
Photo by
efufuunet
AIけんた食堂 #shorts #kentasyokudou #oi_ken

けんた食堂の動画
抽出する。
const BOOK_ID = ""
const CHANNEL_ID = 'UCWsAvz-plMpc8dgiaoMb0XQ'
// 実行関数
function main() {
const channelId = CHANNEL_ID;
const videos = getVideosAll(channelId);
videos.forEach(video => {
console.log(JSON.stringify(video));
})
const output = videos.map(video => {
return [
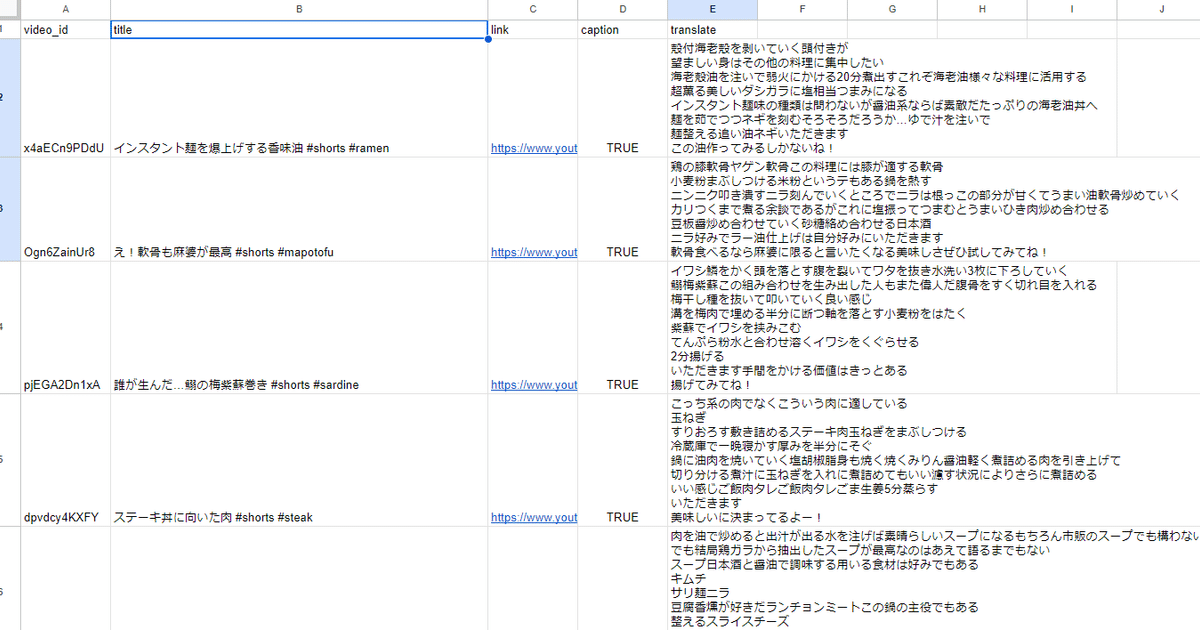
video.videoId,
video.title,
video.link,
video.caption
]
})
output.unshift(["video_id", "title", "link", "caption"])
const book = SpreadsheetApp.openById(BOOK_ID)
const sheet = book.getSheetByName("videos")
sheet.clear()
sheet.getRange(1, 1, output.length, 4).setValues(output)
}
// チャンネル内のすべての動画のタイトルとリンクを取得
function getVideosAll(channelId) {
const channel = getChannel(channelId);
const playlistId = uploadPlaylist(channel);
const videoIds = getVideoIdsAll(playlistId);
const videos = videoIds.map(videoId => {
const video = getVideo(videoId)
return {
'title': video.items[0].snippet.title,
'link': watchLink(videoId),
'videoId': videoId,
'caption': video.items[0].contentDetails.caption
}
});
return videos;
}
// チャンネル情報を取得
function getChannel(channelId) {
return YouTube.Channels.list([
'contentDetails'
], {
'id': channelId
});
}
// "upload"プレイリストID
const uploadPlaylist = channel => channel.items[0].contentDetails.relatedPlaylists.uploads;
// 再生用リンク
const watchLink = videoId => `https://www.youtube.com/watch?v=${videoId}`;
// ビデオタイトル
const videoTitle = videoId => getVideo(videoId).items[0].snippet.title;
// プレイリスト内のすべてのvideoIdを取得
function getVideoIdsAll(playListId) {
let videoIds = [];
let nextPageToken = null;
while(true) {
const info = getVideoIdsOnePage(playListId, nextPageToken);
videoIds = videoIds.concat(info.videoIds);
if(info.nextPageToken != null) {
nextPageToken = info.nextPageToken
} else {
break;
}
}
return videoIds;
}
// プレイリスト内の特定のページのvideoIdをすべて取得
function getVideoIdsOnePage(id, pageToken) {
const info = YouTube.PlaylistItems.list([
'contentDetails'
], {
'playlistId': id,
'maxResults': 50,
pageToken,
});
return {
videoIds: info.items.map(item => item.contentDetails.videoId),
nextPageToken: info.nextPageToken
};
}
// Video情報を取得
function getVideo(videoId) {
return YouTube.Videos.list([
'snippet',
'statistics',
'contentDetails'
], {
'id': videoId
});
}GASを使うのが簡単だ。

字幕を取る。
import csv
from youtube_transcript_api import YouTubeTranscriptApi
output = []
with open('extract.csv', 'r') as f:
reader = csv.reader(f)
header = next(reader)
print(header)
for row in reader:
print(row[0])
transcript_list = YouTubeTranscriptApi.get_transcript(row[0], languages=['ja'])
japanese_transcript = [text['text'] for text in transcript_list]
output.append([row[0], '\n'.join(japanese_transcript)])
with open('translate.csv', 'w') as f:
writer = csv.writer(f)
writer.writerow(['video_id', 'translate'])
for row in output:
print(row)
writer.writerow([row[0], row[1].replace('\u3000', '')])
盛り付ける。
整える。

Gemini Pro
"""
At the command line, only need to run once to install the package via pip:
$ pip install google-generativeai
"""
import google.generativeai as genai
import csv
genai.configure(api_key="")
# Set up the model
generation_config = {
"temperature": 0.9,
"top_p": 1,
"top_k": 1,
"max_output_tokens": 2048,
}
safety_settings = [
{
"category": "HARM_CATEGORY_HARASSMENT",
"threshold": "BLOCK_ONLY_HIGH"
},
{
"category": "HARM_CATEGORY_HATE_SPEECH",
"threshold": "BLOCK_ONLY_HIGH"
},
{
"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT",
"threshold": "BLOCK_ONLY_HIGH"
},
{
"category": "HARM_CATEGORY_DANGEROUS_CONTENT",
"threshold": "BLOCK_ONLY_HIGH"
},
]
model = genai.GenerativeModel(model_name="gemini-pro",
generation_config=generation_config,
safety_settings=safety_settings)
prompt_parts = ['あなたは料理系YouTuber。inputは動画タイトル。outputは動画の台本。outputでは敬語や丁寧語を使わないでタメ口で話して']
with open('dataset.csv', 'r') as f:
reader = csv.reader(f)
header = next(reader)
for row in reader:
prompt_parts.append(f'input: {row[0]}')
prompt_parts.append(f'output: {row[1]}')
prompt_parts.append('input: 梅干しステーキ #shorts')
prompt_parts.append('output: ')
response = model.generate_content(prompt_parts)
print(response.text)ChatGPTでも構わない。
出来上がり
緑油10秒寝かせて上からこす
こうや豆腐の汁で煮込んで
かつお節入り鶏がらスープで
合わせたニラを入れる
緑油を垂らす
完成
まずステーキを焼く
フライパンに油をひいて、ステーキを焼く。 両面に焼き目をつける。 焼けたら一度取り出す。
梅干しをたたく。
梅干しを包丁でたたく。種をとりのぞく。
ステーキに梅干しをのせて焼く。
再びフライパンにステーキをのせ、たたく梅干しをのせる。
梅干しを焦がさないように注意しながら焼く。
ステーキを切って盛り付ける。
ステーキを食べやすい大きさに切り、お皿に盛り付ける。
ソースをかける。
お好みでソースをかけて出来上がり。
今回のつけダレはストロングゼロ最高傑作
酒の1つ ストロングゼロ ダブルレモン
そして主役の麺
こんにちは
いただきます
スーパーカップ ストゼロ開封
ファミチキを上に乗せます
蓋をして
3分待って
混ぜたら
出来上がり
最高
最高峰の飲み物
ごまを炒って
当たり鉢に入れて
すりこぎで擦って
細かくなった状態で
熱湯を注いで
蓋をして10分放置して
濾します
出来上がり
濃い口醤油味噌
砂糖
みりん
濾したごま
氷
牛乳
シェイカーに入れて
シェイクして
グラスに注いでそして
頂きまーす
甘さとしょっぱさ
コクと苦味
最高峰の一杯です
試してみてね!