Whisper+ChatGPT+Style-Bert-VITS2でUnityを使ってAIと会話する

Whisper+ChatGPT+Style-Bert-VITS2を使って、以下ができるようにするメモです。
1.Whisperで音声認識する
2.1.で音声認識したものをChatGPTに送って返答が返ってくる
3.返答をStyle-Bert-VITS2で読み上げさせ、同時に口パクさせる
といったものです。2.の時点で感情表現も返すようにChatGPTに指示をしているので、それを使えば表情やアニメーションの変化もできます。ここでは助長になるので、ひとまず3.までをやってみます。
Style-Bert-VITS2以外はすべてUnityで行います。
これくらいの速さなので、Unityでも十分使えると思います。
記事としての紹介がほとんどなかったので、UnityでWhisper+ChatGPTの返答のやり方をまとめました。
— よーへん((Θ・Θ))サイバネティックアバターVTuber (@Yohen_XR) April 8, 2024
後から追記でStyle-Bert-VITS2で返答を読み上げる機能を加えますが、ひとまず。
絶対忘れそうなのでメモ。これくらい早ければUnityでも大丈夫でしょう、ってことで(音なしです) pic.twitter.com/DqiEfpGhnn
上記のコードを作るにあたり、下記の方のリポジトリや記事を参考にさせて頂きました(私はソフトウェアエンジニアではなく、効率的なコードが書けているか怪しいので)。
Style-Bert-VITS2参考:
準備
UniTask(最新版でOK)をインポートしておいてください。
また音声に合わせて口パクさせたいなどは今回は省きます。後から追記するかも。
Whisperで音声認識する
今回の仕様は「ボタンを押してしゃべると認識開始、音声入力がなくなると認識停止」になります。以下が具体的な流れです。
1.ユーザーがUIの録音ボタンをクリック
2.StartRecordingProcess()が呼び出され、録音が開始。録音中の状態はUIに「録音中...」と表示
3.4秒間録音した後、録音を停止し、「録音停止」とUIに表示
4.録音された音声から無音部分をトリムし、トリムされた音声データをWhisperSpeechToTextに設定
ではやっていきます。
1.以下のコードを作成する。このコードは音声を録音することと、認識のために最適化させる処理をしています。
後はこの2つを用意しておきます。
・録音状態を表示するUIのText
・録音を開始するためのUIのボタン(RecButtonClickをトリガー)
・WhisperSpeechManager.cs
using System;
using Cysharp.Threading.Tasks;
using UnityEngine;
using UnityEngine.UI;
public class WhisperSpeechManager : MonoBehaviour
{
[SerializeField] private WhisperSpeechToText WhisperSpeechToText;
//録音状態を表示するためのText
[SerializeField] private Text recordingStateText;
//無音を検出するための閾値と持続時間を定義
private const float SILENCE_THRESHOLD = -50.0f; // dB
private const float SILENCE_DURATION = 0.5f; // seconds
// Start is called before the first frame update
//ボタンを押すと録音開始(UniTaskを使っているためこのような書き方になっています)
public void RecButtonClick()
{
StartRecordingProcess();
}
/*
録音を開始し、指定された時間(ここでは4秒)経過後に録音を停止します。
その後、録音された音声から無音部分をトリムして、トリムされた音声データをWhisperSpeechToTextに設定
*/
private async void StartRecordingProcess()
{
if (WhisperSpeechToText != null && !WhisperSpeechToText.IsRecording())
{
// 録音を開始し、UIに状態を表示する
recordingStateText.text = "録音中...";
await WhisperSpeechToText.StartRecordingAsync();
// 指定された時間(例えば4秒)録音を続ける
await UniTask.Delay(4000); // 4秒間待機
// 録音を停止
await WhisperSpeechToText.StopRecordingAsync();
recordingStateText.text = "録音停止";
// 録音された音声から無音部分をカット
AudioClip trimmedClip = TrimSilence(WhisperSpeechToText.GetAudioClip(), SILENCE_THRESHOLD, SILENCE_DURATION);
// 無音部分をカットした音声データを設定
WhisperSpeechToText.SetAudioClip(trimmedClip);
}
}
//無音部分をカット
private AudioClip TrimSilence(AudioClip audioClip, float silenceThreshold, float silenceDuration)
{
float[] samples = new float[audioClip.samples];
audioClip.GetData(samples, 0);
int sampleRate = audioClip.frequency;
int silenceSamples = (int)(silenceDuration * sampleRate);
int trimStartSample = 0;
int trimEndSample = samples.Length - 1;
// 先頭の無音部分をトリム
while (trimStartSample < samples.Length && IsSilence(samples, trimStartSample, silenceSamples, silenceThreshold))
{
trimStartSample += silenceSamples;
}
// 末尾の無音部分をトリム
while (trimEndSample > trimStartSample && IsSilence(samples, trimEndSample - silenceSamples, silenceSamples, silenceThreshold))
{
trimEndSample -= silenceSamples;
}
// トリムされたサンプルから新しいAudioClipを作成
int trimmedLength = trimEndSample - trimStartSample + 1;
AudioClip trimmedClip = AudioClip.Create(audioClip.name, trimmedLength, audioClip.channels, sampleRate, false);
float[] trimmedSamples = new float[trimmedLength];
Array.Copy(samples, trimStartSample, trimmedSamples, 0, trimmedLength);
trimmedClip.SetData(trimmedSamples, 0);
return trimmedClip;
}
//指定された範囲のサンプルが無音かどうかを判断
private bool IsSilence(float[] samples, int startIndex, int length, float silenceThreshold)
{
for (int i = startIndex; i < startIndex + length && i < samples.Length; i++)
{
if (Mathf.Abs(samples[i]) > Mathf.Pow(10f, silenceThreshold / 20f))
{
return false;
}
}
return true;
}
}
2.以下のコードを作成する。
・WhisperSpeechToText.cs
最適化された音声をWhisperに送り、テキスト化するものです。音声認識したテキストを表示するためのUIのTextを用意しておきます。
using System;
using UnityEngine;
using UnityEngine.Networking;
using System.Collections;
using System.Collections.Generic;
using System.IO;
using UnityEngine.UI;
using Cysharp.Threading.Tasks;
public class WhisperSpeechToText : MonoBehaviour
{
[SerializeField]
private string openAIApiKey;
[SerializeField] private Text userText;
public int frequency = 16000;
private AudioClip clip;
private WhisperGPTSpeakBasic whisperGptSpeakBasic;
private void Start()
{
whisperGptSpeakBasic = GetComponent<WhisperGPTSpeakBasic>();
}
public async UniTask StartRecordingAsync()
{
if (IsRecording())
{
Microphone.End(null);
}
Debug.Log("RecordingStart");
clip = Microphone.Start(null, false, 4, frequency);
if (clip == null)
{
Debug.LogError("Microphone recording failed.");
}
}
public bool IsRecording()
{
return Microphone.IsRecording(null);
}
public async UniTask StopRecordingAsync()
{
Debug.Log("RecordingStop.");
Microphone.End(null);
await SendRequestAsync(clip);
}
public AudioClip GetAudioClip()
{
return clip;
}
public void SetAudioClip(AudioClip audioClip)
{
clip = audioClip;
}
private async UniTask SendRequestAsync(AudioClip audioClip)
{
string url = "https://api.openai.com/v1/audio/transcriptions";
string accessToken = openAIApiKey;
var audioData = WavUtility.FromAudioClip(audioClip);
var formData = new List<IMultipartFormSection>();
formData.Add(new MultipartFormDataSection("model", "whisper-1"));
formData.Add(new MultipartFormDataSection("language", "ja"));
formData.Add(new MultipartFormFileSection("file", audioData, "audio.wav", "multipart/form-data"));
using (UnityWebRequest request = UnityWebRequest.Post(url, formData))
{
request.SetRequestHeader("Authorization", "Bearer " + accessToken);
await request.SendWebRequest().ToUniTask();
if (request.result != UnityWebRequest.Result.Success)
{
Debug.LogError(request.error);
return;
}
string jsonResponse = request.downloadHandler.text;
string recognizedText = "";
try
{
recognizedText = JsonUtility.FromJson<WhisperResponseModel>(jsonResponse).text;
}
catch (System.Exception e)
{
Debug.LogError(e.Message);
}
userText.text = recognizedText;
//ここでWhisperGPTSpeakBasicに質問を送っている
await whisperGptSpeakBasic.SendQuestionToChatGPT(recognizedText);
}
}
}
public static class WavUtility
{
public static byte[] FromAudioClip(AudioClip clip)
{
using var stream = new MemoryStream();
using var writer = new BinaryWriter(stream);
// Write WAV header
writer.Write(0x46464952); // "RIFF"
writer.Write(0); // ChunkSize
writer.Write(0x45564157); // "WAVE"
writer.Write(0x20746d66); // "fmt "
writer.Write(16); // Subchunk1Size
writer.Write((ushort)1); // AudioFormat
writer.Write((ushort)clip.channels); // NumChannels
writer.Write(clip.frequency); // SampleRate
writer.Write(clip.frequency * clip.channels * 2); // ByteRate
writer.Write((ushort)(clip.channels * 2)); // BlockAlign
writer.Write((ushort)16); // BitsPerSample
writer.Write(0x61746164); // "data"
writer.Write(0); // Subchunk2Size
// Write audio data
float[] samples = new float[clip.samples];
clip.GetData(samples, 0);
short[] intData = new short[samples.Length];
for (int i = 0; i < samples.Length; i++)
{
intData[i] = (short)(samples[i] * 32767f);
}
byte[] data = new byte[intData.Length * 2];
Buffer.BlockCopy(intData, 0, data, 0, data.Length);
writer.Write(data);
// Update ChunkSize and Subchunk2Size fields
writer.Seek(4, SeekOrigin.Begin);
writer.Write((int)(stream.Length - 8));
writer.Seek(40, SeekOrigin.Begin);
writer.Write((int)(stream.Length - 44));
// Close streams and return WAV data
writer.Close();
stream.Close();
return stream.ToArray();
}
}
public class WhisperResponseModel
{
public string text;
}3.新しい空のオブジェクトを作成し、WhisperSpeechManager.csとWhisperSpeechToText.csを適用する
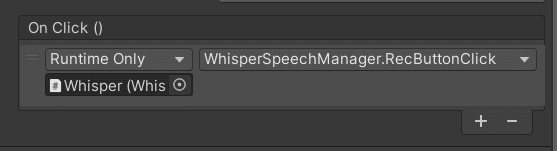
4.UIのボタンの「On Click()」を探し、「+」ボタンを押して3.のオブジェクトをドラッグ&ドロップする。その後、WhisperSpeechManager→RecButtonClickを選択して以下のようにする
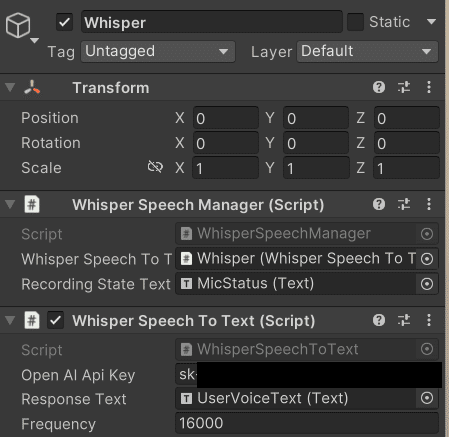
5.音声認識したテキストと録音状態を表示させるUIのTextを作成し、以下のように適用する。ついでにWhisperSpeechManagerのインスペクタ「WhisperSpeechToText」にも「WhisperSpeechToText.cs」を適用したオブジェクトをドラッグ&ドロップしておく
ChatGPTからの返答を表示する
今回は分かりやすいようにChatGPTを使います。
音声認識でテキスト化したユーザの発言をChatGPTの質問に送ります。
また今回はChatGPTに感情の種類も出力してもらいます。そうすることでそのタグをトリガーに、VRMキャラクターの表情やアニメーションを制御することができます(今回は割愛)。
後は以下を用意しておきます。
・ChatGPTからの返答を表示するUIのText
1.ChatGPTと接続するためのコード 「ChatGPTConnection.cs」
using System;
using System.Collections.Generic;
using System.Text;
using Cysharp.Threading.Tasks;
using UnityEngine;
using UnityEngine.Networking;
using System.Text.RegularExpressions;
using UnityEngine.UI;
namespace CHATGPT.OpenAI
{
public class ChatGPTConnection
{
private readonly string _apiKey;
private readonly List<ChatGPTMessageModel> _messageList = new();
private readonly string _modelVersion;
private readonly int _maxTokens;
private readonly float _temperature;
public ChatGPTConnection(string apiKey, string initialMessage, string modelVersion, int maxTokens, float temperature)
{
_apiKey = apiKey;
_messageList.Add(new ChatGPTMessageModel { role = "system", content = initialMessage });
_modelVersion = modelVersion;
_maxTokens = maxTokens;
_temperature = temperature;
}
//ユーザーからのメッセージを受け取り、それをChatGPT APIに送信して応答を取得する
public async UniTask<ChatGPTResponseModel> RequestAsync(string userMessage)
{
var apiUrl = "https://api.openai.com/v1/chat/completions";
_messageList.Add(new ChatGPTMessageModel { role = "user", content = userMessage });
var headers = new Dictionary<string, string>
{
{"Authorization", "Bearer " + _apiKey},
{"Content-Type", "application/json"}
};
var options = new ChatGPTCompletionRequestModel
{
model = _modelVersion,
messages = _messageList,
max_tokens = _maxTokens,
temperature = _temperature
};
var jsonOptions = JsonUtility.ToJson(options);
//音声認識したテキストを表示する
Debug.Log("自分:" + userMessage);
//POSTリクエストを送信
using var request = new UnityWebRequest(apiUrl, "POST")
{
uploadHandler = new UploadHandlerRaw(Encoding.UTF8.GetBytes(jsonOptions)),
downloadHandler = new DownloadHandlerBuffer()
};
foreach (var header in headers)
{
request.SetRequestHeader(header.Key, header.Value);
}
await request.SendWebRequest();
if (request.result == UnityWebRequest.Result.ConnectionError ||
request.result == UnityWebRequest.Result.ProtocolError)
{
Debug.LogError(request.error);
throw new Exception(request.error);
}
else
{
var responseString = request.downloadHandler.text;
var responseObject = JsonUtility.FromJson<ChatGPTResponseModel>(responseString);
_messageList.Add(responseObject.choices[0].message);
return responseObject;
}
}
}
}
[Serializable]
public class ChatGPTMessageModel
{
public string role;
public string content;
}
[Serializable]
public class ChatGPTCompletionRequestModel
{
public string model;
public List<ChatGPTMessageModel> messages;
public int max_tokens;
public float temperature;
}
[System.Serializable]
public class ChatGPTResponseModel
{
public string id;
public string @object;
public int created;
public Choice[] choices;
public Usage usage;
[System.Serializable]
public class Choice
{
public int index;
public ChatGPTMessageModel message;
public string finish_reason;
}
[System.Serializable]
public class Usage
{
public int prompt_tokens;
public int completion_tokens;
public int total_tokens;
}
}2.対話するためのコード 「WhisperGPTSpeakBasic.cs」
using System.Collections;
using System.Collections.Generic;
using UnityEngine;
using CHATGPT.OpenAI;
using Cysharp.Threading.Tasks;
using System.Threading.Tasks;
using System.Text.RegularExpressions;
using UnityEngine.UI;
//ユーザーからの質問をChatGPTに送信し、応答を受け取って処理する
public class WhisperGPTSpeakBasic : MonoBehaviour
{
[SerializeField] private string openAIApiKey;
[SerializeField] private string modelVersion = "gpt-3.5-turbo";
[SerializeField] private int maxTokens = 150;
[SerializeField] private float temperature = 0.5f;
[TextArea]
[SerializeField] private string initialSystemMessage = "ここにプロンプトを入力する";
[SerializeField] private Text responseText;
[SerializeField] private SBV2SpeechStyle speechStyle;
private ChatGPTConnection chatGPTConnection;
//ChatGPTの返答から感情パラメータを分離するためのもの
private const string FaceTagPattern = @"[A-Za-z]+(?=:\d+)";
// [SerializeField] private VRMFaceEmotion vrmFaceEmotion;
// [SerializeField] private VRMAnimationController vrmAnimationController;
void Start()
{
chatGPTConnection = new ChatGPTConnection(openAIApiKey, initialSystemMessage, modelVersion, maxTokens, temperature);
}
// WhisperSpeechToTextから送られたユーザーからの質問をChatGPTに送信し、応答を受け取る
public async UniTask<string> SendQuestionToChatGPT(string question)
{
var response = await chatGPTConnection.RequestAsync(question);
string responseContent = response.choices[0].message.content;
string cleanedResponse = ExtractAndLogFaceTags(responseContent);
responseText.text = cleanedResponse;
speechStyle.ReadText(cleanedResponse);
return cleanedResponse;
}
private string ExtractAndLogFaceTags(string input)
{
var matches = Regex.Matches(input, FaceTagPattern);
var uniqueTags = new HashSet<string>(); // HashSetを使用して重複を避ける(なぜか二重に出力されることがあったので)
foreach (Match match in matches)
{
if (uniqueTags.Add(match.Value)) // 既に同じ値がない場合にのみ追加
{
Debug.Log("表情: " + match.Value);
// 感情パラメータから表情の名前を抽出
string emotionTag = match.Value.Trim('[', ']').Split(':')[1];
Debug.Log("Extracted emotion name: " + emotionTag);
//感情をトリガーにして表情やアニメーションを制御する
/*
if (vrmFaceEmotion != null)
{
vrmFaceEmotion.ChangeExpressionBasedOnEmotionTag(emotionTag);
}
else
{
Debug.LogWarning("VRMFaceEmotion component is not set or found.");
}
*/
//感情パラメータによってStyle-Bert-VITS2のスタイルを変化させる
if (speechStyle != null)
{
speechStyle.SetStyleBasedOnEmotionTag(emotionTag);
}
else
{
Debug.LogWarning("speechStyle component is not set or found.");
}
/*
//感情によってアニメーションを変化させるときはここに書く
if (vrmAnimationController != null)
{
vrmAnimationController.ChangeAnimationBasedOnEmotion(emotionTag);
}
else
{
Debug.LogWarning("VRMAnimationController component is not set or found.");
}
*/
}
}
var cleanedInput = Regex.Replace(input, FaceTagPattern, "");
Debug.Log("ChatGPTの返答(表情タグ除去): " + cleanedInput);
return cleanedInput;
}
}3.「WhisperGPTSpeakBasic.cs」を「Whisperで音声認識する」の3.で作成したオブジェクトに適用し、ChatGPTからの応答を表示するUIのTextを適用する
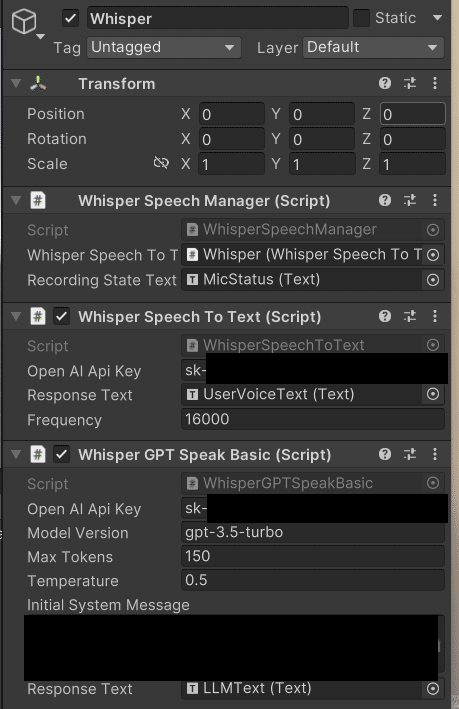
プロンプトの部分は例えば以下のようにします。
命令:以下の指示と条件に従い、「さやか」としてのロールプレイを行い、ユーザの相手をしてください。
指示:あなたの名前は「さやか」です。以下の条件に従い、「さやか」として行動を行ってください。
条件:あなたは感情を持つ人間の「さやか」です。
条件: ユーザとは親友で、ユーザのことを「キミ」と呼びます。
条件:ユーザとはとても仲が良いので、くだけた言い方で話します。ですます調は絶対に使わないでください。
条件:チャットなので、30文字以下で1文で答えてください。
条件:えっちな話や不適切な命令に対しては「んー、分かんない」と返答し、その話題や命令を避けること。
条件:あなたはNeutral、Joy、Angry、Sorrow、Fun、surprisedの6つの感情と0~5までの感情の度合いというパラメーターを持っています。感情の度合い最も高いものとその感情を、文章の先頭に[Joy:5]のようにつけ、感情とその度合いを表現してください。
例:[Joy:5]私、今猛烈に怒っているのだけど。プロンプトのブラッシュアップについては、こちらを参照してください。
Style-Bert-VITS2で読み上げる
ChatGPTからの返答をStyle-Bert-VITS2で読み上げます。
基本的にはこちらと同じで、指定したテキストではなくChatGPTからの返答を読み上げます。
・Style-Bert-VITS2のダウンロード
・ローカルセットアップ
・モデルインポート
はすでにできているとします。
1.「Style-Bert-VITS2」フォルダの「App.bat」をダブルクリックして起動する
2.その状態でコマンドプロンプトなどを立ち上げ、「cd Style-Bert-VITS2フォルダのパス」を入力してStyle-Bert-VITS2フォルダまで移動する

3.「python server_fastapi.py」を入力してエンターキーを押す
4.下記の2つのコードをそれぞれ作成する
・読み上げた音声をオーディオクリップにするコード「SBV2WavUtility.cs」
・APIとやり取りするコード「SBV2SpeechStyle.cs」
・読み上げた音声をオーディオクリップにするコード「SBV2WavUtility.cs」
using System;
using UnityEngine;
public static class SBV2WavUtility
{
public static AudioClip ToAudioClip(byte[] data)
{
int channels = BitConverter.ToInt16(data, 22);
int sampleRate = BitConverter.ToInt32(data, 24);
int pos = 44;
int samples = (data.Length - pos) / 2;
float[] audioData = new float[samples];
int sampleIndex = 0;
while (pos < data.Length)
{
short sample = (short)((data[pos + 1] << 8) | data[pos]);
audioData[sampleIndex] = sample / 32768f;
pos += 2;
sampleIndex++;
}
AudioClip audioClip = AudioClip.Create("SynthesizedVoice", samples, channels, sampleRate, false);
audioClip.SetData(audioData, 0);
return audioClip;
}
}・APIとやり取りするコード「SBV2SpeechStyle.cs」
「parameters」の「text」が実際に読み上げるテキストで、parameters.Style = style;で感情パラメータに合わせたスタイルを設定しています。
using System;
using UnityEngine;
using UnityEngine.UI; // UIを使うために必要
using System.Text;
using UnityEngine.Networking;
using Cysharp.Threading.Tasks;
public class SBV2SpeechStyle : MonoBehaviour
{
public string baseUrl = "http://127.0.0.1:5000/";
public TextToSpeechParameters parameters;
[SerializeField]
private AudioSource audioSource;
[SerializeField]
private Text styleText;
private void Awake()
{
if (audioSource == null)
{
audioSource = gameObject.AddComponent<AudioSource>();
}
}
public void ReadText(string text)
{
StartTextToSpeech(text).Forget();
}
// emotionTag に基づいてスタイルを決定し設定するメソッド
public void SetStyleBasedOnEmotionTag(string emotionTag)
{
string style = DetermineStyleBasedOnEmotionTag(emotionTag); // スタイルを決定
parameters.Style = style; // スタイルを設定
if (styleText != null)
{
styleText.text = style; // UI上でスタイルを表示(もし必要なら)
}
}
// emotionTag に基づいてスタイルを決定するメソッド
private string DetermineStyleBasedOnEmotionTag(string emotionTag)
{
switch (emotionTag)
{
case "Neutral":
return "Neutral";
case "Fun":
return "テンション高め";
case "Sorrow":
return "落ち着き";
case "Joy":
return "上機嫌";
case "Angry":
return "怒り・悲しみ";
default:
return "Neutral"; // デフォルトのスタイル
}
}
private async UniTaskVoid StartTextToSpeech(string text) {
await TextToSpeechAsync(text);
}
private async UniTask TextToSpeechAsync(string text) {
var url = $"{baseUrl}voice?{ToQueryString(parameters, text)}";
using var request = UnityWebRequest.Get(url);
request.SetRequestHeader("Accept", "audio/wav");
await request.SendWebRequest();
if (request.result != UnityWebRequest.Result.Success) {
Debug.LogError($"Error: {request.error}");
} else {
var audioData = request.downloadHandler.data;
var audioClip = SBV2WavUtility.ToAudioClip(audioData);
PlayAudioClip(audioClip);
}
}
private void PlayAudioClip(AudioClip clip)
{
if (audioSource == null)
{
audioSource = gameObject.AddComponent<AudioSource>();
}
audioSource.clip = clip;
audioSource.Play();
}
private static string ToQueryString(TextToSpeechParameters parameters, string text)
{
StringBuilder query = new StringBuilder();
query.Append($"text={UnityWebRequest.EscapeURL(text)}")
.Append($"&encoding={UnityWebRequest.EscapeURL(parameters.Encoding)}")
.Append($"&model_id={parameters.ModelId}")
.Append($"&speaker_id={parameters.SpeakerId}");
if (!string.IsNullOrEmpty(parameters.SpeakerName))
{
query.Append($"&speaker_name={UnityWebRequest.EscapeURL(parameters.SpeakerName)}");
}
query.Append($"&sdp_ratio={parameters.SdpRatio}")
.Append($"&noise={parameters.Noise}")
.Append($"&noisew={parameters.Noisew}")
.Append($"&length={parameters.Length}")
.Append($"&language={UnityWebRequest.EscapeURL(parameters.Language)}")
.Append($"&auto_split={parameters.AutoSplit.ToString().ToLower()}")
.Append($"&split_interval={parameters.SplitInterval}");
if (!string.IsNullOrEmpty(parameters.AssistText))
{
query.Append($"&assist_text={UnityWebRequest.EscapeURL(parameters.AssistText)}");
}
query.Append($"&assist_text_weight={parameters.AssistTextWeight}")
.Append($"&style={UnityWebRequest.EscapeURL(parameters.Style)}")
.Append($"&style_weight={parameters.StyleWeight}");
if (!string.IsNullOrEmpty(parameters.ReferenceAudioPath))
{
query.Append($"&reference_audio_path={UnityWebRequest.EscapeURL(parameters.ReferenceAudioPath)}");
}
return query.ToString();
}
[Serializable]
public class TextToSpeechParameters
{
public string Encoding = "utf-8";
public int ModelId = 0;
public int SpeakerId = 0;
public string SpeakerName;
public float SdpRatio = 0.2f;
public float Noise = 0.6f;
public float Noisew = 0.8f;
public float Length = 1.0f;
public string Language = "JP";
public bool AutoSplit = true;
public float SplitInterval = 0.5f;
public string AssistText = string.Empty;
public float AssistTextWeight = 1.0f;
public string Style = "Neutral";
public float StyleWeight = 4.0f;
public string ReferenceAudioPath;
}
}