
二値分類の過学習対策 AIを使って日経平均株価の予測に挑戦 データマシマシ&AIモデル簡素化編

前回の記事より、今後の課題を振り返る
前回は、翌営業日の日経平均株価が上がるか、下がるかを予測する二値分類に関して、学習データの標準化による過学習への影響を確認しました。
結論としては、学習データを標準化したことでより過学習が進んだ(状況が悪化した)と言えます。
私なりに過学習が進むことの意味について、次のように考えました。
一つは、学習データと評価データの特徴が異なっているのではないかということです。
どちらも似た特徴を有しているならば、VALIDATION ERRORは低下していくはずだと考えました。
そして、もう一つは、AIモデルが学習データに過剰に最適化されてしまうのではないかということです。
AIモデルと学習データの相性が良すぎるのではないかと考えました。
こうした点を踏まえて、対策として以下の点を挙げました。
私なりに考えた過学習対策
学習データに評価データの特徴を与えるため、SMA, ボリンジャーバンド、MACDの情報を追加する
LSTMの構造を今の5段数珠つなぎから2段数珠つなぎに変更する
ちなみに、今回の学習データおよび評価データは、前回の記事で紹介したStooqからダウンロードしたデータを流用しています。
このため、参照期間は前回と同じく、1970年1月5日~2024年1月31日です。
また、今回の学習データおよび評価データに対しても標準化を行っています。
ただし、今回のデータは、ローソク足データ、SMA, ボリンジャーバンド、MACDで構成されます。
このため、各グループ個別で標準化を行いました。
例えば、ローソク足データに対しては、2日分のローソク足データを一つのグループとして標準化しました。
AIモデルに使用したRNN LSTMの構造図
2段数珠つなぎに変更したLSTMの構造図を下記に示します。

前回使用したAIモデルに対する修正箇所は、以下の通りです。
AIモデルの修正箇所
InputのSizeを28に修正
(Open, High, Low, Close)*2
(5SMA, 25SMA, 75SMA)*2
(-2σ, -σ, 20SMA, +σ, +2σ)*2
(MACD, Signal9)*2
ReshapeのOutShapeを2,14に修正
Reshapeで1行28列のベクトルデータを2行14列のベクトルデータに変換しています。
そして、RecurrentInputおよびRecurrentOutputで挟まれた層では、分割された1行14列のベクトルデータに対して、処理を合わせて2回行います。
AIモデルの学習および評価を実行
修正したAIモデルに今回作成したRNN用の学習データを学習させた際の学習曲線を下記に示します。

参考までに、前回の記事での学習曲線を下記に示します。

前回の学習曲線と比べると、今回はVALIDATION ERRORの増加の勢いが半減していることが確認できます。
多少は、学習データと評価データの特徴を近づけることができたのかもしれません。
続いて、今回のAIモデルでの評価結果に対する混同行列を下記に示します。
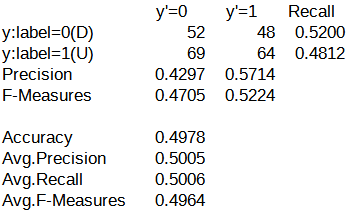
VALIDATION ERRORの増加の勢いが半減したとはいえ、右肩上がりの状況は変わらないため、混同行列のAccuracyが低いのは予想できました。
さて、今回の結果において、VALIDATION ERRORの増加の勢いが半減した点に着目し、AIモデルの構造をより単純化してみたらどうなるのか気になりました。
そこで、追加の検証として、2層Affineによる単純なAIモデルに今回の学習データおよび評価データを適用してみました。
2層Affineによる単純なAIモデルで追加検証
追加検証で使用したAIモデルの構造図を下記に示します。

2層Affineによる単純なAIモデルにRNN用に作成した学習データをそのまま使用し、学習させた際の学習曲線を下記に示します。

VALIDATION ERRORの右肩上がりはこれまでと同じですが、最大値が約0.850なので、これまでとはレベルが全く異なることが確認できます。
続いて、2層Affineによる単純なAIモデルでの評価結果に対する混同行列を下記に示します。

混同行列のAccuracyが61.37%と、意外にもこれまでにない良い結果が得られました。
y'=0の列では、label=0(D: 翌営業日株価がDown)と予測した回数が47で、label=1(U: 翌営業日株価がUp)と予測した回数の37より多くなっています。
また、y'=1の列では、label=0(D: 翌営業日株価がDown)と予測した回数が53で、label=1(U: 翌営業日株価がUp)と予測した回数の96より少なくなっています。
想定外ですが、良い結果です。
それにしても、VALIDATION ERRORの最低値はこれまでと変わらないレベルなのに、どうしてこのような結果となったのか理解できません。
気になってアレコレ確認してみたところ、一つ気になる設定がありました。
それは、学習データの設定においてシャッフルがノーチェックでした。
学習データのシャッフルに関して、Neural Network Consoleのマニュアルには、次のように記載されています。
Neural Network Consoleでは、与えられた学習データセットの先頭から順にデータを読みながら、コンフィグタブのバッチサイズで与えた数のデータ(Mini-Batch)を1つの単位としたミニバッチ勾配降下法によるパラメータの最適化を行います。
この際、効率的な最適化のためには1つのMini-Batchに含まれるデータはできるだけバリエーション豊かであることが理想的です。
データセットCSVファイルの各行はあらかじめシャッフルしておくことをお勧めします。
(中略)
シャッフルは、新しいEpochの学習が始まる度に100データ毎に作成されるキャッシュファイル単位、および1つのキャッシュファイル内の100データの間でそれぞれ行われます。
シャッフルの設定はデフォルトで有効なのですが、今回の検証で流用した2層Affineによる単純なAIモデルのプロジェクトファイルでは、シャッフルが無効の設定となっていました。
シャッフルの設定による影響を確認するため、シャッフルを有効にしてAIモデルの学習および評価を行いました。
以下に、シャッフルを有効とした場合の学習曲線と混同行列を示します。


2層Affineによる単純なAIモデルの混同行列(シャッフルあり)
VALIDATION ERRORに関しては、シャッフルの設定による影響は無さそうです。
しかし、混同行列に関しては、シャッフルを有効にするとAccuracyが61.37%から58.79%に低下しました。
Neural Network Consoleのマニュアルには、シャッフルを有効にする設定が推奨されていますが、この点をどう考えるか、迷うところです。
結果の考察
学習曲線のTRAINING ERRORを見ると、LSTM構造のAIモデルは学習データに最適化されすぎていると思われます。
一方で、2層Affine構造のAIモデルは学習データに対する最適化がそれほどなされていないため、VALIDATION ERRORも低くなっていると推測できます。
この理解が正しいとすると、日経平均株価の二値分類に対して、LSTMは高性能すぎるのかもしれず、単純な構造のAIモデルの方が適していると考えられます。
ただし、2層Affine構造のAIモデルにおいても、現状は、VALIDATION ERRORが右肩上がりの状態であるため、この問題を解決する必要があります。
これ以上単純な構造のAIモデルは思いつかないため、学習データに評価データの特徴を与える方法を検討するのが良いと考えます。
今後の課題
過学習について調べていたときにTensorFlowのウェブサイトを見つけました。
モデルのトレーニングをやりすぎると、モデルは過学習を始め、トレーニング用データの中のパターンで、テストデータには一般的ではないパターンを学習します。
そのため、過学習と学習不足の中間を目指す必要があります。
ふと思ったのですが、私が使用している学習データは約12900行(営業日)、評価データは約235行(営業日)です。
ちょっと学習データが多すぎるのではないかと気になりました。
そう言えば、キノコードさんの動画(14:25辺り)では、学習データが2018年1月1日~2020年12月31日まで、評価データが2021年1月1日以降となっていました。
1カ月を20営業日とすると、1年分で240行程度なので、3年分だと720行程度です。
学習データの約12900行は多すぎると思われるため、学習データを減らしてみようと思います。
どの程度減らすのが良いのか、また、どのデータを使用するのが良いのかは分からないので、次回はこの辺りを検討したいと思います。
また、どのAIモデルを使用すべきかも悩ましいところですが、先ずは2層Affine構造のAIモデルで結果を確認したいと思います。
AIモデルのデータについて
今回作成したAIモデルのデータは、Googleドライブにて共有しています。
URL: https://drive.google.com/drive/folders/1PVA4paoYeTIsMqiqzy-ReyFUNaOEffNV?usp=drive_link
N225_LSTM_SMA-BB-MACD_2Days_Std.sdcproj
Neural Network Console用のプロジェクトファイル(LSTM構造)
N225_2Affine_SMA-BB-MACD_2Days_Std.sdcproj
Neural Network Console用のプロジェクトファイル(2層Affine構造)
この記事が気に入ったらサポートをしてみませんか?