画像の代替テキスト(の初案)をAIで自動生成する

この記事は以下のアドベントカレンダーの12月17日の記事です。
Adventar アクセシビリティ Advent Calendar 2023(https://adventar.org/calendars/8584)
ディーゼロというウェブ制作会社で、アクセシビリティを担当しているこいでです。アクセシビリティを専門としたポジションで業務にあたっています。
今回の記事は、アクセシビリティの入り口であり、だれでも作成することがあるが奥深くて悩ましい、代替テキストの作業についてです。
ウェブサイトの原稿担当・作成者が代替テキストを作成するのが望ましいとはいえ、制作するウェブサイトの代替テキストを、制作会社側が担当することはよくあります。
大量の画像の代替テキストを効率的に作成する方法について、現在、だれでも手が伸ばしやすい手段でどの程度できるかを見てみました。
今回は、代替テキストの初案を作成するところまでを書いています。初稿ではないのは、まだまだ手をいれなくてはならないレベルのためです。しかし、最初から文章を自力で起こさなくて済むだけでもかなり楽になる、はず、です。
前提
まず一番重視する要素として、開発者ではない私でも出来る方法を選ぶことにしました。
次に、代替テキストを作成するにあたっては、「内容が適切か、装飾か装飾でないか」など、前後の文脈(コンテキスト)を含めた確認が必要ですが、今回はそこまで踏み込みません。
一律に画像の内容をテキスト化するのが今回のスコープです。
また、あくまでもオープンな環境で出来ることに絞っています。
公開前の情報を扱う前提ではありませんので、くれぐれもご注意ください。
使うもの
CoCa (Contrastive Captioners are Image-Text Foundation Models)
マシンは私物のノートPCを使いました。スペックは高くはないが低すぎでもなくといったところかと。
Windows 11 Home (64bit)
CPU Intel(R) Core i5-1035G7
RAM 8.00 GB
やりたいこと
ウェブサイトにある大量の画像の代替テキストの初案を作成します。
なぜ「初案」かというと、前提に書いたように、代替テキストは画像の情報だけでは完結しないためです。
AIで、画像の情報の基本的なところを出力させ、人間がブラッシュアップする想定です。
まずテストしてみる
まずは手元で試してみようと、以下のサイトを参考にGoogle Colabで試してみることにしました。
画像ファイルは当社サイトのものを利用します。
アクセシビリティカンファレンス福岡2023へ参加!
#よかったらblog記事も読んでみてください
実行は2分ほど、最後に少しだけエラーを吐いているものの、以下の文章(英語)が出力されました。
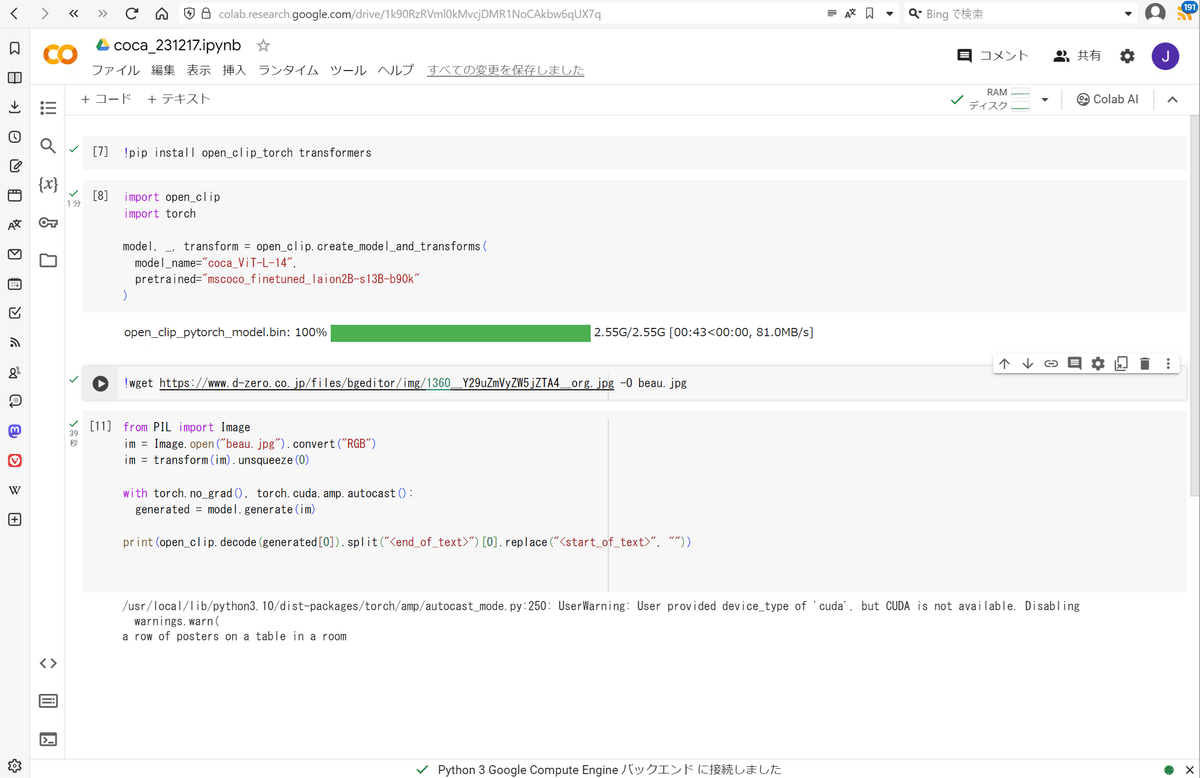
英語:a row of posters on a table in a room
日本語:部屋のテーブルの上のポスターの列
複数画像の代替テキストを一括で出力できるようにする
「AIを使って~」のサンプルコードでは、1画像ごとに結果を出力するようになっていました。複数画像を一括で出力できるように、Colab AIに質問することにしました。
ざっくりとした手順イメージはこんな感じです。
ウェブサイトの画像ファイルを抽出し、CSV形式でリスト化する
CSVのリストに基づいて画像を読み込む
CoCaで画像の情報を代替テキストとして出力する
CSVに代替テキストを書き込む
今回はテストなので画像ファイル抽出はせず、こちらでcsvに画像ファイルを三つ用意しました。
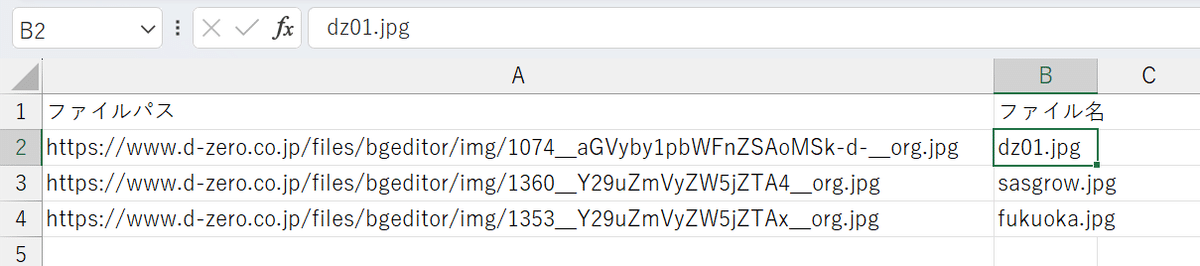
このリストに基づいて、複数の画像ファイルの代替テキストを続けて作成するコードを、Colab AIに作ってもらいました。
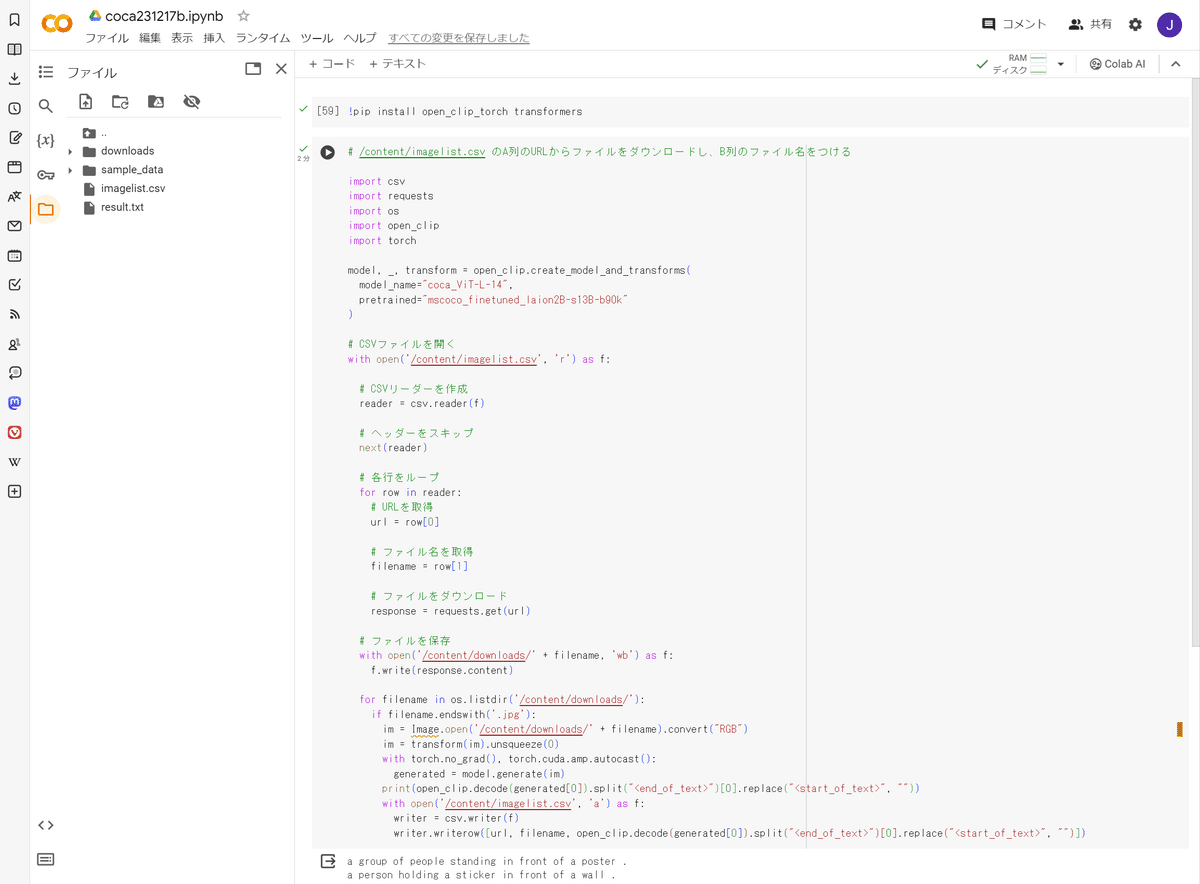
代替テキストを追記したCSVファイルを開いてみました。

CSVに書き込むときの行がずれてしまっていたり、おかしいところがありますね。ここは次回改善することにしましょう。
BLIP2で出力されるテキスト
CoCaもBLIP2 (Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models) も事前のトレーニングなし(ゼロショット)でキャプションを生成できるモデルです。
もともと、ローカル環境でBLIP2を試してみたかったので、同じ画像についてどのくらいキャプションの差が出るのかをついでに見てみました。
モデルの性能の差自体は、以下のページが詳しいです。
なお、PyTorch 2.1.xは Python 3.12ではまだ使えないため、3.11をインストールしました。インストールしてから最新版NGなのに気づいた悔しみ…。
比較

CoCa:a group of people standing in front of a poster .
BLIP2:a group of people in front of a banner that says kazen project

CoCa:a person holding a sticker in front of a wall
BLIP2:a person holding up a sticker with an image of a robot on it

CoCa:a row of posters on a table in a room
BLIP2:several posters are displayed on a table in a room
結び
既に、以下のように日本語でのキャプション生成がどんどん進んでいる中ではありますが、ゆっくりではあっても確認したことをまとめたく記事にしました。
サイトの画像情報の精度アップと、不足そのものがなくなることを期待しつつ。
おまけ
組織図のように、画像内に大量のテキストがあるのに原稿がない!という場合、Google Keepでの文字認識が役に立ちそうです。精度がかなりよくなっていました。
こちらも公開可能な画像でのみお試しください。
ほか参考
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?