Excelを使ってメールアドレスにフリガナをつける

興味深い書式と作業
Excel関連で検索をしていたら、このようなXのポストを見かけました。
自身もExcelのvlookup関数で登記申請書用のフリガナ変換を作成しました。
— kokko (@kokko_) January 12, 2025
あと法務省の例ですが,せめてルール上,例とするドメインは「https://t.co/i5OdqNFXTh」等を使うことになっているので,https://t.co/luCYNFXHWaなにがしはないとはいえ,やめたほうがいいと思います。 https://t.co/0P7NS3pmF5 pic.twitter.com/gVeaJQyJc9
自身もExcelのvlookup関数で登記申請書用のフリガナ変換を作成しました。
内容は、メールアドレスのフリガナをふるExcel数式を作ったというものですが、私は大変おどろきました。何にって?
世の中にはかくも無駄な作業があるのか
という事にです。私は、登記申請などの書式には疎いので、このようなものがあるとは知りもしませんでした。まさか、メールアドレスを構成する全ての文字についてフリガナを記載し、それを中黒で繋げる作業があるなど、想像もつかなかったのです。
不動産の登記申請時、メールアドレスとその読み方が必須に。
— 玉川和(すずな司法書士行政書士事務所) (@Kadono_W) January 11, 2025
読み方については、0(ゼロ)とO(オー)など、見分けのつきづらい文字の判別のためと解釈します。
私のような悪筆な人間もいますので笑
しかしそうであるならば、オンライン申請においては、省略可能とすべきでしょう。 pic.twitter.com/Me5mwaqWzV
↑こういった説明もあります。Xを「登記 フリガナ」などで検索すると、色々の意見が参照できます。
文字の判別の事情という見かたをするなら、アドレスを書く文字の形状に規定を設けたほうが良いのではないかとか、フリガナでも手書きだと判別できない場合が出るだろうとか(エスとエヌなど)、色々の観点が出てきそうですが、ひとまず措いておきます。
※プロダクトキーやシリアルナンバーなどは、オーとゼロなど誤りやすい文字を混在させない規則に従う場合があります
とは言え、役所関連の書類には、なぜこのような書式になっているのか、と思わされるものがしばしば存在し、それは業務上どうしても作成しなくてはならない場合もあります。という事で私も、この要件、つまり、
あるメールアドレスについて、全ての文字にフリガナをふって、それを決められた記号で連結して記載する
のを実現するExcelの数式を作ってみます。
文字列にフリガナをふる数式の作成
フリガナ対応規則の定義
本記事では、Excelの基本的な関数やテーブル化、構造化参照の把握を前提します。
まず、フリガナと記号を対応づける表を作ります。アドレスの各文字をフリガナで表現しようというのですから、これが無くては成り立ちません。
なお、使用する表は全てテーブル化します。

furiganaテーブルとしました。メールアドレスには、アルファベットと数字、ハイフンやアンダースコアなどが使用できるので、左の列にそれらの文字を入れ、フリガナ列には読みかたをカタカナで入れます。
※当該書類の正式な規則が不明なので、フリガナはそれらしいものを入れてあります。
メールアドレスの文字列分割
次に、メールアドレスを入れる表を作ります。ここに入れられたアドレスをフリガナに変換します。
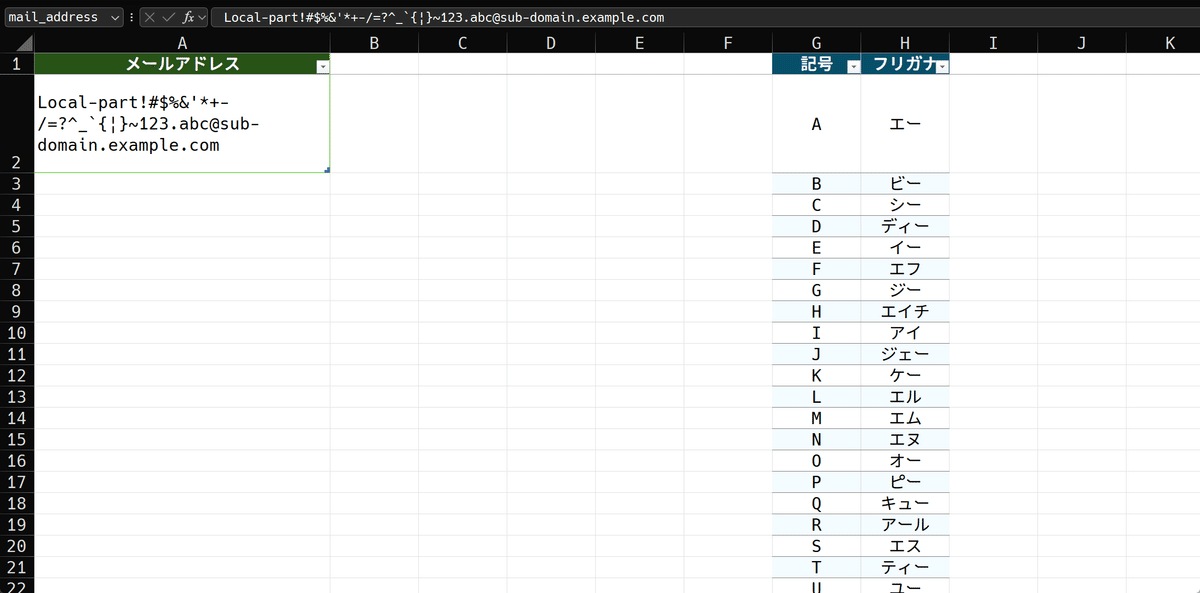
左にテーブルを作り、mail_addressとしました。ダミーとして、入力可能な様々の記号を適当に入れてあります。
ここまでで、判定する元であるメールアドレスと、それをフリガナに変換させるためのテーブルを用意しました。今おこないたい処理は次のようです。
メールアドレスの記号を1文字ずつ
フリガナの対応表を照合して取得し
それを決められた記号で連結する
上記の処理をおこなうにはまず、メールアドレスを1文字ずつ分解する必要があります。文字列操作にはいくつかの関数がありますが、今は、
ある文字列内での好きな場所の文字を取り出す
これが必要なので、MID関数を使います。MID関数に渡す引数は、
対象とする文字列
取り出す最初の文字の場所の数値
取り出す文字数
このようですので、
対象とする文字列<-メールアドレス
取り出す最初の文字の場所の数値<-左から順に1, 2, 3…メールアドレス文字数までのどれか
取り出す文字数<-1
こう投入します。メールアドレスに使える文字数は200字以上だそうですが、いま対象としている作業において、実用上は50文字程度あれば充分ですので、それを前提に作ります。もちろん、大きめに何百文字分でも作っておいて支障はありません。

真ん中に、3列からなるテーブルを作りました。メールアドレスを1文字ずつ取得してフリガナに対応付ける処理をおこなうテーブルなので、メールアドレス記号列を解析(parse)するという意味で、mail_address_perserとしてあります。
各列は次のようです。
文字番号 列:メールアドレスの何文字目か
文字 列:文字番号に対応する、メールアドレス内の記号1文字
フリガナ 列:各文字に対応するフリガナ
文字番号の列にはシンプルに、1から始まる自然数の列を順に入れます。
これで準備が出来たので、数式を作っていきましょう。
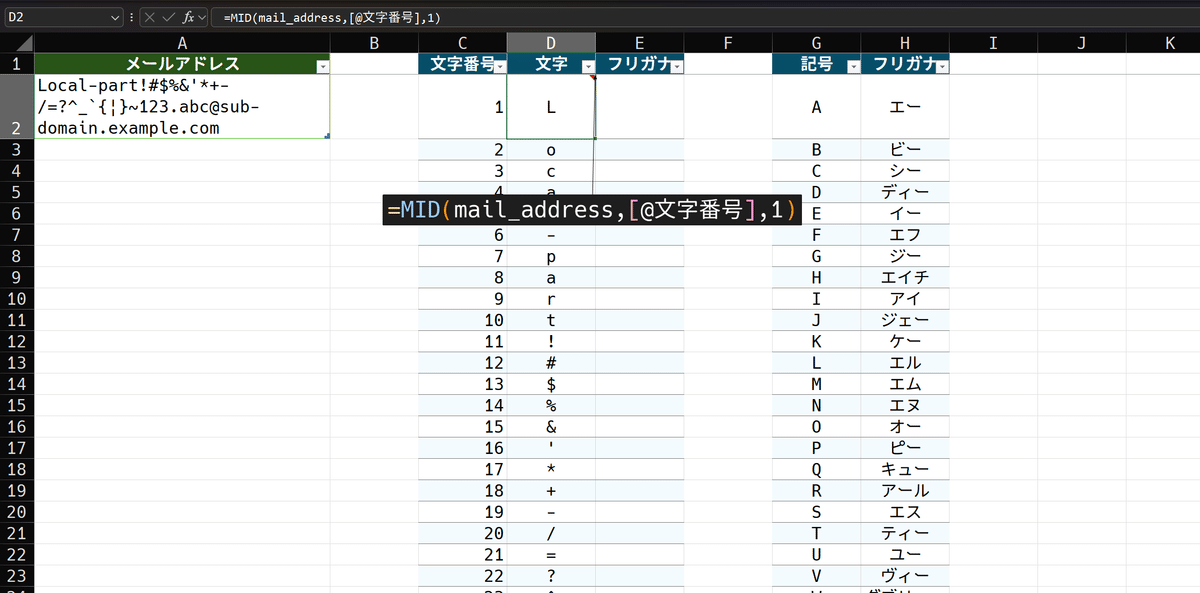
2列目、文字を1文字ずつ取得する列に、次の数式を入れます。
=MID(mail_address,[@文字番号],1)MID関数の構造を再掲すると、
対象とする文字列<-メールアドレス
取り出す最初の文字の場所の数値<-左から順に1, 2, 3…メールアドレス文字数までのどれか
取り出す文字数<-1
こうですので、第1引数には、メールアドレスが入っているmail_addressテーブルを構造化参照します。1行1列のテーブルなのでテーブル名のみで指定できます。
※テーブル構成を変更する際には数式にも変更が必要です
次は、何文字目かを指定する数値ですが、最初に文字番号列で記入したので、同テーブルの[@文字番号]で同行を参照させます。そうすると、各文字が取得されます。
対応フリガナの検索と取得
次に、取得した文字を表現するフリガナを取得します。これはfuriganaテーブルで定義していますから、それを参照しましょう。うってつけなのは、XLOOKUP関数です。Excelのバージョンが古い場合は、VLOOKUP関数でも良いでしょう。
=XLOOKUP(
[@文字],
furigana[記号],
furigana[フリガナ],
[@文字] & "->未登録"
) & ""XLOOKUP関数の材料は、
検索する対象<-同じ行にある1文字
検索に行く範囲(幅1)<-furiganaテーブルの記号列データ部
返すものが入っている範囲(検索範囲と同じ長さ)<-furiganaテーブルのフリガナ列データ部
見つからない場合に返すもの<-文字が未登録である旨のメッセージ
こうです。

うまく取得できました。
ここでポイントなのは、
第4引数の、見つからない未登録文字の扱い
数式の最後に空白をつける
これらです。シンプルにする場合、XLOOKUPの第4引数を空白("")にすれば数式は短くなります。しかし、もし未登録のものが複数あり、メールアドレスが長い場合、すぐ見つけにくくなります。ですから、見つからない場合はその旨のエラーメッセージを返して、ユーザーに解りやすくするという寸法です。試しに、アドレスに使われている文字の登録を解除して、結果を見てみましょう。

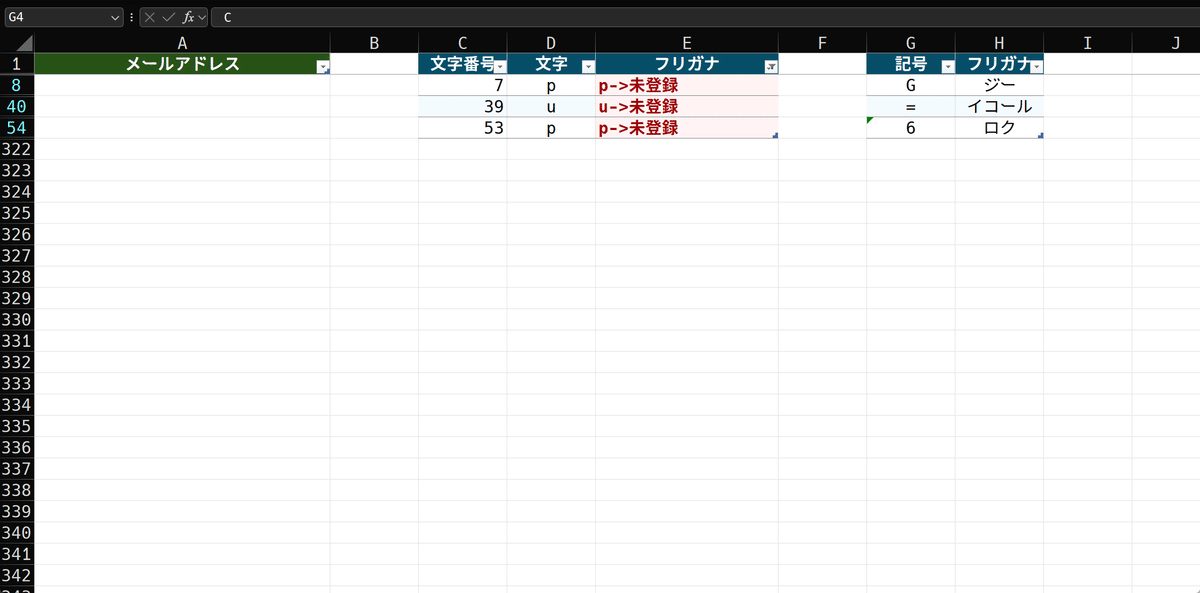
このように、どの文字が登録されていないかすぐ判ります。これから作る連結の結果を先にお見せすると、

このように、どこの何が未登録になっているかがよく判ります。
検索の数式は、
=XLOOKUP(
[@文字],
furigana[記号],
furigana[フリガナ],
[@文字] & "->未登録"
) & ""最後に空白をつけています。これは、フリガナ対応づけテーブルに、空白行を入れているためです。真ん中の文字列解析テーブルは、メールアドレス文字数より多くの行を取ってありますので、隣の文字が空なら、そのままならエラーが返りますが、いまはエラー処理として未登録情報を表示させています。しかし、空白はエラーと別の処理をさせたいので、右のfuriganaテーブルに、敢えて空白行を設けて、
XLOOKUPに空白を見つけさせる
わけです。

ルックアップ系関数は、空白を見つけるとゼロを返すので、それを空白にするため、最後に空白をつけます。よくあるテクニックですね。
補足ですが、検索系の数式で注意するのは、
大文字と小文字の区別
数値の検索
これらです。XLOOKUP関数では、アルファベットの大文字小文字を区別せずに検索するのでシンプルに書いていますが、区別する関数の場合には、あらかじめ、UPPER関数やLOWER関数でどちらかに揃えておいて検索させる、という処理が必要です。
また、数値と文字列を区別して検索するものがあるので、その場合には、ちゃんと数値を文字列として入力しないと、検索でヒットしません。慣れていても、けっこう頻繁に起こります。
取得した文字の連結
いよいよ文字の連結です。
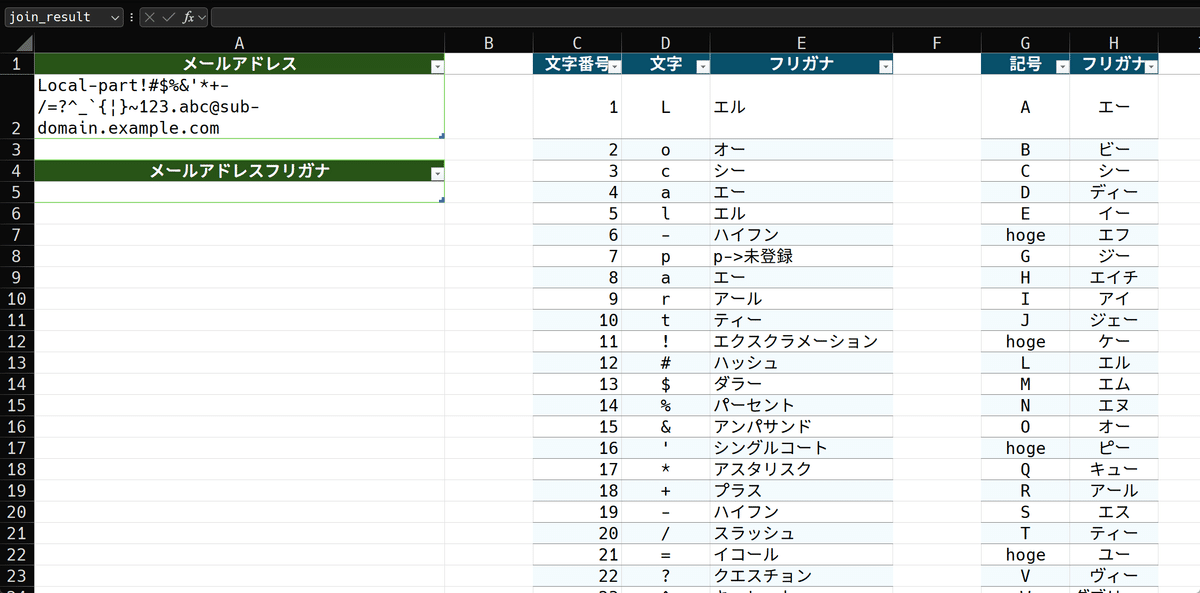
メールアドレステーブルの下に、結合結果の意味でjoin_resultテーブルを作成しました。ここに、文字列結合の数式を入れます。
シンプルにやると、
=TEXTJOIN("・",TRUE,mail_address_perser[フリガナ])こうなるでしょう。TEXTJOIN関数は、
区切り文字<-「・」
空白を無視するかどうか<-True(無視する)
結合する対象<-真ん中のmail_address_perserテーブル、フリガナ列データ部
このように引数を渡します。結果は
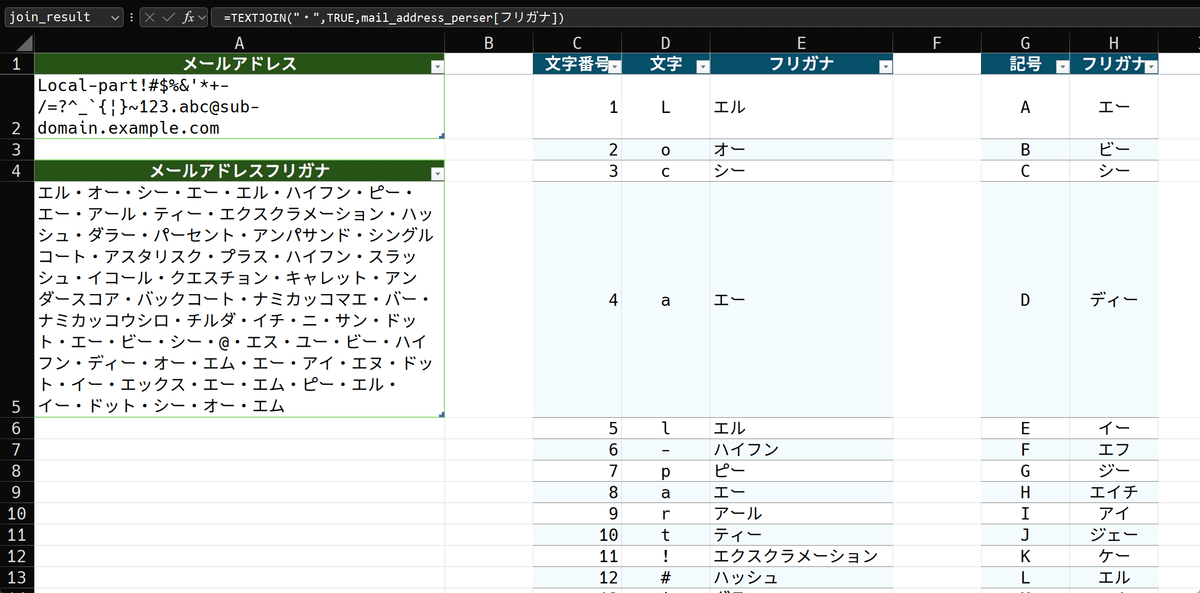
こうなりました。一見うまくいっているようですが、最初に引用したXのポストをよく見返すと、
自身もExcelのvlookup関数で登記申請書用のフリガナ変換を作成しました。
— kokko (@kokko_) January 12, 2025
あと法務省の例ですが,せめてルール上,例とするドメインは「https://t.co/i5OdqNFXTh」等を使うことになっているので,https://t.co/luCYNFXHWaなにがしはないとはいえ,やめたほうがいいと思います。 https://t.co/0P7NS3pmF5 pic.twitter.com/gVeaJQyJc9
ローカルパートとドメインを区切るアットマークの前後には、中黒がありません。ここだけ、それ自体を区切り文字とする規則のようです。統一して「・アット・」で良かろうとも思いますが、規則に合わせましょう。また、区切り文字が中黒ですが、こういうのは、いつ変更されるか判りませんので、別にテーブルで管理するのも手です。
区切り文字と特殊な文字の処理
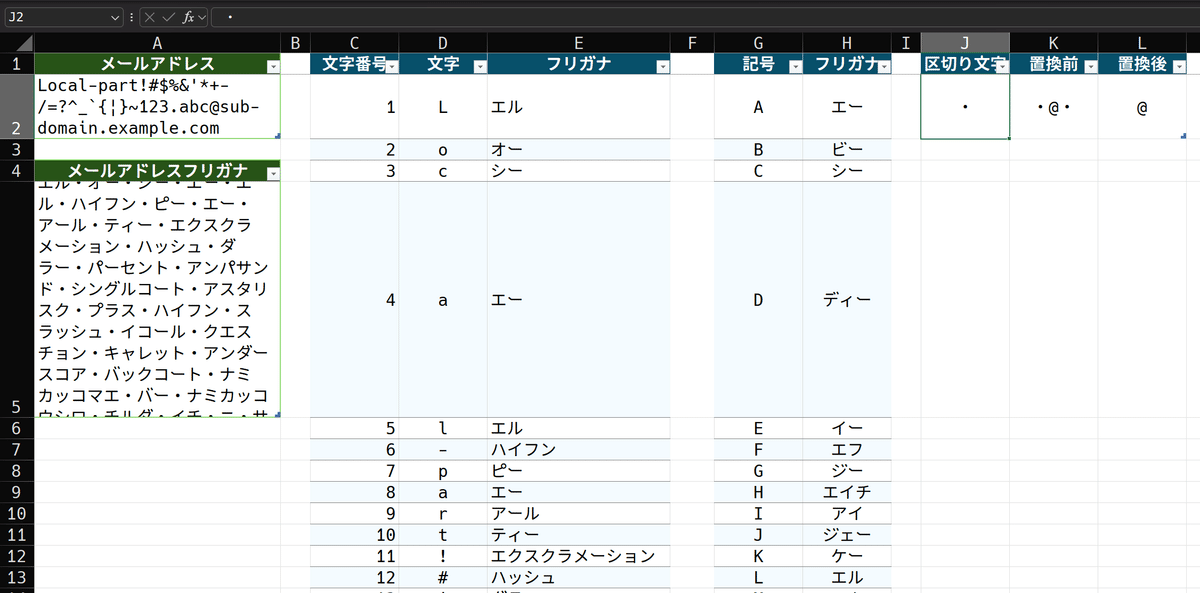
delimiterテーブルです。delimiterは区切り文字の事です。このテーブルは、
区切り文字 列:区切り文字
置換前 列:区切り文字で囲んだアットマーク
置換後 列:アットマーク
このようになっています。左の列は言うまでも無く、区切り文字そのものである中黒を入れてあります。
TEXTJOINでシンプルに結合すると、アットマークは中黒に囲まれた「・@・」となります。規則によれば、アットマークだけはそれ自体が区切り文字になるので、これをアットマーク1文字に変換しようというわけです。後は、これを踏まえて数式を構成しましょう。
=SUBSTITUTE(
TEXTJOIN(delimiter[区切り文字],TRUE,mail_address_perser[フリガナ]),
delimiter[置換前],
delimiter[置換後]
)SUBSTITUTE関数は、
ある文字列から
特定の文字列を探し
それを別の文字列に置換する
という関数です。SUBSTITUTEは、取り替える、代わりにという意味なので、置換するそのままの意です。
今やりたいのは、
結合した文字列の中には中黒で囲まれたアットマークがあるが、それは規則に反するのでアットマークに変更する
という事なので、SUBSTITUTE関数には、
ある文字列から<-中黒で結合したフリガナ
特定の文字列を探し<-中黒で囲まれたアットマーク
それを別の文字列に置換する<-アットマーク
このように投入します。1番目はもちろん、TEXTJOINの結果を渡し、2番目と3番目に入れる材料は、先ほどdelimiterテーブルなる別テーブルに準備しておきました。数式を再掲します。
=SUBSTITUTE(
TEXTJOIN(delimiter[区切り文字],TRUE,mail_address_perser[フリガナ]),
delimiter[置換前],
delimiter[置換後]
)結果は下図の通りです。
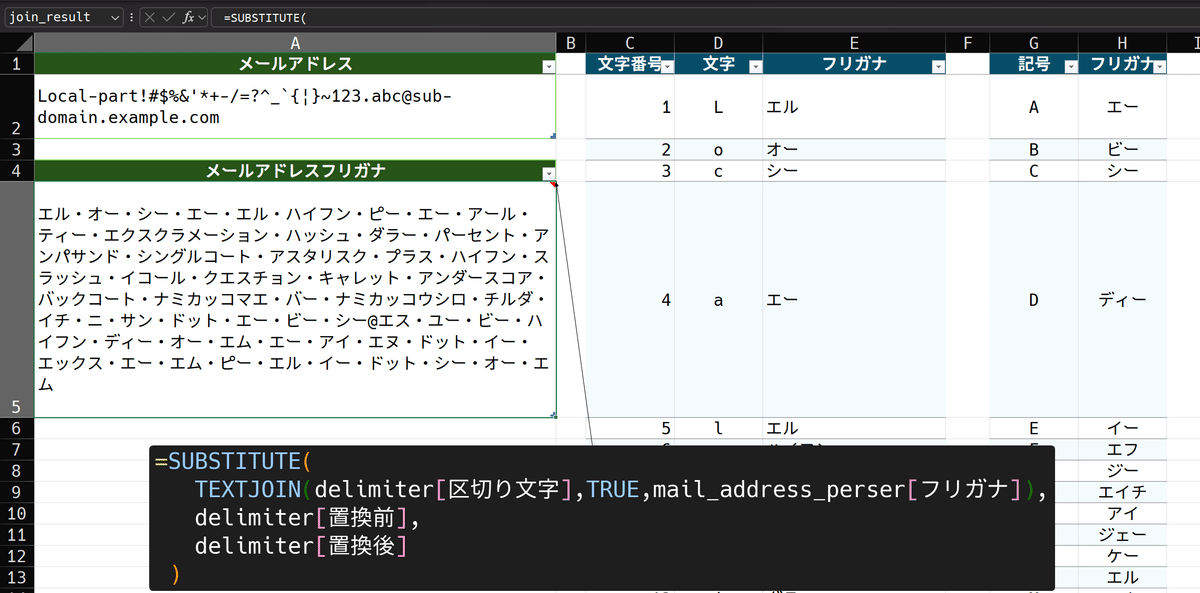
アットマークの置換も上手くいきましたね。区切り文字は別テーブルで定義したので、それを変更すれば、数式に手をいれる事なく、結合文字列の結果を変えられます。
なんかちょっと怖いな
これでひとまず、一通りの処理は完了しました。お疲れ様です。
複数のメールアドレスへの対応
さて、最初に引用したポストでは、複数のメールアドレスの変換に対応しています。こういった作業で、同時に複数の結合フリガナを表記させておく必要はそれほど無い気もします。もし対応するなら、ポストの画像にあるように、作業列を横に伸ばしていって、この記事で示したような処理を複数ぶん書く必要があります。数式自体は大して難しく無いですが、列が多くなって横に広がると、テーブルの管理が煩雑になりますし、どうしても数式をまとめると、長くなり可読性も悪くなります。ですので、その煩わしさを回避しつつ、実務に耐えられるような構成を模索しましょう。
処理テーブルの分離
まず、左端にあるテーブル以外のテーブルを、別のシートに移動させましょう。これらは直接、作業上で参照する表では無く、変換と結合作業用に作成したものなので、別シートに置いても問題ありません。また、テーブルであり構造化参照で数式を構成してあるので、どこに移動させても数式が壊れません。これは構造化参照の強みです。
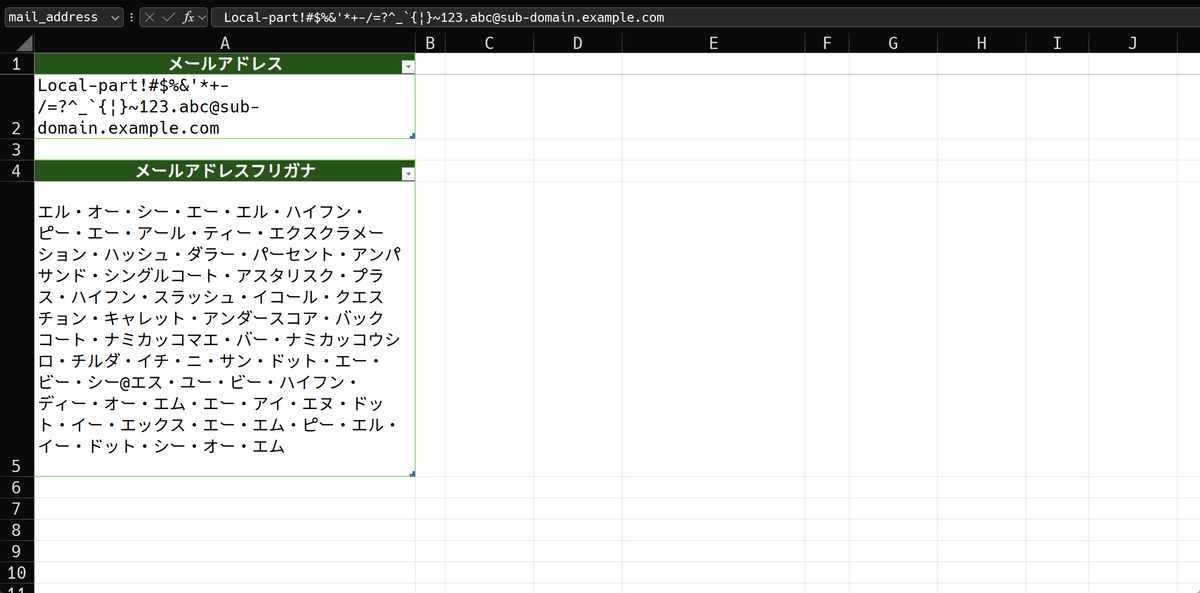
複数メールアドレスに対応させるので、それを記載・管理する表が必要です。それを追加し、レイアウトを変更します。

メールアドレス単体のテーブルと、フリガナ結合テーブルを上にして、下に、メールアドレス複数からなるテーブルを作りました。メールアドレスの集まりという意味で、mail_address_setテーブルにしてあります。
リスト入力規則の設定
こうしておいて、上のメールアドレス単体セルに、入力規則を設定します。リストでINDIRECT関数を使い
=INDIRECT("mail_address_set[メールアドレス]")こう設定します。こうする事で、下にあるメールアドレスリストからアドレスを選択できるようになります。
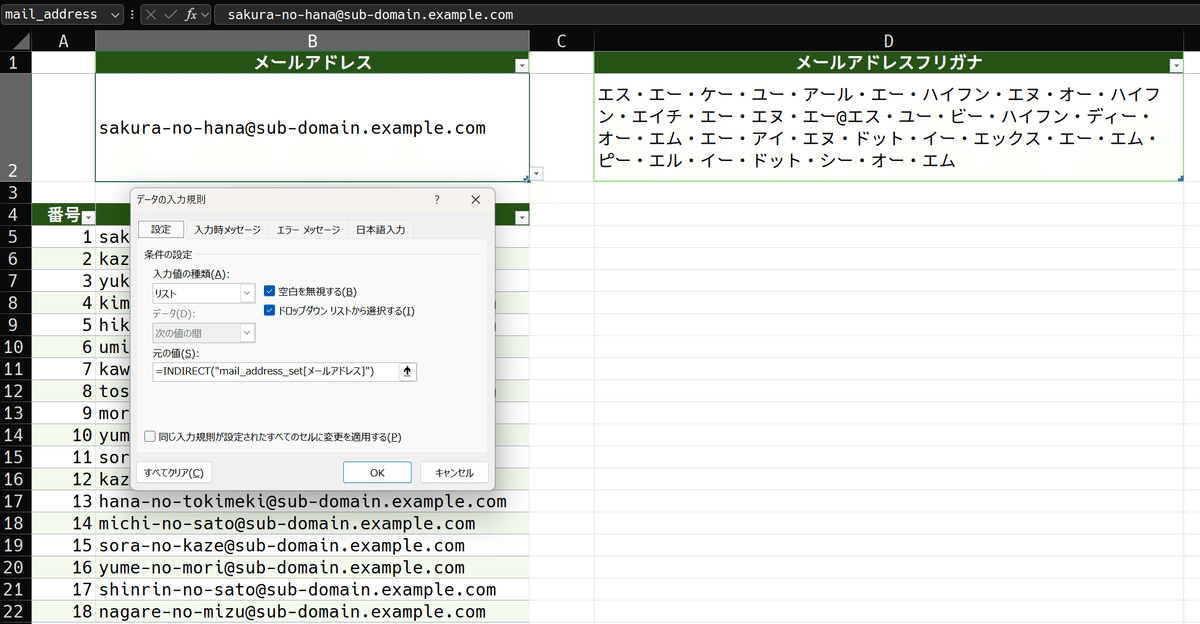
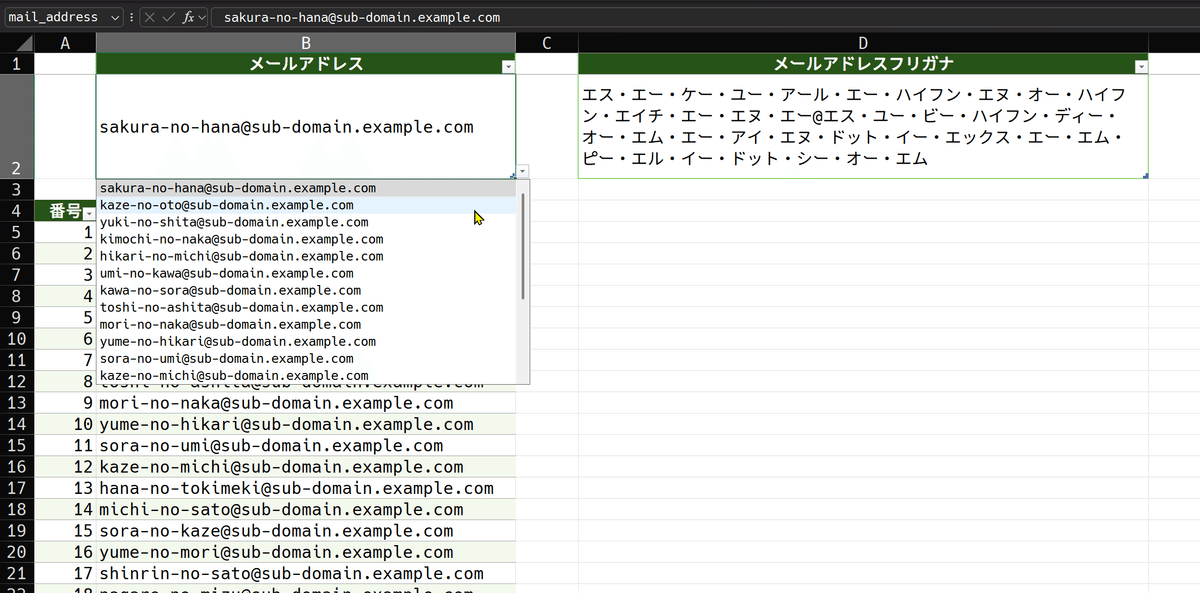
こうすれば、メールアドレスを複数ぶん管理しつつ、数式は最小の構成で済みます。必要に応じて所望のメールアドレスを選択すれば、それのフリガナ結合が表示されます。

複数のメールアドレスを管理してフリガナで表現する、というツールの基本的な構成は、これで完成しました。後は、他の要件に合わせて色々の工夫をおこない、ブラッシュアップしていけば良いでしょう。実務においては、可読性や保守性を良くする実装が重要となりますので、作業テーブルや作業列を駆使して、読みやすい数式の構成を心がけたい所です。