第3回 PythonでWEBスクレイピング→特定の部分のみ抽出

おはようございます!KUROMAMEです。
今日も頑張りましょう!!!
本日は特定の部分のみを抽出する方法です。
前回までのコードはこちらです↓
1.import requests
2.res = requests.get('収集したいページのURL')
3.#print(res.text)
4.with open('保存したいhtml名(今回はyahoo.html)','w',encoding="utf-8")as file:
これで特定のページの情報をHTMLに保存できましたね。
でも、仕事で使ったり趣味で何かをするのであれば、
こんなに情報はいらないですね(-_-;)
特定の要素のみを抽出していきます。
前回に引き続きyahooのトップページを抽出します。
まず、ctrl+shift+iを押し、デベロッパーツール画面を開きます。
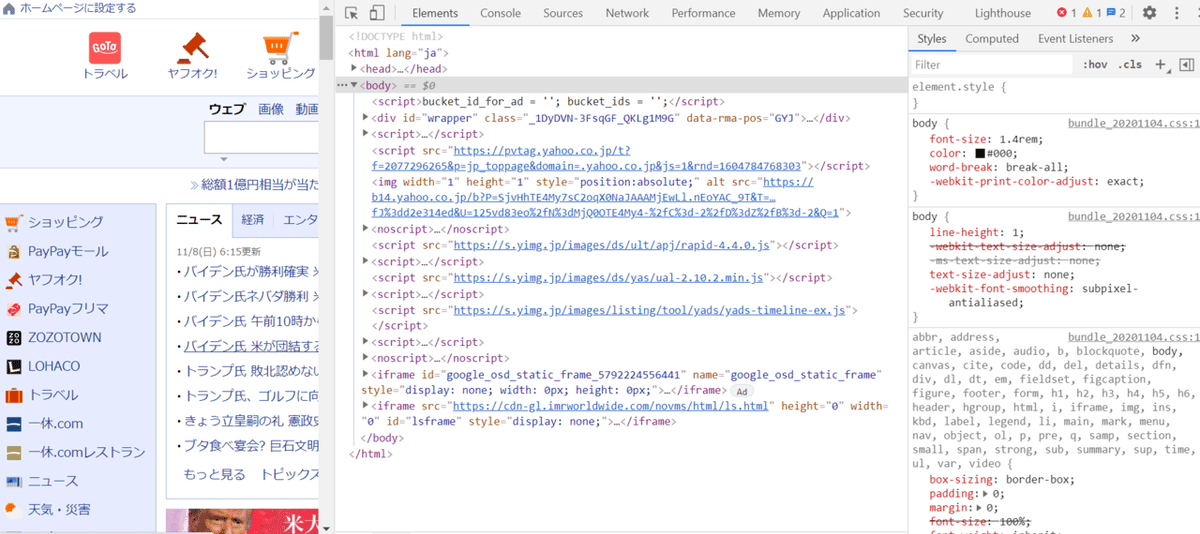
↑こんな感じの画面が表示されましたね
これはWEBページのHTMLやCSS情報を見ることができる画面です。
詳細を見たい方はこちらをどうぞ
ざっと下記のコードで取得できます。
import requests, bs4
res = requests.get('https://www.yahoo.co.jp/')
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, "html.parser")
elems = soup.select('.fQMqQTGJTbIMxjQwZA2zk')
for elem in elems:
print(elem)
すると・・・

こんな感じででてきました。
詳細を説明します。
まず先ほどのデベロッパーツール画面にて、
画像の〇で囲んだ←部分をクリックし、抽出したい部分にカーソルを
合わせます。 今回はトップのニュース部分です。

するとカーソルを合わせた下に、ニュースのHTML情報が表示されます。
右側にも表示されますね。そのHTML部分をコピーし、
上記コード内の↓に入力
elems = soup.select('ここにHTML情報を入力')
今回はclassの情報を抜いているため、必ず先頭に「.」を入れます。
id属性は「#」を入れますのでお忘れなく!
詳細を勉強したい方は↓がおすすめ
話は戻りますが、先ほどのように取得したHTML情報を入力することに
よって部分的に情報を抜き取れます。
簡単でしたが、また続きは次回のお楽しみで
この記事が気に入ったらサポートをしてみませんか?