Excelの数式による、住所からの都道府県名抽出――FILTER関数とCOUNTIF関数で

LEFT関数とMID関数の組み合わせ
発端
Excel関連の記事が話題になっていました。
内容は、住所の文字列が入ったセルから都道府県名を抽出する数式が上手く出来ている、というものです。
話題の数式のしくみ
その数式は、
=LEFT(A2,3+(MID(A2,4,1)="県"))このようです。これはつまり、
A2セルについて
左から4文字目に県の字が入っていれば、左から4文字抽出し
それ以外なら、左から3文字抽出する
こういうしくみです。このしくみは、
都道府県名は、(漢字で)最長4字
県名は、最長4字
都道府名は、最長3字
現行のこの状態を前提していて、
4文字目が県の字であれば、4字からなる県名(都道府では無い)なので左から4字取る
それ以外であれば、3字からなる県名または都道府名なので、左から3字取る
こうすれば、都道府県名が抽出されるという寸法です。ポイントは、
MID(A2,4,1)="県"この比較演算の部分。結果はTRUEとFALSEで返りますが、それはそのまま、1と0として数値の演算に用いる事が出来ます。だから、3を加えると、
4文字目が県である:3+TRUE=3+1=4
4文字目が県でない:3+FALSE=3+0=3
こうなって、左から都道府県名が抽出されるわけですね。
汎用性と可読性
話題になった数式、LEFT関数とMID関数を組み合わせたしくみは、先に言及した現行の都道府県名の構造および、Excelの数式とそれの評価についての機能を利用した、なかなか上手く作られたものです。Excelによる都道府県名抽出のTIPSで検索すると、色々の記事で紹介されている手法です。
ただ、この数式に対しては批判的言及があります。すなわち、
可読性が悪い
数式が成り立つための条件が多い
これらの指摘です。
先述したように、この数式は、TRUEとFALSEとして評価された結果をそのまま、数として演算して利用しています。この仕様を把握した上で更に、都道府県名の現行の構造をも知ってから数式を解釈する必要があるので、ぱっと見では意味が取れません。
また、LEFT関数を使っているので、左端に都道府県名がある事を前提していたり、都道府県名が入っていないと全く別の文字列が表示されるので、ある程度綺麗なデータが要求されます。
このような観点から、確かに当該の数式は、汎用性が高く実務にすぐ役立てられるもの、とは言えません。ですから、仕事で役に立つ数式、のようなものでは無く、Excelの仕様などを把握して巧みに作られた面白い数式、とでも見ておくのが良いと思われます。もちろん、実務に役立たないから意味無いだろう、のように無下にするようなものでも無いです。なるほどこういう考えが出来るのか、と感心して応用すれば良いのですから。
FILTER関数とCOUNTIF関数の組み合わせ
可読性と汎用性の高い数式
前置きはこのくらいにして。
ここからは、もう少し可読性と汎用性が高いような数式の作成を試みます。要件は、
住所として扱われる文字列から、都道府県名を抽出する
こうです。都道府県名は、文字列内のどこにあっても構いません。左端から始まる必要もありません。余剰の文字があってそれをクレンジングする過程で使う、というようなシナリオでも使えるようにします。
意外と難しいロジック
やろうとしている事は、大まかに次のようです。
住所の文字列について
都道府県名が入っているか調べる
入っていれば、その都道府県名を表示させる
こう書けば、簡単に見えます。けれども、これを
Excelの数式で実現する
のは、そう単純には行きません。都道府県は47個あります。それが住所に入っているかどうかを見ていくのですが、それをどう、数式で実現しましょうか。上記箇条書きのように、人間の思考の流れを書き出すのは簡単ですが、それを数式の構造に反映させ上手く機能させるロジックを描くのは、思っているほど容易では無いのです。
前提
数式を作成するにあたり、下記を前提条件とします。
テーブル化と構造化参照を使える
FILTER関数を使える
COUNTIF関数を使える
配列を理解している
都道府県名のテーブルを作る
まず、47都道府県を記載したテーブルを作ります。テーブル名は、prefectureでは無く、見やすいようにtodohukenで行きましょう。

都道府県は現行で47個です。このリストが変更されるのは、数十年に一回あるか無いかでしょう。
発端の数式は、都道府県名の文字数の構造を利用して、左端から何文字かを切り取って表示するというしくみです。しかし今は、都道府県名そのものを、住所の文字列から探すしくみにしたいのです。ですから、都道府県のリストを作っておくのは必須です。
住所テーブルを作る
次に、住所を表す文字列群で構成されたリストを、テーブルで作ります。データの由来は色々あるでしょうが、ともかく、そういうリストがあって、そこから都道府県名を抽出する必要があるというシナリオを想定します。テーブル名はaddress_tableとしましょう。

住所データ生成には、下記サービスを利用しました。
実在する地名にランダムな地番を付与して生成するため、限りなく本物っぽいデータとなります。
このように、実在の地名っぽい架空のデータが用意出来る、便利なサービスです。
都道府県名の検索
さて、この住所のそれぞれについて、都道府県名が含まれるかを検査します。どうすれば良いでしょう。住所Aにまず北海道が含まれているか調べ、次に青森県が含まれているか調べ、次に…といった具合で調べますが、どう実現させましょうか。一致を調べるのでは無いからワイルドカードが必要そうです。
COUNTIF関数
↑この記事で書いたように、COUNTIF関数は、ワイルドカードが使えます。一番上の富山県の住所であれば、

=COUNTIF(address_table[@住所],"*富山県*")このようにすれば、富山県が含まれていれば1を返します。
しかしあくまで、富山県1つの判定です。これを47都道府県について検査したいのです。どうしましょう。作業列を47列つくって判定させるべきでしょうか。
COUNTIF関数のスピル
通常、COUNTIF関数は、
あるセル範囲に
対象の条件を満たすものが
何セルあるか
このように使います。たとえば、

=COUNTIF(address_table[住所],"*県*")上記のようにすると、住所列のデータ範囲に対し、県の文字を含むセルがいくつあるかを数えます。いま住所リストは1000件あるので、その内の843セルが県を含んでいるというわけです。
これが通常の使いかたですが、ここで発想を逆転させます。つまり、
第1引数に1セルを指定し、第2引数に複数セル範囲を指定する
のです。
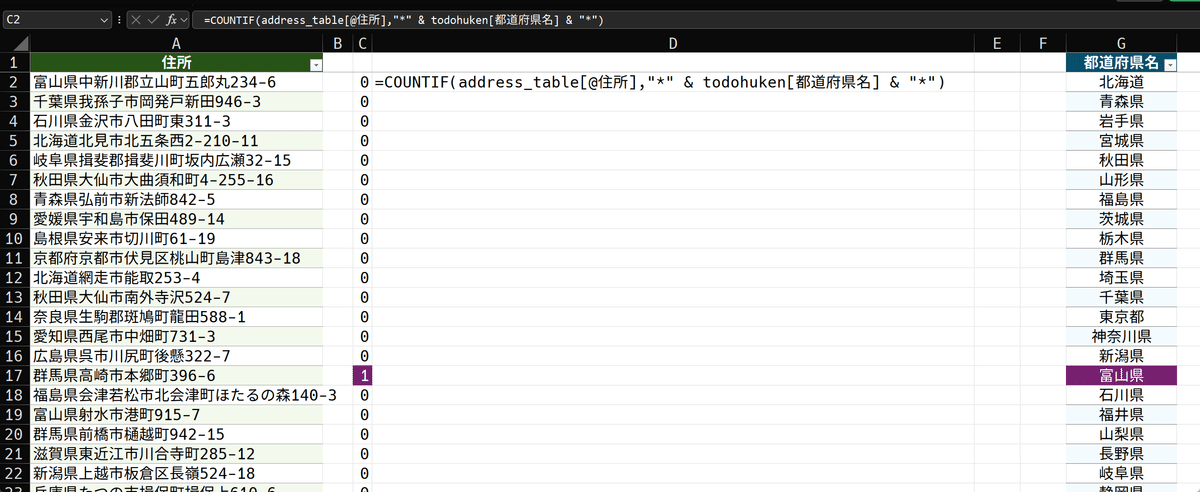
=COUNTIF(address_table[@住所],"*" & todohuken[都道府県名] & "*")数式はこのようです。[@住所]は同じ行の住所ですから、一番上の富山県の住所です。これに対し、第2引数で複数セル範囲を条件として指定すると、
複数条件それぞれが評価され、結果は配列として返る
のです。数式では、都道府県名テーブルのデータ範囲を第2引数として指定しているので、47都道府県すべてと比較し、47個の0または1の結果が配列として返ります。配列が返ればスピルされるので、0と1で構成された47セルのスピルが出来上がります。高さを合わせてあるので、富山県の所が1になり、それ以外は0となっています。
前掲の記事で紹介したように、COUNTIF関数は、条件を満たしたセルの個数を返します。ここでは第1引数に単一セルを指定し、第2引数に47セルを指定したので、必ず0か1で出来た配列が返ります。FIND関数のようにエラーを返さないので、エラーハンドリングの必要もありません。これは極めて便利な性質です。
FILTER関数による絞り込み
上記記事で紹介しましたが、FILTER関数は、
第1引数で、フィルターを施したい範囲や配列を指定
第2引数で、行か列の可視条件を指定
します。第2引数は、行か列の可視状態を定義するスイッチのようなもの、なのでした。0であれば非表示、それ以外の数値であれば表示です。
先に、COUNTIF関数のスピルで、47都道府県名すべてについて条件判定をし、結果を0と1で構成される配列で返しました。そして、FILTER関数は、可視状態を定義する引数でフィルターします。であれば、これを組み合わせれば良いのです。
COUNTIF関数は
COUNTIF(address_table[@住所],"*" & todohuken[都道府県名] & "*")こういう数式でしたので、これをFILTER関数に入れ込みましょう。まず、都道府県名を表示させる列を追加します。

このデータ範囲に、FILTER関数を入れましょう。

上手く抽出されています。数式を詳しく見ましょう。

=FILTER(
todohuken[都道府県名],
COUNTIF([@住所],"*"&todohuken[都道府県名]&"*")
)todohuken[都道府県名]は、47都道府県名のリストです。目的は、都道府県名を抽出する事ですから、このリストを絞り込めば良いわけです。そして、先ほど示した、COUNTIF([@住所],"*"&todohuken[都道府県名]&"*")によって配列を作り、それをFILTER関数の可視条件とします。一番上だと富山県ですから、COUNTIF関数は、都道府県名リストに対し評価をおこない、上から0が続いて富山県の所で1になり、後は0が続く配列が返ります。その結果、富山県の所だけが1となり、FILTER関数は、富山県を返すのです。
ワイルドカードを外に出す
これでも良いですが、COUNTIF関数の部分がちょっと見づらいです。
COUNTIF([@住所],"*"&todohuken[都道府県名]&"*")見づらいのは、含むという条件を示すために、都道府県名データをアスタリスクで挟んで、ワイルドカードにしているからです。これを外に出しましょう。

都道府県名データの右側に、アスタリスクで挟んだワイルドカードを作って追加しました。FILTER関数に入れるCOUNTIF関数は、ここを参照させてやれば良いのです。

=FILTER(
todohuken[都道府県名],
COUNTIF([@住所],todohuken[検索文字])
)だいぶすっきりしました。都道府県名をフィルターするための可視条件を、隣の検索文字、つまりワイルドカード入りの文字を参照させる事で作ったのですね。
都道府県名が無かったら?
データは綺麗とは限りません。都道府県名が無い場合もあります。その場合には、FILTER関数の第3引数で指定しましょう。
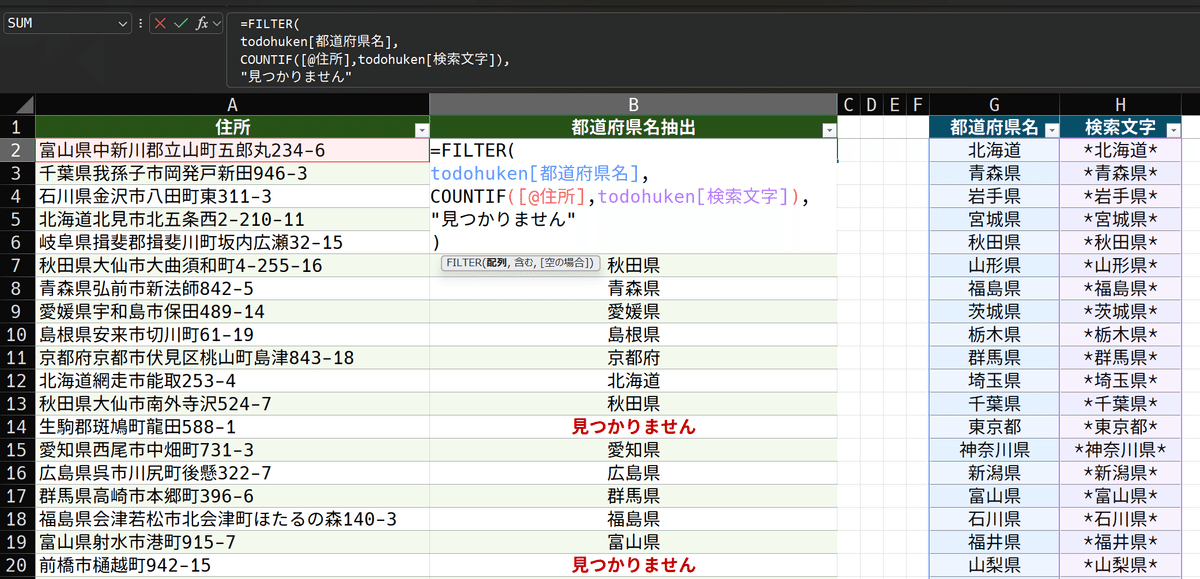
わざと都道府県名を抜いてあります。そして、FILTER関数の第3引数に、見つかりませんの文字列を入れました。
都道府県名が複数あったら?
ペーストミス等で、住所に2以上の都道府県名が入っていたらどうでしょうか。やってみましょう。
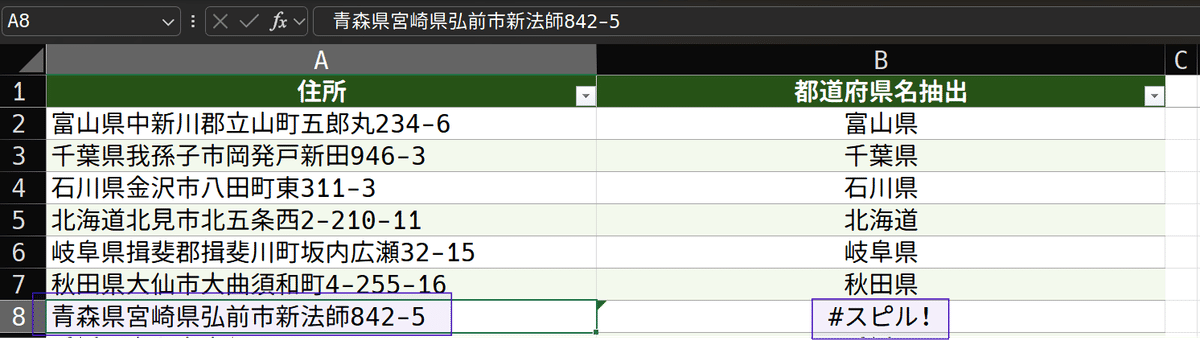
青森県弘前市をわざと、青森県宮崎県弘前市としました。こうした場合、抽出セルにスピルエラーが発生します。これは、
要素が2以上の配列が返された
からです。作成した数式は、COUNTIF関数で、全都道府県名を検査して可視条件を作っています。ですから、都道府県名が2以上あれば当然、配列に属する1が2つ以上になります。そしてその結果、FILTER関数は、都道府県名を2つ以上返します。

テーブル内ではスピルは使えませんから、スピルエラーが発生します。また、FILTER関数のエラーハンドリングは、スピルエラーには対応しません。そもそも見つかっているのですから当然ですね。
CONCAT関数による処理
いまのスピルエラーは、配列
{"青森県";"宮崎県"}を、テーブル内の単一セルに返そうとしたから起こりました。それなら、こういう配列をまとめて処理すれば、エラーが回避出来そうです。ここでは、CONCAT関数を使いましょう。

数式内インデントは、関数の役割を分けて見えるようにしているものなので、実際には特に入れる必要はありません。
CONCAT関数は、シンプルに文字列を結合するものです。TEXTJOIN関数のように、結合文字(delimiter)や空白処理を入れる必要が無いので、数式がすっきり書けます。いま作ったFILTER関数は、文字列を返すのが保証されていますので、そのまま結合して問題ありません。
複数の都道府県名が入った住所を検索して単純に結合すれば、青森県宮崎県のように、複数の都道府県名が結合されて返ります。必要があれば、このような結果のセルに条件付き書式で色をつけたり、作業列でチェックを入れると良いでしょう。

上図では、都道府県名が5文字以上(4文字より大きい)の場合に注意を表示するようにしてあります。都道府県名は最大4文字なので、5文字以上なら都道府県名が2つ以上入っているのを意味するからです。
変更に強い
テーブルに都道府県名のリストを定義して検索しているので、都道府県名に変更があっても問題無く対応出来ます。
たとえば、寿司大好県というのが新たに作られたとしても、それをテーブルの適当な所に追加すれば、そのまま検索され判定されます。

最長の都道府県名が5文字になりましたが、何の支障も無く抽出されます。もちろん、データチェックで文字数を使う場合の判定は変更する必要がありますが。動的に変更するなら、LEN関数とMAX関数を使って定義すれば、数値を直打ちしなくても良いです。

まとめ
CONCAT関数のような処理は、要件に合わせて実装するとして、シンプルに都道府県名抽出の機能を持たせた数式は、
=FILTER(
todohuken[都道府県名],
COUNTIF([@住所],todohuken[検索文字])
)このようでした。あらかじめ都道府県名のリストを作成し、それと比較演算する必要がありますが、数式としては、何をしているのかが明確で、可読性も悪くありません(COUNTIF関数の挙動の理解には慣れが必要です)。
都道府県名が住所のどこにあっても検索出来ます。たとえば、余剰の文字や空白が先頭に入っていても、問題無く機能します。

ただし、COUNTIF関数で47都道府県名を検索しているので、時間は少しかかります。力技ですからね。と言っても、最近のPCであれば、数万件くらいであれば、実用上は問題無いでしょう。私が使用している、2年くらい前のRyzen 7のPCでは、10万件あってもそれほど時間はかかりませんでした。何十万件もあるようなデータであれば、Excelにこだわらず、他のやりかたなども検討しましょう(一気に30万件近くにしたらフリーズしました)。実務的に重要なのは、ただ速度を高める事などでは無く、他者との共有のしやすさや可読性、色々のデータに対応出来る汎用性などのバランスを取る事です。
そもそも、住所データから都道府県名のみ抽出するシナリオというのは、それほど多く無いと思います。けれど、実務的には様々の要件での作業をおこなう可能性があるので、こういう方法もある、というのを知っておくのは良い事です。
余談:
彦一の要チェックは有能な選手のリサーチ過程でやるものだから、エラーチェックみたいな時には使いませんね。