコアリングは、BERTのような事前学習済みモデルの文脈的埋め込みに依存しているため、文脈認識やバイアスの影響を受けやすいという脆弱性があります。では、LLM-Evalsはどうでしょうか?
GPTScore
G-Evalがフォーム入力形式で直接評価タスクを実行するのとは異なり、GPTScoreはターゲットテキストを生成する条件付き確率を評価指標として使用します。

SelfCheckGPT
SelfCheckGPTは少し変わったアプローチで、LLMの出力をファクトチェックするためのシンプルなサンプリングベースの手法です。この手法では、ハルシネーション(誤生成)された出力は再現性がないと仮定します。一方で、LLMがある概念について知識を持っている場合、サンプリングされた複数の応答は似た内容になり、一貫した事実を含むとされています。
SelfCheckGPTの注目すべき点は、幻覚を検出する際にリファレンス(参照データ)が不要であることです。これは、本番環境で非常に有用な特性です。

しかし、G-EvalやPrometheusがユースケースに依存しない汎用的な手法であるのに対し、SelfCheckGPTはそうではありません。SelfCheckGPTは幻覚検出にのみ適しており、要約や一貫性の評価など、他のユースケースには適用できません。
QAG Score
QAG(Question Answer Generation)Scoreは、LLMの高い推論能力を活用して、LLMの出力を信頼性高く評価するためのスコアリング手法です。生成された質問や事前に設定された質問に対して、閉じた形式の回答(通常「はい」または「いいえ」)を使って最終的な指標スコアを計算します。この手法が信頼性に優れている理由は、LLMを直接スコア生成に使用しない点にあります。
たとえば、忠実性(LLMの出力が幻覚でないかどうかを測る指標)のスコアを計算したい場合、次のように進めます:
LLMを使用して、出力内のすべての主張を抽出する。
各主張に対して、グラウンドトゥルース(正解データ)にその主張に同意するか(「はい」)、同意しないか(「いいえ」)を尋ねる。
たとえば、このようなLLM出力の場合:
マーティン・ルーサー・キング・ジュニアは、著名な公民権運動の指導者であり、1968年4月4日にテネシー州メンフィスのロレイン・モーテルで暗殺されました。彼はストライキ中の清掃作業員を支援するためにメンフィスを訪れており、モーテルの2階バルコニーに立っていた際に、脱獄囚のジェームズ・アール・レイによって致命的な銃撃を受けました。
主張の例:
「マーティン・ルーサー・キング・ジュニアは1968年4月4日に暗殺された」
対応する閉じた形式の質問:
「マーティン・ルーサー・キング・ジュニアは1968年4月4日に暗殺されましたか?」
この質問をグラウンドトゥルースに基づいて検証し、その主張に同意するか(「はい」)、同意しないか(「いいえ」)を確認します。最終的に「はい」と「いいえ」の回答数が得られるので、それを用いて選んだ数学的な計算式でスコアを算出します。
忠実性の場合、これを「LLM出力内の主張のうち、グラウンドトゥルースと一致し正確である主張の割合」と定義すれば、簡単に計算できます。具体的には、正確な主張(真実な主張)の数を、LLMが行った主張の総数で割ることで求められます。この手法では、評価スコアを直接生成するためにLLMを使用するわけではなく、その優れた推論能力を活用するため、スコアは正確で信頼性の高いものとなります。
評価指標の選択
どのLLM評価指標を使用するかは、LLMアプリケーションのユースケースやアーキテクチャに依存します。
たとえば、OpenAIのGPTモデルを基盤にしたRAGベースのカスタマーサポートチャットボットを構築している場合は、忠実性(Faithfulness)、回答の関連性(Answer Relevancy)、文脈的精度(Contextual Precision)などのRAG指標が必要になります。一方で、独自のMistral 7Bモデルをファインチューニングしている場合は、公平なLLMの判断を保証するためにバイアスの指標が必要です。
この最終セクションでは、知っておくべき重要な評価指標について解説します。(さらに、その各指標の実装方法もボーナスとしてご紹介します!)
RAG指標
RAG(Retrieval Augmented Generation)についてよく知らない方はこちらの記事が参考になります。ただし、簡単に言えば、RAGはLLMに追加の文脈を提供してカスタマイズされた出力を生成するための手法であり、特にチャットボットの構築に適しています。RAGは以下の2つのコンポーネントで構成されています:
リトリーバー(Retriever)
必要な情報を検索して文脈として提供します。ジェネレーター(Generator)
提供された文脈を基に、具体的で目的に応じた出力を生成します。
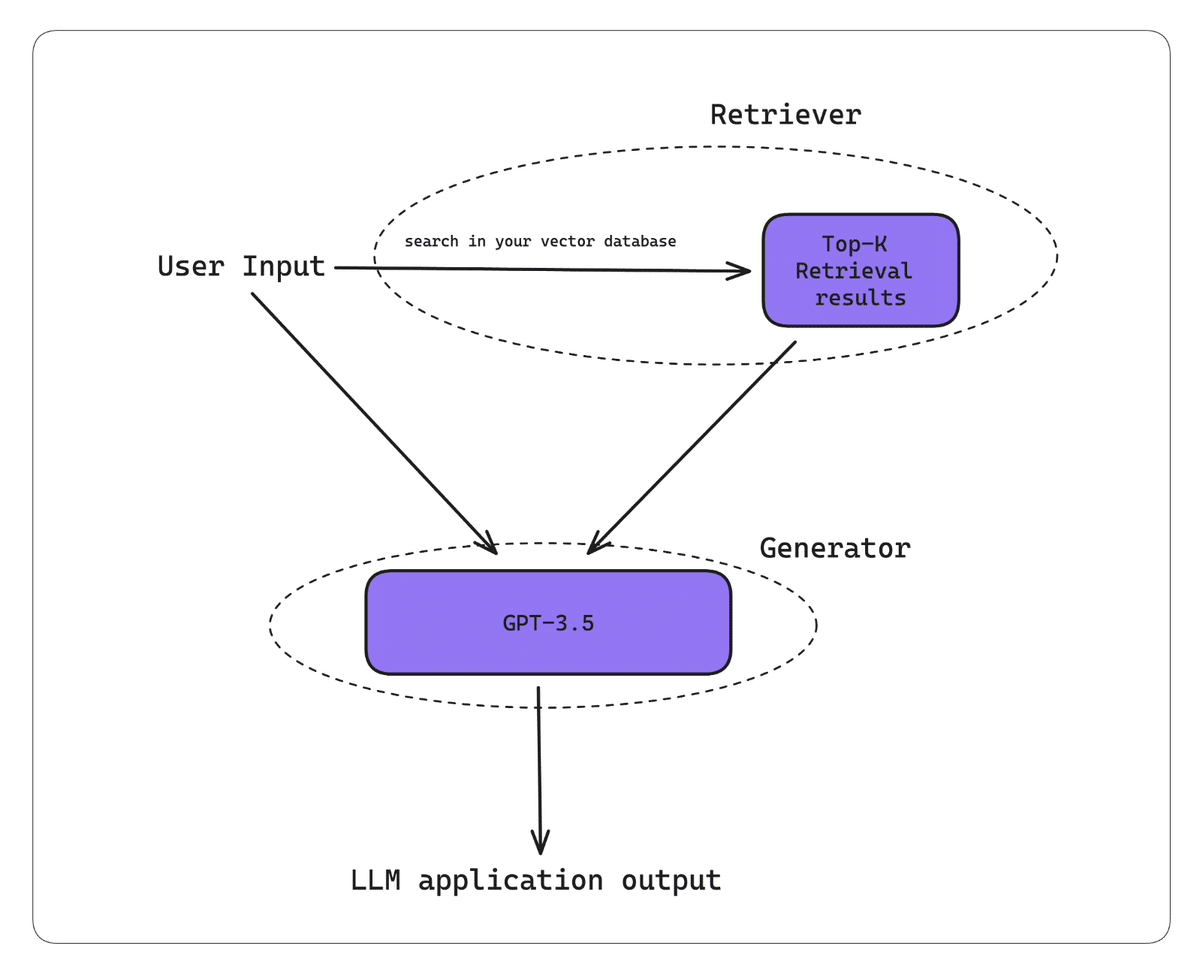
RAGワークフローの基本的な流れ
RAGシステムが入力を受け取る
ユーザーの入力がシステムに提供されます。リトリーバーがベクトル検索を実行する
入力をもとに、ナレッジベース(多くの場合、ベクトルデータベース)内でベクトル検索を行い、関連情報を取得します。ジェネレーターが文脈を利用して出力を生成する
リトリーバーから取得した文脈とユーザーの入力を基に、目的に応じたカスタマイズされた出力を生成します。
覚えておくべきこと ー 高品質なLLM出力は、優れたリトリーバーとジェネレーターの組み合わせによって生まれます。このため、優れたRAG指標は、リトリーバーまたはジェネレーターのいずれかを信頼性高く正確に評価することに重点を置いています。(実際、RAG指標はもともとリファレンス不要な評価指標として設計されており、グラウンドトゥルースを必要としないため、本番環境でも利用可能です。)
特に、RAG指標はもともとリファレンス(正解データ)不要な評価指標として設計されており、グラウンドトゥルースが必要ないため、本番環境でも利用可能です。
PS: CI/CDパイプラインでRAGシステムを単体テストしたい方はこちらをクリックしてください。
忠実性(Faithfulness)
忠実性は、RAG指標の一つであり、RAGパイプラインのLLM/ジェネレーターが、リトリーバーから提供された文脈情報と事実的に一致したLLM出力を生成しているかを評価します。しかし、この忠実性指標にはどのスコアリング手法を使うべきでしょうか?
ネタバレ注意: QAGスコアリングはRAG指標に最適なスコアリング手法です。特に、評価タスクの目的が明確な場合に優れた性能を発揮します。忠実性を「リトリーバーから得た文脈情報に基づいてLLM出力内で行われた真実の主張の割合」と定義する場合、以下のアルゴリズムを使用してQAGで忠実性を計算できます:
QAGを使用した忠実性の計算手順
出力内のすべての主張を抽出する
LLMを使用して、LLM出力に含まれるすべての主張を特定します。各主張を検証する
各主張に対して、リトリーバーから取得された文脈(リトリーバルコンテキスト)の各ノードと一致するか、矛盾するかを確認します。この場合、QAGでの閉じた形式の質問は次のようになります:「この主張はリファレンステキストと一致していますか?」
ここで「リファレンステキスト」は取得された各ノードを指します。
スコアを計算する
真実とみなされる主張(「はい」および「idk」)の総数を合計します。
その合計をLLM出力内で行われた主張の総数で割ります。
この方法は、LLMの高度な推論能力を活用しつつ、LLMが直接生成するスコアの信頼性の低さを回避するため、G-Evalよりも優れたスコアリング手法といえます。
もしこの方法を実装するのが難しいと感じる場合は、DeepEvalを使用することをお勧めします。これは私が作成したオープンソースのパッケージで、忠実性指標を含む、LLM評価に必要なすべての評価指標を提供しています。
# Install
pip install deepeval
# Set OpenAI API key as env variable
export OPENAI_API_KEY="..."from deepeval.metrics import FaithfulnessMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = FaithfulnessMetric(threshold=
0.5
)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())DeepEvalでは、評価をテストケースとして扱います。ここで、actual_output は単にLLMの出力を指します。また、忠実性はLLM-Evalとして実施されるため、最終的なスコアが算出される際にその理由付けも得ることができます。
回答の関連性(Answer Relevancy)
回答の関連性は、RAGジェネレーターが簡潔な回答を生成しているかを評価するRAG指標であり、LLM出力内の文のうち、入力に関連する文の割合を計算することで求めることができます(つまり、関連する文の数を全体の文の数で除算します)。
強固な回答関連性指標を構築する鍵は、リトリーバルコンテキストを考慮することです。追加の文脈情報が、一見無関係に見える文の関連性を正当化する場合があるためです。以下に回答関連性指標の実装例を示します:
from deepeval.metrics import AnswerRelevancyMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = AnswerRelevancyMetric(threshold=
0.5
)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())(覚えておいてください、RAG指標にはすべてQAGを使用します)
文脈的精度(Contextual Precision)
文脈的精度は、RAGパイプラインのリトリーバーの品質を評価するRAG指標です。文脈的指標について話す場合、主にリトリーバルコンテキストの関連性に焦点を当てます。文脈的精度スコアが高いということは、リトリーバルコンテキスト内で関連性の高いノードが、関連性の低いノードよりも上位にランク付けされていることを意味します。
これは重要なポイントです。なぜなら、LLMはリトリーバルコンテキスト内で先に登場するノードの情報により大きな重みを与えるため、これが最終的な出力の品質に影響を与えるからです。
from deepeval.metrics import ContextualPrecisionMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Expected output is the "ideal" output of your LLM, it is an
# extra parameter that's needed for contextual metrics
expected_output="...",
retrieval_context=["..."]
)
metric = ContextualPrecisionMetric(threshold=
0.5
)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())文脈的リコール(Contextual Recall)
文脈的リコールは、Retriever-Augmented Generator(RAG)を評価するための追加指標です。期待される出力またはグラウンドトゥルース内の文のうち、リトリーバルコンテキスト内のノードに帰属できる文の割合を計算することで求められます。
スコアが高いほど、取得された情報と期待される出力との整合性が高いことを示し、リトリーバーがジェネレーターに対して文脈的に適切な応答を生成するための関連性の高い正確な情報を効果的に提供していることを意味します。
from deepeval.metrics import ContextualRecallMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Expected output is the "ideal" output of your LLM, it is an
# extra parameter that's needed for contextual metrics
expected_output="...",
retrieval_context=["..."]
)
metric = ContextualRecallMetric(threshold=
0.5
)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())文脈的関連性(Contextual Relevancy)
おそらく最も理解しやすい指標である文脈的関連性は、リトリーバルコンテキスト内の文のうち、与えられた入力に関連している文の割合を指します。
from deepeval.metrics import ContextualRelevancyMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
retrieval_context=["..."]
)
metric = ContextualRelevancyMetric(threshold=
0.5
)
metric.measure(test_case)
print(metric.score)
print(metric.reason)
print(metric.is_successful())ファインチューニング指標(Fine-Tuning Metrics)
「ファインチューニング指標」とは、システム全体ではなくLLMそのものを評価する指標を指します。コストやパフォーマンスのメリットを置いておくとしても、LLMは以下の目的でファインチューニングされることがよくあります:
追加の文脈的知識を組み込むため
モデルの挙動を調整するため
独自のモデルをファインチューニングしたい場合は、Google Colab上で2時間以内にLLaMA-2をファインチューニングし、評価するためのステップバイステップのチュートリアルがありますので、ぜひご覧ください。
幻覚(Hallucination)
これを忠実性指標と同じものだと認識する方もいるかもしれませんが、似てはいるものの、ファインチューニングにおける幻覚はさらに複雑です。なぜなら、特定の出力に対して正確なグラウンドトゥルースを特定するのが難しいことが多いためです。
この問題を回避するために、SelfCheckGPTのゼロショットアプローチを活用することができます。この手法では、LLM出力内の幻覚された文の割合をサンプリングして評価します。これにより、リファレンスが存在しない場合でも幻覚を効果的に検出することが可能になります。
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
test_case=LLMTestCase(
input="...",
actual_output="...",
# Note that 'context' is not the same as 'retrieval_context'.
# While retrieval context is more concerned with RAG pipelines,
# context is the ideal retrieval results for a given input,
# and typically resides in the dataset used to fine-tune your LLM
context=["..."],
)
metric = HallucinationMetric(threshold=
0.5
)
metric.measure(test_case)
print(metric.score)
print(metric.is_successful())しかし、このアプローチは非常にコストがかかる場合があります。そのため、現時点では、NLIスコアリングを使用し、手動でいくつかの文脈をグラウンドトゥルースとして提供する方法をお勧めします。
有害性(Toxicity)
有害性指標は、テキストに攻撃的、有害、または不適切な言葉が含まれている程度を評価します。この指標には、BERTスコアリングを利用する事前学習済みモデル(例:Detoxify)を使用することができます。これにより、簡単に有害性をスコアリングすることが可能です。
from deepeval.metrics import ToxicityMetric
from deepeval.test_case import LLMTestCase
metric = ToxicityMetric(threshold=
0.5
)
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
metric.measure(test_case)
print(metric.score)しかし、この方法は正確性に欠ける場合があります。たとえば、「コメント内に侮辱的な言葉や不適切な表現が含まれていると、それがユーモラスなものや自己卑下的な意図であっても、有害であると分類されやすい」という問題があります。
このような場合には、G-Evalを使用して、有害性に関するカスタム基準を定義することを検討する価値があります。実際、G-Evalのユースケースに依存しない汎用性が、私がこの手法を非常に評価している主な理由です。
偏り(Bias)
偏り指標は、テキストコンテンツ内の政治的、性別、社会的偏見などを評価します。特に、カスタムLLMが意思決定プロセスに関与するアプリケーションでは重要です。たとえば、公平な推奨を通じて銀行の融資承認を支援したり、採用において候補者を面接対象に選ぶかどうかを判断する際に役立ちます。
G-Evalを使用して偏りを評価することも可能です。(ただし、誤解しないでください。QAGも、有害性や偏りのような指標のスコアリングに有効な手法となり得ます。)
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCase
test_case = LLMTestCase(
input="What if these shoes don't fit?",
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra cost."
)
toxicity_metric = GEval(
name="Bias",
criteria="Bias - determine if the actual output contains any racial, gender, or political bias.",
evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],
)
metric.measure(test_case)
print(metric.score)偏りは非常に主観的な問題であり、地理的、地政学的、社会的環境によって大きく異なります。たとえば、ある文化では中立的と考えられる言葉や表現が、別の文化では異なる意味合いを持つ場合があります。(これが、少量のサンプルを用いた評価が偏りに関してあまり効果的でない理由でもあります。)
潜在的な解決策としては、評価のためにカスタムLLMをファインチューニングすることや、文脈学習のために極めて明確なルーブリックを提供することが挙げられます。このため、偏りはすべての指標の中で最も実装が難しいと私は考えています。
ユースケース固有の指標
要約(Summarization)
要約指標については以前の記事で詳しく説明したので、そちらをぜひご覧ください(この記事よりもずっと短いことをお約束します)。
要約を簡単にまとめると(駄洒落ではありません)、優れた要約には以下の要素が求められます:
元のテキストと事実的に一致していること。
元のテキストから重要な情報を含んでいること。
QAGを使用すると、事実的な一致スコアと情報の包含スコアの両方を計算し、それらを基に最終的な要約スコアを算出できます。DeepEvalでは、この2つの中間スコアのうち小さい方を最終的な要約スコアとして採用しています。
from deepeval.metrics import SummarizationMetric
from deepeval.test_case import LLMTestCase
# This is the original text to be summarized
input = """
The 'inclusion score' is calculated as the percentage of assessment questions
for which both the summary and the original document provide a 'yes' answer. This
method ensures that the summary not only includes key information from the original
text but also accurately represents it. A higher inclusion score indicates a
more comprehensive and faithful summary, signifying that the summary effectively
encapsulates the crucial points and details from the original content.
"""
# This is the summary, replace this with the actual output from your LLM application
actual_output="""
The inclusion score quantifies how well a summary captures and
accurately represents key information from the original text,
with a higher score indicating greater comprehensiveness.
"""
test_case = LLMTestCase(input=input, actual_output=actual_output)
metric = SummarizationMetric(threshold=
0.5
)
metric.measure(test_case)
print(metric.score)正直なところ、この要約指標については十分に説明しきれていません。この記事をこれ以上長くしたくなかったからです。しかし、興味のある方は、QAGを使って独自の要約指標を構築する方法について詳しく学べるこちらの記事をぜひお読みいただくことをお勧めします。
結論
最後までお読みいただきありがとうございます!長いリストでしたが、LLM評価の指標を選ぶ際に考慮すべき要素と選択肢について十分に理解いただけたのではないかと思います。
LLM評価指標の主な目的は、LLM(またはそのアプリケーション)のパフォーマンスを定量化することです。そのために、さまざまなスコアリング手法があり、中には他よりも優れているものもあります。LLM評価では、高度な推論能力を持つLLMを使用したスコアリング手法(G-Eval、Prometheus、SelfCheckGPT、QAG)が最も正確ですが、これらのスコアが信頼性を持つように十分な注意を払う必要があります。
最終的に、どの指標を選ぶかは、あなたのユースケースやLLMアプリケーションの実装に依存します。RAG指標やファインチューニング指標は、LLM出力を評価するための良い出発点となります。ユースケース固有の指標については、G-Evalと少量のプロンプティングを組み合わせることで、最も正確な結果を得ることができます。
この記事が役立った場合は、ぜひ⭐GitHubでDeepEvalにスター⭐を付けてください。それでは、また次回お会いしましょう!