
【LoRA】過学習が起きたときの解決法

Stable diffusionでLoRAを使っていて、誰しも一度は過学習に関するトラブルに見舞われた経験があると思います。今回はそのようなトラブルにあった際の対処法や、そもそも過学習による画像の崩壊がどのようなものなのかを解説します。
そもそも過学習とは
過学習(Overfitting)とは、モデルが訓練データに過度に適合してしまう現象のことを指します。具体的には、LoRAが訓練データの細かい特徴やノイズを学習しすぎてしまい、一般化能力が低下することを意味します。ですから、過学習が起きると生成される画像もノイズが混じったり、意味のない変形をしたりすることがあります。過学習の主な原因はそのLoRAのトレーニング時の訓練データ数の不足や、モデルの複雑さが過剰であることです。また、パラメータの設定や学習率も過学習に深く関与します。
しかし、場合によってはLoRA自体に問題が無くてもプロンプトやその他の設定により同様の問題が発生することがあります。

上の画像は、私が意図的に過学習(Overfitting)を起こした画像です。使用したLoRAは以前の記事で紹介した私のArcadiaというモデルです。こちらのLoRA自体は過学習の問題を持たないモデルですが、設定次第では画像のようなノイジーな画像が出力されます。ちなみに、本記事の見出し画像もArcadiaを用いて生成したものです。そちらは過学習による崩壊がないのがお分かり頂けるかと思います。
画像が崩壊する原因
過学習による画像の崩壊の原因は2種類に大別できます。
LoRA自体に問題がある場合
この場合は、そもそもLoRAをトレーニングする時の設定に問題があります。具体的には、
教師画像数の不足
過剰なステップ数
繰り返し数とエポック数のバランスが悪い
高すぎる学習率
教師画像のバリエーション不足
などが挙げられます。
このような場合はLoRAを作り直した方が良いですが、一応対処法はありますのでご安心下さい。
LoRAには問題がない場合
これは、画像生成時のプロンプトや設定に問題があることを意味します。LoRA自体には問題がないので、LoRAを作り直したり他のLoRAを探したりする必要はありません。
生成時の設定による解決
LoRA自体を改善するのは面倒なので正則化などの複雑なステップを伴うので今回は生成時の設定だけで解決を図ります。
プロンプトとネガティブプロンプト
そもそもプロンプトとネガティブプロンプトが適切かどうかを確かめます。 プロンプトの中に、過剰な強調表現が無いか確認しましょう。(night:1.9)とか書いてたら、それが原因なことが多いです。また、プロンプトの長さも重要です。プロンプトが長すぎる場合、崩壊が起こりやすいと言われています。
ネガティブプロンプトも確認しましょう。こちらは長さや強調の問題ではなく、プロンプトとの類似度が問題になり得ます。要するに、プロンプトと全然関係ないことを書いたらダメってだけです。
サンプリングステップ
よくある誤解として、サンプリングステップが多すぎると画像が崩壊する、というものがあります。しかし、これは誤りです。サンプリングステップが多いと計算回数は高くなりますが、それはノイズを生む原因にはなりません。実際には、サンプリングステップを増やしたらアーティファクトが出てしまった、というケースは存在します。しかし、それは過学習ではありません。プロンプトが悪いだけです。適当でないプロンプトを用いて何度もサンプリングすれば変な画像が出るのは当たり前ですよね。
稀にこれを過学習と混同して誤った情報を発信している人がいますのでご注意ください。
LoRAのweight(重み)
元も子もない話ですが、weightを下げれば画像の崩壊リスクは下がります。過学習の問題があるLoRAというのは、”強すぎるLoRA”のようなものなので、weightを下げれば良いのです。
ただ、LoRAによってはweightを下げてしまっては意味がなくなるものもあります。と言うのも、画風を調整するような効果を持つLoRA(スタイルLoRAなどと呼ばれるもの)の場合はweightを下げるだけである程度改善できますが、特定の物や人物、ポーズなどを生成する効果を持つLoRAの場合はweightを下げるとそれらのものが生成されなくなり得ます。なのでweightを下げてしまってはLoRAを使う意味が無くなってしまいます。
CFGスケール
CFGスケールについては、”CFGスケールを高く設定すると、プロンプトに対する忠実度が増す”という程度のことは聞いたことがあると思います。しかし、CFGスケールの概念や意味については知らない方も多いのではないでしょうか。ということで、まずはCFGスケールについて解説します。
CFGスケールとは
CFGスケール(Classifier Free Guidance scale)を理解するためには、Stable diffusionが画像をベクトルとして捉えているということを理解する必要があります。Stable diffusionはプロンプトやネガティブプロンプトを数値としてのベクトルに変換し、生成時にはその値を使って画像を生成します。
ここで、プロンプトは求める画像の要素、ネガティブプロンプトは取り除きたい要素を記述することを考えてください。Stable diffusionはプロンプトとネガティブプロンプトからそれぞれの方向ベクトルを数値的に取り出します。説明のため、プロンプトのベクトルを$${\vec{P}}$$,ネガティブプロンプトのベクトルを$${\vec{N}}$$とします。Stable Diffusionはこれらから$${\vec{P}-\vec{N}}$$を作り、これを使って求める画像の方向を定め、サンプリングするのです。
ここでのCFGスケールの役割は、$${\vec{P}-\vec{N}}$$をスカラー倍することです。つまり、CFGスケールの値が3なら$${\vec{P}-\vec{N}}$$を3倍、11なら11倍するということです。然るに、CFGスケールの値をtとすると、実際の生成ではベクトル$${t(\vec{P}-\vec{N})}$$を使ってサンプリングを繰り返すことになります。
なので、CFGスケールの値が大きければ、少ないサンプリングステップで理想的な画像を得ることができる一方で、値が大きすぎるとサンプリングによって求めていた座標を超えてしまい、ノイズだらけの画像が生成されます。
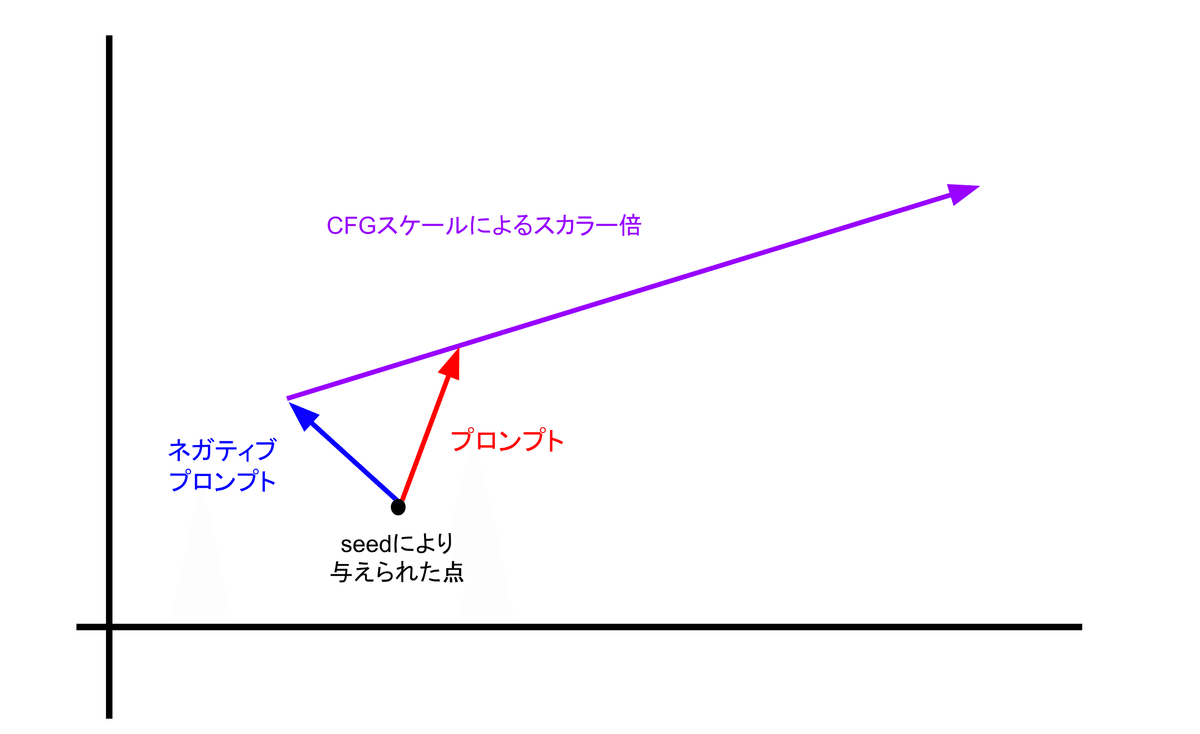
実際の生成で扱われるベクトルは非常に高次元なものですが、平面は2つの線型独立なベクトルにより定義されるので、ここでは上の平面の図で問題ありません。
簡単にまとめると、CFGスケールはプロンプトとネガティブプロンプトの差を伸ばす ブースターのようなものです。
以上でCFGスケールについてはご理解いただけたかと思います。前述の通り、CFGスケールが大きすぎると過学習状態になり画像が破綻することがあります。過学習による破綻が起きた時というのは、「強い」LoRAを使っていたり、LoRAを複数使っている時が殆どです。LoRAも生成時のベクトルに影響を与えます。(厳密には、LoRAはベクトルの調整・変換行列として機能しますが、ここでは影響を与える、という程度の認識で問題ありません。)
CFGスケールによる解決
一般的に、適切なCFGスケールの値は7〜10と言われています。この値は計算により算出されたものではなく、単にユーザーの経験則によるものです。
しかし、画像の破綻が起きるような場合では、生成時に使われるベクトルが大きすぎるのが問題なのです。ということで、CFGスケールを下げれば良いのです。ただし、闇雲にただCFGスケールの値を下げるだけではいけません。先ほどのCFGスケールの概念をご理解頂ければ分かると思いますが、CFGスケールはプロンプト、ネガティブプロンプト、サンプリングステップとも関係があります。求める画像を得るためには、CFGスケールを下げたらサンプリングステップを上げる必要があります。これは、CFGスケールが下がると生成時に使うベクトル$${t(\vec{P}-\vec{N})}$$の絶対値が小さくなるためです。また、サンプリングステップを上げるならば、不適切な画像やアーティファクトの生成を避けるために、プロンプトが適切であることも確認してください。CFGスケールとサンプリングステップの適切な値は場合によって異なりますが、私の経験則からはCFGスケール4〜6 サンプリングステップ27〜40程度が良いと思います。
まとめ
以上の方法により解決できない場合、LoRAを作り直したり別のものを探したりする必要があります。ですが、上記の方法で解決できるパターンも意外と多いので、過学習による画像の崩壊にお困りの時は是非参考にしてみてください。