
二値分類の過学習対策 AIを使って日経平均株価の予測に挑戦 学習データのツボはどこ?編

前回の記事より、今後の課題を振り返る
前回は、翌営業日の日経平均株価が上がるか、下がるかを予測する二値分類に関して、評価データの特徴を学習データに与える目的での説明変数の追加(データマシマシ)とAIモデルの簡素化による過学習への影響を確認しました。
結果は、二値分類としてのAccuracyが61.37%となりました。
これまではAccuracyが50%前後だったので、驚きの結果でした。
過学習の指標であるVALIDATION ERRORの右肩上がりの状況は続いていますが、レベルそのものはかなり低下(15.00 → 0.85)しました。
こうした状況の要因として、AIモデルの学習データに対する過度な最適化が抑えられていることが推測されます。
つまり、VALIDATION ERRORを改善するには、学習データでのAIモデルの過度な最適化をさらに抑える必要があると考えられます。
実際、過学習を抑える方法について調べていたところ、TensorFlowのウェブサイトには、過学習の要因としてAIモデルのトレーニングのやりすぎが挙げられていました。
AIモデルのトレーニングのやりすぎに関して、私が気になったのは、私が使用している学習データのボリュームです。
私が使用している学習データは約12900行(営業日)、評価データは約235行(営業日)です。
学習データのボリュームが多すぎることでAIモデルの過学習が進んでしまうのではないかという仮説が考えられます。
そこで、今回は学習データを削減すると過学習の状況と評価のAccuracyがどうなるのかを検証します。
学習データの削減方法を考える
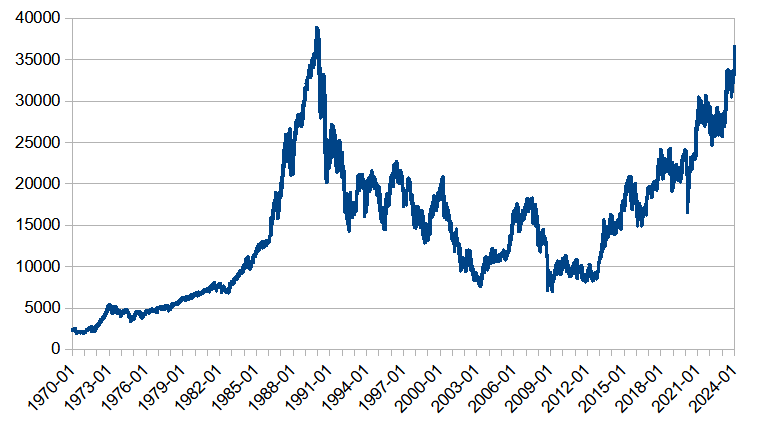
私がAIモデルの学習および評価に使用している日経平均株価の参照期間は、1970年1月5日~2024年1月31日です。
この期間における日経平均株価の終値の推移は、下記の通りです。
評価データは、これまで通り後半の約1年分(約235行)を使用するとして、学習データをどう選択するかが重要です。
学習データを選択するポイントは、AIモデルが二値分類の予測を高い精度で行えるようにすることです。
評価データがおよそ2023年以降であるため、株価が上昇するケースは学習データに含めるべきです。
また、株価が下落および停滞するケースも含めるべきと考えます。
学習データの範囲をおよそ1985年~2022年とすると、株価の上昇、下降、停滞がすべて含まれることになりますが、データの削減という点では不十分だと思われます。
思い切って、およそ2006年~2022年とすると、2008年のリーマンショックや2013年以降のアベノミクス相場が含まれており、かつ、データの削減という観点でも良さそうだと考えます。
このため、学習データの範囲をおよそ2006年~2022年としてAIモデルの学習および評価を行うことにします。
AIモデルの学習および評価を実行
使用するAIモデルは、前回と同じく2層Affine構造とします。
また、前回の結果を考慮し、学習データのシャッフルの設定は無効とします。
以下に、学習データをおよそ2006年~2022年に限定した場合の学習曲線と学習データを削減していない前回の学習曲線を示します。


前回の学習曲線と比べると、学習データを削減したことでより過学習が進んでいることが確認できます。
どうやら、削減してはいけないデータを削減してしまったようです。
続いて、混同行列の比較を行います。


二値分類のAccuracyが59.22%と、前回の61.37%から低下していることが確認できます。
以上の結果から、学習データをおよそ2006年~2022年に限定すると、過学習が進んでしまうことが確認できました。
それはつまり、およそ1970年~2005年の学習データにVALIDATION ERRORを押さえる特徴が含まれているのではないかと推測されます。
早速、確認することにしました。
下記に、学習データをおよそ1970年~2005年に限定した場合の学習曲線と混同行列を示します。
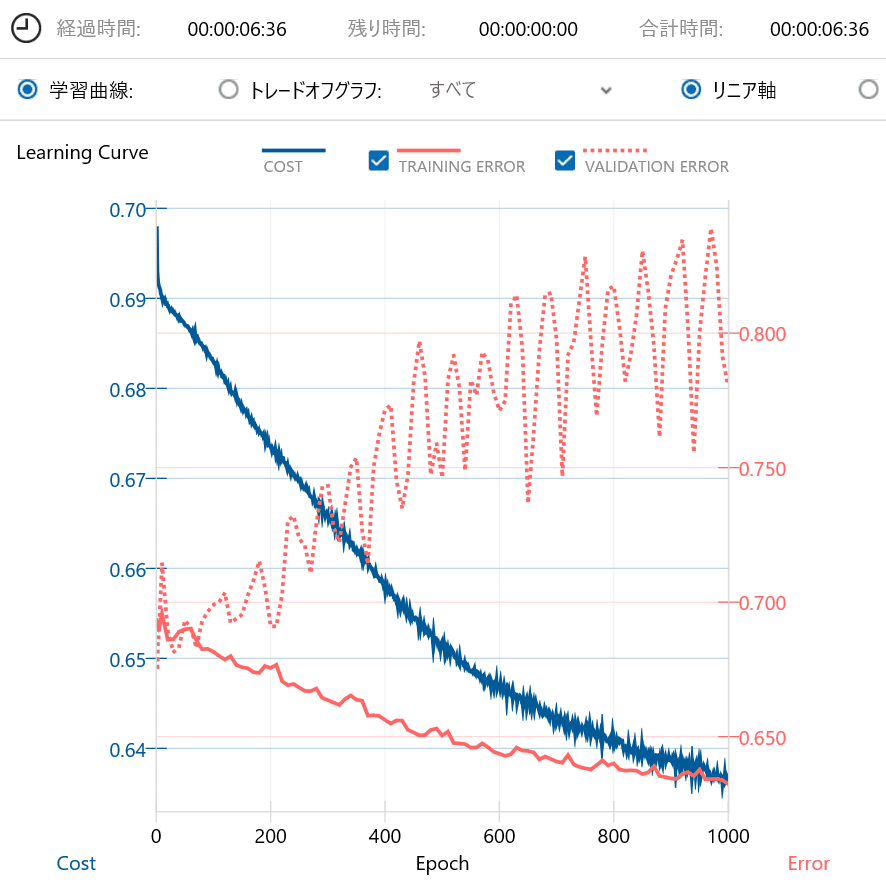

学習曲線に関して、VALIDATION ERRORは最大値が0.8強と抑えられており、期待に近い結果となりました。
しかし、混同行列はAccuracyが54.50%と期待した60%を下回るどころか、およそ2006年~2022年の学習データを使用した場合と比べても低い結果でした。
改めて、日経平均株価の終値の推移を見ると、1970年~1985年までは変化量が小さいことが確認できます。
このため、この辺りのデータは学習データから取り除いても問題ないのではないかと考えました。
そこで、学習データをおよそ1986年~2005年に限定した場合にどうなるかを確認しました。

学習データをおよそ1986年~2005年に限定した場合の学習曲線は、VALIDATION ERRORの最大値が若干高くなることが分かりました。
また、VALIDATION ERRORの増加に伴い、TRAINING ERRORは低下していますので、過学習が進む方向であるということが確認できました。

混同行列は、学習データをおよそ1970年~2005年に限定した場合と比べると若干改善しています。
続いて、学習データをおよそ1986年~2000年に限定した場合にどうなるかを確認しました。

VALIDATION ERRORは、学習データをおよそ1986年~2005年に限定した場合と比べると、最大値が大きくなっているのが分かります。

混同行列においても、学習データをおよそ1986年~2005年に限定した場合と比べると、Accuracyが若干低下しています。
これまでの結果を整理すると、下記のようになります。
学習データの期間とAccuracy
およそ2006年~2022年: Accuracy=59.22%
およそ1970年~2005年: Accuracy=54.50%
およそ1986年~2005年: Accuracy=56.65%
およそ1986年~2000年: Accuracy=56.22%
およそ1970年~2022年: Accuracy=61.37%(前回の結果)
以上を踏まえると、学習データに2022年に近い後半を含ませた方が良さそうです。
このため、学習データをアベノミクス相場を含むおよそ2013年~2022年に限定した場合にどうなるかを確認しました。


学習データをおよそ2006年~2022年に限定した場合と比べてAccuracyの改善を期待しましたが、結果は残念ながら改悪でした。
続いて、学習データをおよそ1986年~2022年に限定した場合にどうなるかを確認しました。


なぜかAccuracyが62.66%となりました。
再度、これまでの結果を下記に整理します。
学習データの期間とAccuracy
およそ1970年~2005年: Accuracy=54.50%
およそ1986年~2000年: Accuracy=56.22%
およそ1986年~2005年: Accuracy=56.65%
およそ1986年~2022年: Accuracy=62.66%(最高値)
およそ2006年~2022年: Accuracy=59.22%
およそ2013年~2022年: Accuracy=56.65%
およそ1970年~2022年: Accuracy=61.37%(前回の結果)
これまでの結果から、私なりの学習データに対する考察を下記にまとめます。
私なりの学習データに対する考察
学習データの量が多くても過学習が進むとは限らない
およそ1970年~1985年のデータは評価に悪影響を及ぼす可能性が高い(原因は不明)
評価を高めるための要素は学習データの広い期間に分散していると思われる
上記の考察から思いついたのは、説明変数を増やすことで更なる評価結果の改善が見込めるかもしれないというアイデアです。
現状の説明変数は、2日分のローソク足データ、SMA, ボリンジャーバンド、MACDです。
これに対して、日数を増やすのが良いのか、あるいは、新たな要素を追加するのが良いのかは分かりません。
今後の課題
学習データの期間をおよそ1986年~2022年として、説明変数を増やした場合の検証を行います。
説明変数をどのように増やすかについては、もう少し検討します。