区分ごとの最大値でのフィルター――MAXIFS関数とFILTER関数

はじめに
Xで見かけたポスト
私はしばしば、勉強のために、Xのリアルタイム検索でExcel関連の検索をしています。その流れで、次のポストを見かけました。
区分ごとに改定番号が最新の行だけを表示したい。FILTER関数でやろうと思ったがうまくいかず。もっとシンプルにできそうな気がするのですが。。#Excel pic.twitter.com/kG81RRbaVQ
— shu (@shusoshin) August 6, 2024
区分ごとに改定番号が最新の行だけを表示したい。FILTER関数でやろうと思ったがうまくいかず。もっとシンプルにできそうな気がするのですが。。
要件
まず、日付・区分・改定の列からなる表があり、それについて、区分ごとで改定番号が一番大きい行のみを表示させる、という要件です。上記ポストでは、CHOOSEROWS関数やUNIQUE関数など、色々の関数を駆使して数式を構成しています。
今回は、この要件を実現した数式を作ってみましょう。
区分ごとの最大値でフィルターする数式――よりシンプルな式
表の用意
まず、比較的シンプルに書ける数式を考えます。そのためには、表の構成に関する条件を多くします。
表を用意しましょう。
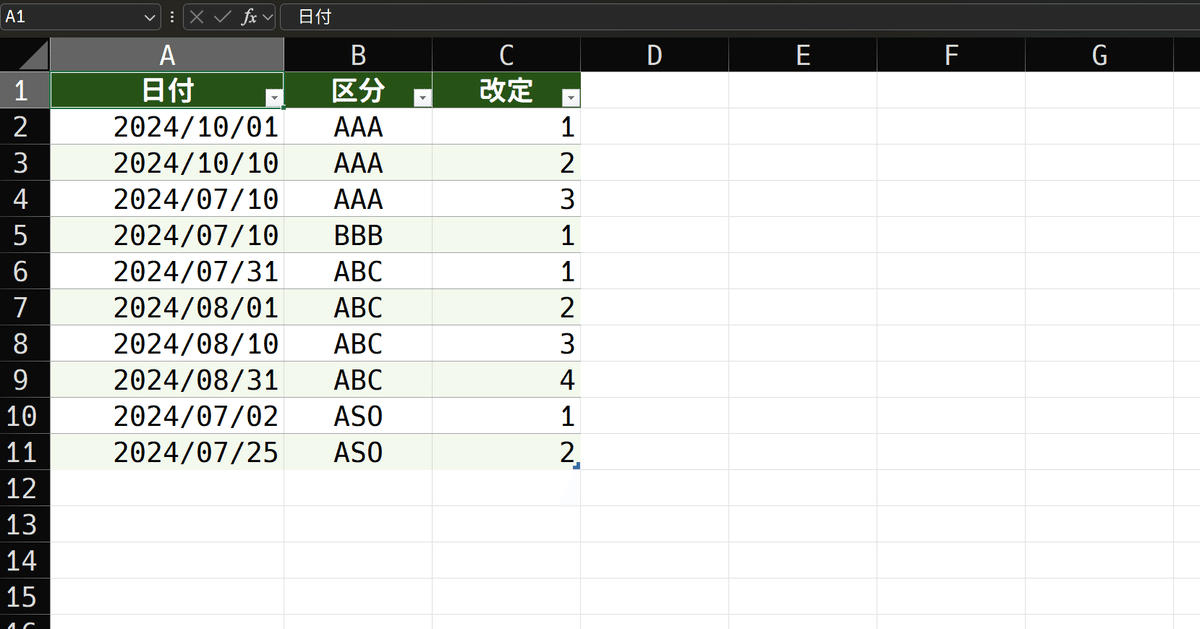
テーブル名はrevision_tableとしました。桁を揃えるため、日付はyyyy/mm/ddで表示してあります。
余談ですが、こういう、不規則な並びになっているデータを画像に基づいて入力する場合には、Snipping Toolによる文字認識が極めて便利なので、積極的に使いましょう。

先ほど、シンプルな数式にするには、条件を多くすると書きました。複数の条件が満たされていれば、規則的に表が並んでいる事が保証され、表を絞り込む条件がシンプルに出来るからです。
前提条件は次のようにしましょう。
前提条件
行は区分ごとにまとまっていて
改定番号は昇順(小さい順)に並んでいる
多いと言ってもこれだけです。先ほど作った表はこれが満たされています。この場合、目標である絞り込み要件、
各区分で
最大の改定番号を持つ行
のみを表示するにはどうすれば良いでしょうか。
改定番号の規則
最終的な絞り込みは、FILTER関数に任せましょう。
前提条件によれば、行は区分ごとにまとまっています。
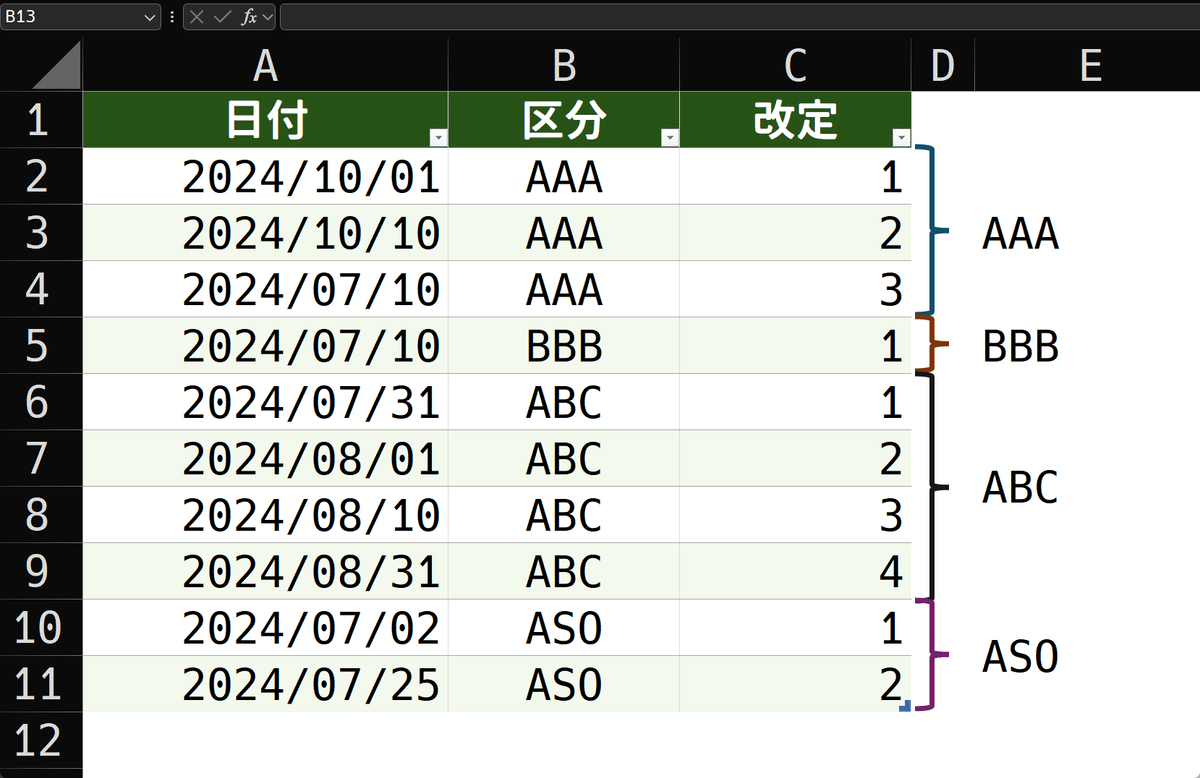
その塊の中で、改定番号は小さい順に並んでいます。という事は、次が言えます。
区分が変わった最初の行の改定番号は、必ず1である
区分がまとまっていて改定番号が昇順に並んでいる、との行儀の良い表なので、次の区分に行が切り替わったら、改定番号は最も小さい数である1から始まるので、値は1が入ります。ですから、ここを判定して、FILTER関数の可視条件にすれば良いわけです。
可視条件の構成
まずは作業列を作ります。

ここで、要件を満たした行について、0以外の数値かTRUEが入り、それ以外は0かFALSEが入るようにすれば良いです。
先ほど書いたように、区分が切り替わると改定番号は1になります。これは見かたを変えれば、
下の行の改定番号が1であれば、いま見ている行の改定番号は区分での最大である
と言えます。

数式のロジックを書きましょう。
もし同じ行にある
改定番号の
1つ下が
1であれば
可視とする
こうです。後は、これを数式にします。

=IF(OFFSET([@改定],1,0)<=1,TRUE,FALSE)これが数式です。@は構造化参照で同じ行を示します。OFFSET関数は、第2引数で行のずらし、第3引数で列のずらしなので、真下のセルを返すために、それぞれを1と0とします。そして、真下の改定番号が1であれば可視条件をTRUEとし、1以外ならFALSEにします。ただし、表の最終行では、真下が1になるとは限りませんので、空白が入ると仮定します。真下が空白であれば、最後の区分における最大改定値なので、可視となります(空白は0と判定される)。
ロジックと数式を対応させれば、
もし同じ行にある←IFと@
改定番号の←[@改定]
1つ下が←OFFSET
1以下であれば←<=1
可視とする←TRUE
このようです。後は、FILTER関数に可視条件範囲を参照させれば出来上がります。
フィルターの数式

数式は
=FILTER(revision_table[[日付]:[改定]],revision_table[可視条件])こうです。
作業列を使わない場合
もし、作業列を使わず、FILTER関数の中で直接に可視条件を構成したいなら、ひと工夫入れます。
作業列に入れた数式、
=IF(OFFSET([@改定],1,0)<=1,TRUE,FALSE)これは、同じ行の改定セルを基準にして、その1つ下のセルを判定しています。だから、返るのも1つの値です。いまは可視条件をまとめて、配列として作りたいのですから、改定セルを、同じ行では無く、データ部全体にします。テーブルの外から構造化参照するので、テーブル名を明示します。数式は次のようになります。

=IF(OFFSET(revision_table[改定],1,0)<=1,TRUE,FALSE)OFFSET関数の中を、単一セルでは無く、列のデータ範囲としてあります(revision_table[改定])。つまり、引数として配列を渡します。
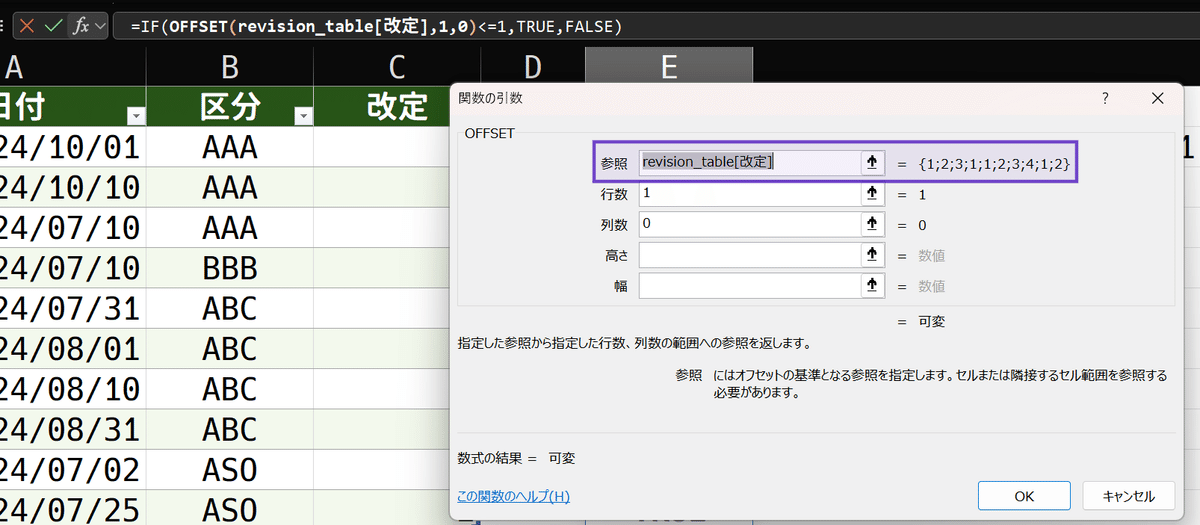
そして、IF関数に渡される引数も配列になるので、その判定結果として返されるのも配列となり、スピルされるという寸法です。後は、この数式を直接、FILTER関数に入れ込めば完成です。


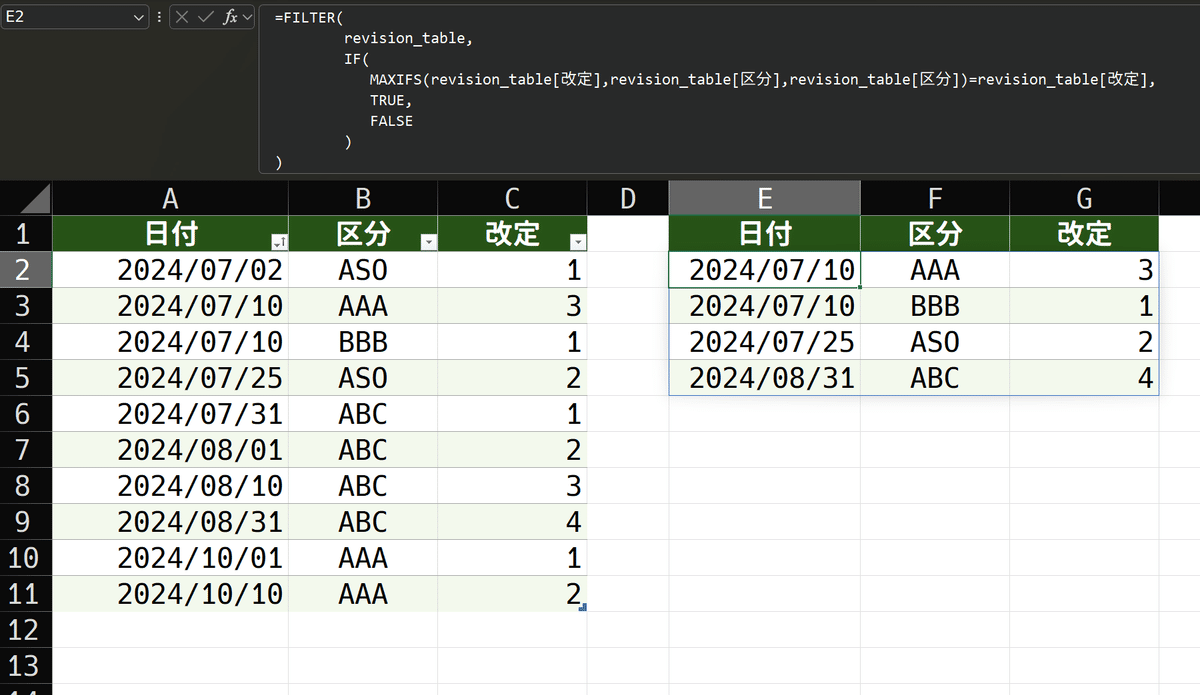
=FILTER(
revision_table,
IF(OFFSET(revision_table[改定],1,0)<=1,TRUE,FALSE)
)比較的シンプルとは言っても、可視条件の構成で少しごちゃごちゃしますね。このくらいであれば、そこまで可読性は落ちないでしょうか。
区分ごとの最大値でフィルターする数式――より汎用的な式
汎用性がない
いま作った数式は、区分でまとまっていて、かつ改定番号が昇順で並んでいるという、整然とした表を前提としていました。処理前にソートするのは実務上も重要ですが、色々の事情により、そうもいかない場合もあるのでしょう(他の列でソートしなくてはならないなど)。ですのでここからは、より表の構成に制限をかけない、つまり汎用性の高い数式を考えていきましょう。
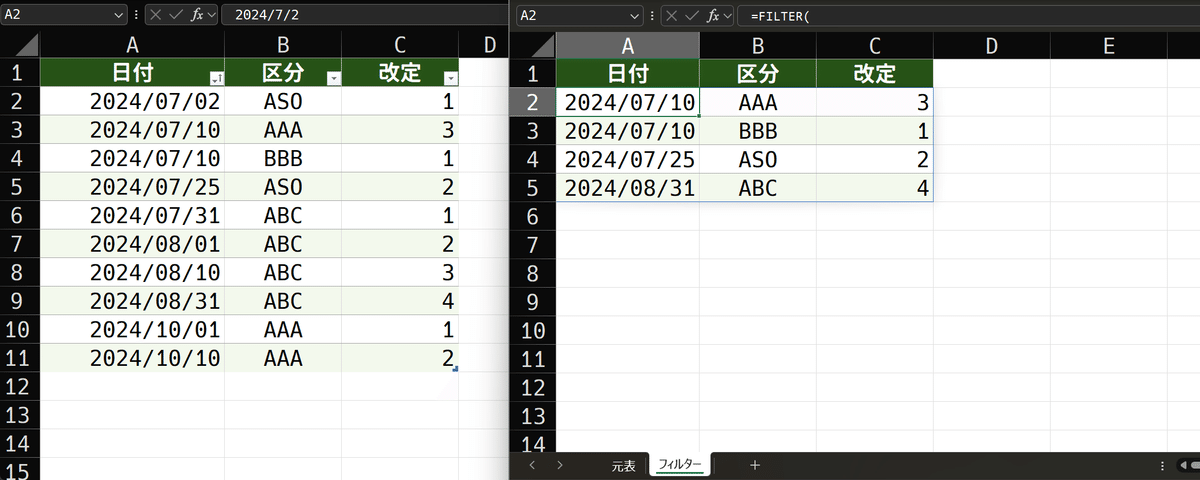
まとまっていない表
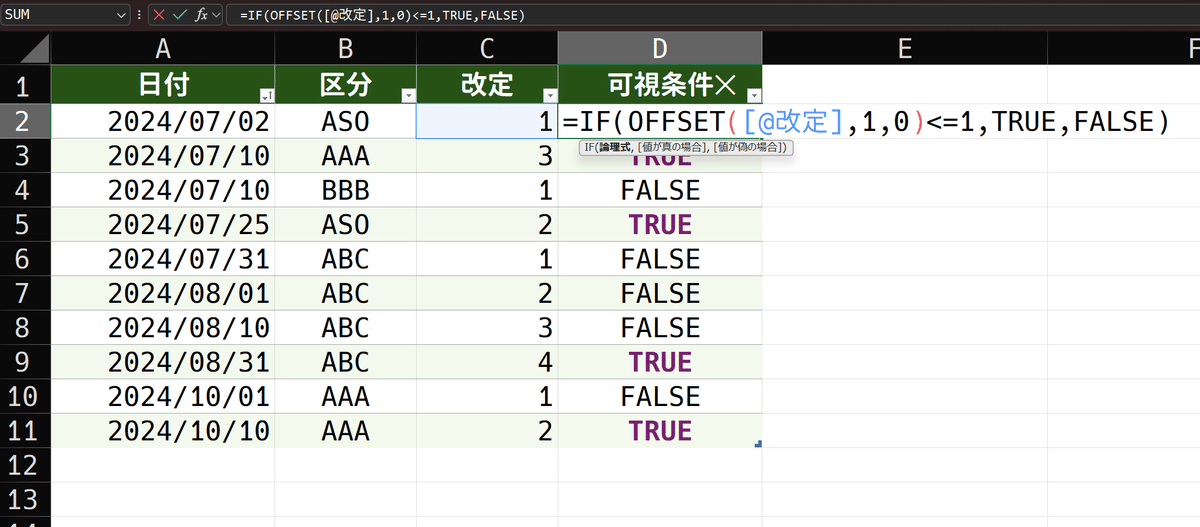
下図を御覧ください。

revision_tableを、日付で並び替えました。その事により、区分はバラバラになり、改定番号も通しで昇順になっていません。これだと、改定番号の真下を見て1であれば……という条件で可視条件を定義出来ません。
MAXIFS関数
では、どのようにして条件を設定すれば良いでしょうか。
ここで、うってつけの関数があります。それが、
MAXIFS関数
です。MAXIFS関数とは、
最大値を求める範囲
条件を判定する範囲
条件の値
を材料とする関数です。いまであれば、最大値を求めたいのは、もちろん改定列です。そして、区分ごとの最大値を求めるので、第2引数には区分列を入れます。そして、第3引数には、
第2引数の内の何であるか
を指定します。つまり、第2引数と第3引数のセットで条件を設定します。ちょっとやってみましょう。

いまは、可視条件列の中に、実験的に数式を入れています。
=MAXIFS([改定],[区分],"AAA")上記の式を入れてあります。結果は、可視条件列にあるすべてのセルで3です。
この数式のロジックは、
改定列から最大値を求めます
ただし
区分列が
AAAである条件のもとです
このようです。表現を変えると、
区分を
AAAで絞ってから
改定の最大値を求めます
となります。数式とロジックを対応させると、
改定列から最大値を求めます←[改定]
ただし
区分列が←[区分]
AAAである条件のもとです←"AAA"
こうです。ところで、なぜMAXIFS関数かと言うと、第4引数以降で、条件を重ねる事が出来るからです。つまり、第4と第5引数で2つ目の条件、第6と第7引数で3つ目の条件……という風に条件を加えられるのです。これはたとえば、区分が更に下位区分に分かれる場合などに使えます。
いま見ている区分の最大値を求める
先ほどの実験では、条件に直接AAAを入れました。今回の要件では、区分ごとの最大値を求めたいのです。どうしましょうか。
表を絞り込むのは、各区分における、最大改定値の行です。であれば、
いま見ている行の区分における最大値を求める
数式をまず作ります。いま見ている行というのは、構造化参照では@を使うので、先ほどAAAと直接入れた所を、参照に変更しましょう。

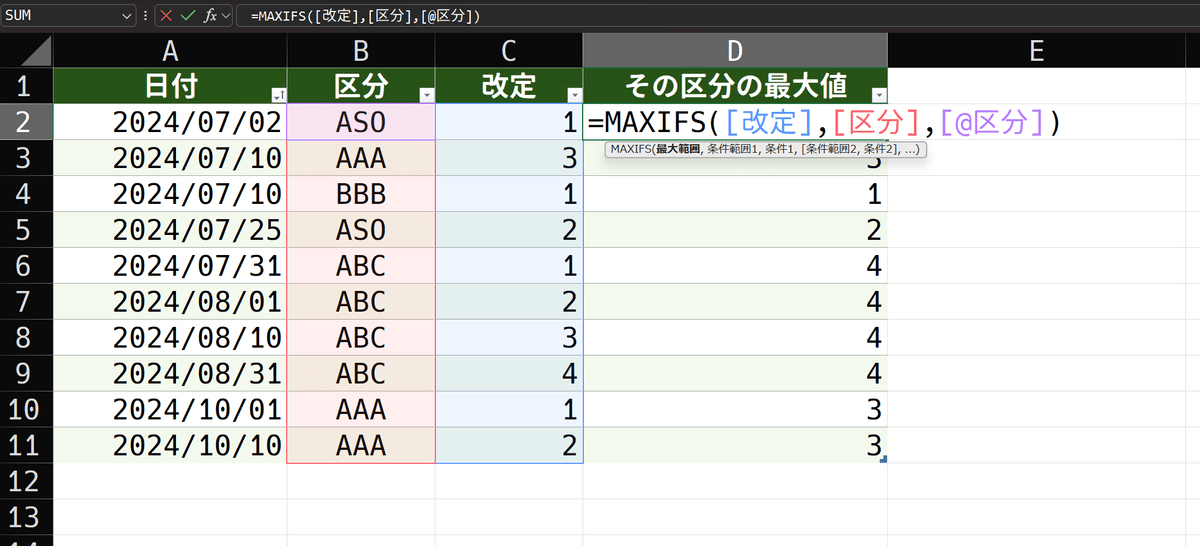
=MAXIFS([改定],[区分],[@区分])改定の最大値を出すのは言うまでもありません。区分ごとの最大値を求めるので、第2引数が区分なのも言わずもがなです。ポイントは第3引数。ここに、同じ行の区分を入れます。そうする事によって、たとえばASO区分に属する行では、
ASO区分での改定最大値
が求められ表示されます。要するに、ASOでは必ず2が、AAAでは必ず3が、というようになります。
可視条件の判定
いま作った作業列で、その区分での最大値が出るようにしました。ここから可視条件を判定するにはどうすれば良いでしょう。それは、
いまいる行の改定番号が、いまいる区分の最大改定番号と同じであるか
を判定させるのです。
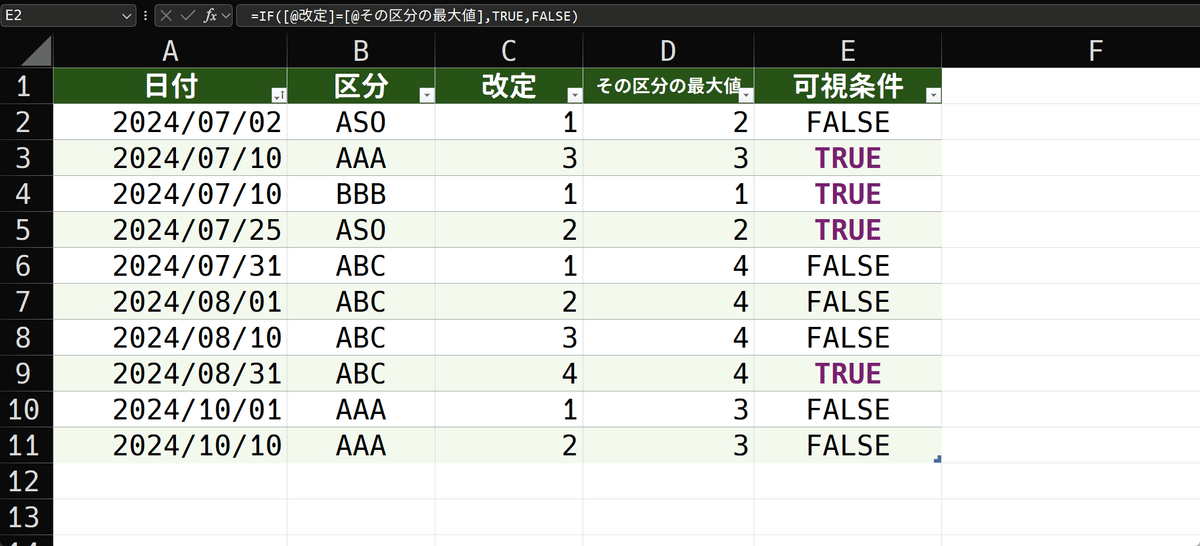
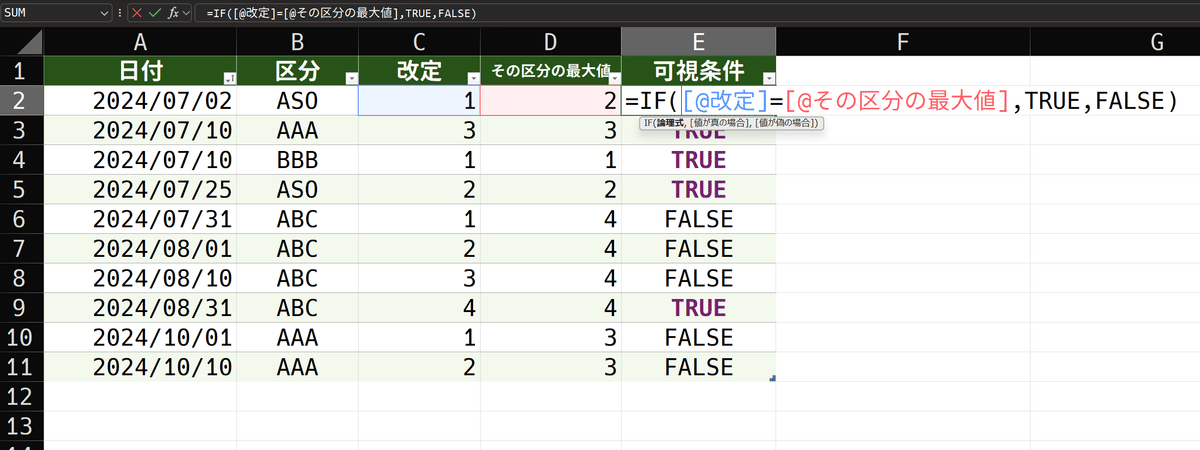
[その区分の最大値]列には、必ず区分ごとの最大値が入っています。いっぽう、[改定]列には、その行の実際の改定番号が入っています。ですから、実際の改定番号が、区分最大番号に一致すれば、それを可視とするよう仕向ければ良いのです。判定は簡単にIF関数で出来ます。
=IF([@改定]=[@その区分の最大値],TRUE,FALSE)後は、これをFILTER関数で参照させてやれば、いっちょう上がりです。

元の表が日付順なので、フィルターされたものも日付順となっています。SORT関数を使えばこれを並び替えられますが、ごちゃごちゃするので省略します。
これで、表の並び順に依存しない数式が出来上がりました。
作業列を使わない場合
私は躊躇無く作業列を使いますが、あまり作りたくない場合もあるでしょう。少し複雑になりますが、やってみます。先ほど作った作業列は、
区分での改定番号最大値
その行の改定番号と、その行が属する区分での最大値の比較
でした。そして、2番目の条件判定が一致すればTRUEとなって、可視条件となるのでした。これをまとめて、FILTER関数の中に入れ込みます。
区分最大値配列
まずは、テーブル外に数式を出します。最初のシンプルな数式作成の所でも言ったように、通常は単一セルを渡して単一の値を返すような数式に複数セルを渡すと、配列が返ります。


先ほど作業列で使用したMAXIFS関数では、第3引数、つまり、満たすべき条件の値を単一セルの値としました。だから返るのも単一の値です。ここを範囲にすると、
=MAXIFS(revision_table[改定],revision_table[区分],revision_table[区分])その範囲1つずに対して判定され配列が返る
のです。だから、結果がスピルされます。テーブルの中に作業列を残してありますが、全く同じになっていますね。
可視条件配列
次に可視条件です。ここがFILTER関数の可視行を決定する部分です。
作業列の可視条件は、シンプルなIF関数で、単一セル対単一セルの比較ですので、返るのも単一の、TRUEもしくはFALSEです。これを、範囲対範囲の比較にします。

作業列の結果と同一
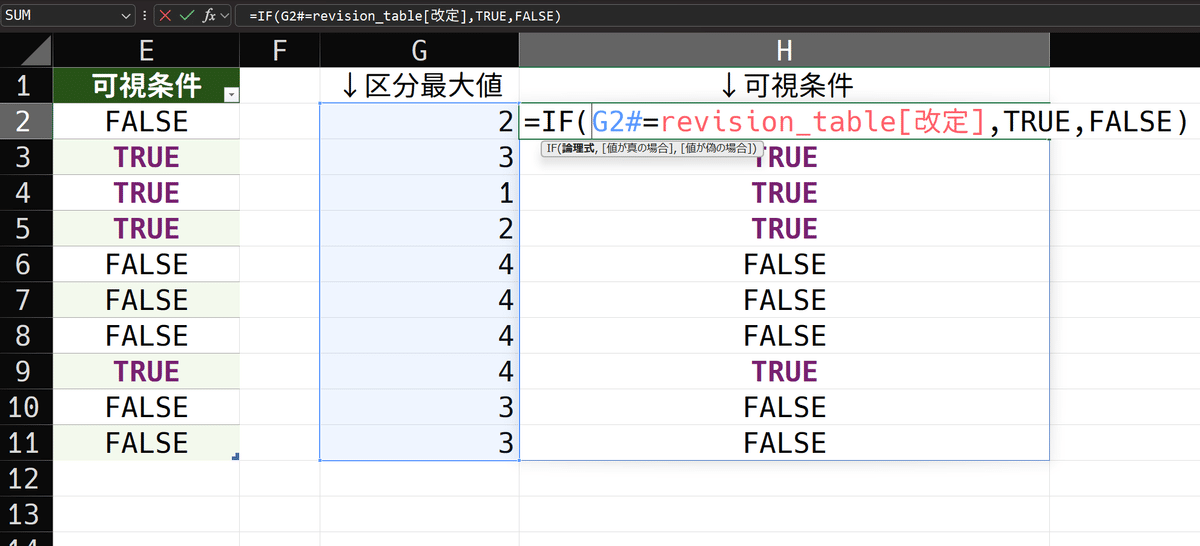
=IF(G2#=revision_table[改定],TRUE,FALSE)G2セルは、区分最大値を求める数式を入れたセルです。その後に#がついていますが、これはスピル範囲演算子と言い、スピルされた全体を参照させるものです。つまり、G2セルに入れた数式がスピルさせる範囲、G2からG11セルまでを参照させる意味です。だから実態は、G2:G13=revision_table[改定]のようになって、それぞれの配列の値が順々に比較され、その結果が、TRUEとFALSEからなる配列として返るわけです。だからもちろん、スピルされます。
数式の完成
お待たせしました。やっと数式が完成します。
まず、いま用意した、配列を返す数式2つを合体させます。先ほど作った可視条件数式には、スピル範囲演算子のG2#が参照されていて、それは隣の区分最大値数式で生じたスピルでしたので、スピル範囲演算子G2#の所に直接、区分最大値数式を入れてやります。


長い…!
ちょっと長いですね。ただ、やっている事はそんなに複雑ではありません。ロジックは、
各行で
改定番号と区分最大値が同じなら
TRUE
そうで無いなら
FALSE
こうです。そして、2の条件を担うのがMAXIFS関数だという事ですね。
最後に、この可視条件数式を、直接FILTER関数に入れます。

ロジック自体はシンプルですね。
フィルターします
revition_tableを
ただし
改定番号が区分の最大値のものだけ表示させます
こうです。ここで条件4の中身を細かく見れば、
もし
区分最大値が
改定番号に
一致したら
TRUEを返し
そうで無ければ
FALSEを返す
これを全部の行に対しておこなう
となっています。
IF関数の省略:2024年8月7日追記
この話題について調べていたら、同じような数式を提案しているものがあったのですが、そこでは、IF関数が使われていませんでした。それに倣って、数式を変更してみましょう。

IF関数が省略出来るのは当然ですね。比較演算はそのままTRUEかFALSEを返すのですから、求める挙動は同じです。いくつか前のFILTER関数の記事で、基本の書きかたとして私自身が説明した事なのに、完全にうっかりしていました。
普段はIf文を書いているから、条件分岐の時はExcelでも書きがちですね。
構造化参照
少々長い数式ですが、構造化参照を使っていて、数式が何を表現しているかは明白です。セルのアドレス参照は一切使っていません。テーブルをどこに移動させようが成り立ちますし、FILTER関数を別シートにしても構いません。構造化参照を使うと、汎用的で頑健な数式が作れます。
まとめ
今回の数式のポイントは、入れ子と関数を出来るだけ少なくした所です。配列を返す数式を使いこなすのが重要ですが、これには慣れが必要です。私は、FILTER関数でスピルさせて表を作る事自体をやりませんが、前に書いた記事のように、FILTER関数で得た配列を使って単一の値を生成し、それをセルに返すという技法もあるので、覚えておいて損は無いと思います↓
今後も、X等で見かけた問いを参照して、その要件を実現する数式を作成する、というアプローチで記事を書いて行く予定です。