
Pythonのcsvファイル読み込みが1分30秒かかっていたものが1秒未満でできます。 DASK pickle (Pythonコードあり)

ーーーーーーーーーーー2021/07/28 追記ーーーーーーーーーーー
Pythonの一部仕様変更などでうまく動いていなかった部分を新しいサイトでは修正しました。
今後適宜修正や改修を行おうとは思いますが、すべてを改修できるわけではないことはご承知おきください。
2021/07/28時点では動いていることは確認しております。
今後こちらに移行します。
ーーーーーーーーーーー2021/07/28 追記ーーーーーーーーーーー
この記事を読むことで、csvファイル読み込みで1分30秒かかっていたものが1秒かからずにデータを読み込めるようになります。大幅な速度・パフォーマンスの向上が期待できます。以下がその結果です。
読み込み時間 Wall time: 1 min 28 sec
読み込み時間 Wall time: 144 ms
今まで、Python 遅い と思っていたものが、こんなに早くなる と驚くことになるのではないでしょうか。使い方によってはすごく速くなります。
------------------------------------告知枠------------------------------------------
Pythonで米国株を中心とした資産運用モデルについての記事を集めました。
------------------------------------告知枠------------------------------------------
内容
Pythonでの作業の効率化の小技で、並列DataFrame処理で有名なDASKとオブジェクト保存のpickleを紹介します。以下の記事で、初心者、ビギナーの方が、Pythonを使ってcsvファイルの読み込みの速度・パフォーマンスを改善・向上することができます。
いわゆる時間のかかる前処理を”爆速化・高速化”し、分析の方により注力し、開発効率をあげるための小技の紹介になります。
今回の処理速度の計測には %%time というJupyter Notebook マジックコマンドを利用しています。
まず、DASKですが、基本的には並列処理・分散処理を行う分析ライブラリですが、私はcsvファイルの読み込みに使っています。調べるとメモリの使用量を抑えながら並列処理できるようなのですが、頻繁に使って、かつ時間がかかっているデータロードを高速化するために使っています。
解析にはいつも通りGoogle Colaboratoryのpythonを使います。
Chromeブラウザ上で無料で、簡単に解析を行うことができますので、ありがたいですね。お勧めのツールです。
では、実際の使用例を以下に示します。まず、今回使うファイルをGoogle Colaboratoryにアップロードします。
簡単なのは左側のタブの中にあるファイルを選んでいただき、アップロードのボタンの押すと、アップロードするファイルを選べますので、そこで読み込み等に使いたいファイルを選択します。今回は TEXT_file.csv というファイルを私はアップロードしました。
このファイルの状況をまず、確認します。
import os
print(os.path.getsize('./TEXT_file.csv'))32765645
約32MBのファイルを読み込んでみたいと思います。
%%time
import pandas as pd
input_file_csv = "./TEXT_file.csv"
df_csv=pd.read_csv(input_file_csv, encoding='utf-8',index_col=0,parse_dates=True)
display(df_csv.tail())
print(df_csv.info())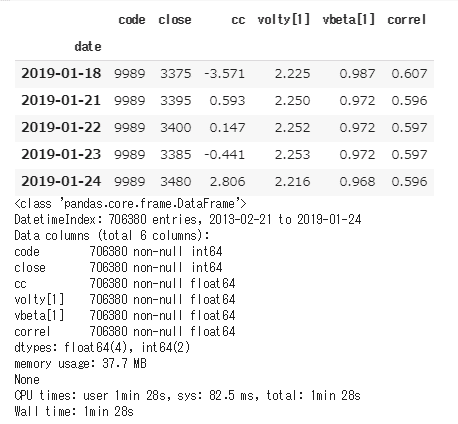
読み込み時間 Wall time: 1 min 28 sec
約70万行のデータで、読み込むのに1分30秒程度かかっています。
このようなファイルがたくさんあったり、毎回この作業をするのはちょっと、、というような場合があります。その時こそ、DASKです。
DASKのコードは以下の通りです。
%%time
import dask.dataframe as ddf
import dask.multiprocessing
df_dask = ddf.read_csv(input_file_csv,parse_dates=True)
df_dask = df_dask.compute()
display(df_dask.tail())
print(df_dask.info())
読み込み時間 Wall time: 825 ms
同じファイルの読み込みに1秒かかりません。爆速化・高速化成功です。
これならもう少し大きなファイルでデータをもらうようなことがあっても、データの下準備や前処理ではなく、データ解析のほうに自分の時間が使えそうです。
さらに大きなファイルやデータの場合はpickleを使うと便利です。
たとえば、大きなデータを解析していて、翌日に同じところから始めたいと思うようなことがあります。折角時間をかけてデータロードしたDataFrameも明日の朝に再度データロードからやり直しかと思うとちょっと気が重いですよね、、でも、pickleがあれば大丈夫です。
使い方は簡単で、DataFrameをpicleファイルに保存して、それを使いたいときに読み込めばいいのです。使い方は以下の通りです。
import pickle
df_csv.to_pickle('./dataout_out.pickle')
print(os.path.getsize('./dataout_out.pickle'))39558443
約39MBのファイルにDataFrameの内容が書き出されます。明日の朝と思いながらそのファイルを読み込んでみましょう。
%%time
import pickle
with open('./dataout_out.pickle', mode='rb') as fp :
df_pickle = pickle.load(fp)
display(df_pickle.info())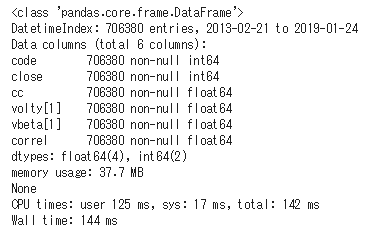
読み込み時間 Wall time: 144 ms
なんと、0.15秒です。通常のcvsファイルの読み込みから比べるとあっという間ですね。データの種類や構造・サイズによって変わるとは思いますが、効率の明らかな改善が見込まれる場合など、これを使わない手はないです。
二つのモジュールとももっといろいろな機能があるようですが、とりあえず、簡単に作業効率を上げられる小技でした。
このたびは、noteを購入していただき、大変ありがとうございました。
この記事が今後の投資活動において、お役に立つことを願っています。
この部分はどうなのか、ここを知りたいのだが、、というような希望があればご連絡いただければ幸いです。すべてにこたえられるかは分かりませんが、是非前向きに検討してみようと思います。
また、短い文でも構いませんので、感想などいただけるとモチベーションの向上、今後の改善への励みになりますので、是非ともよろしくお願いいたします。
最後まで読んでいただき、大変ありがとうございました。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
Pythonで資産運用モデルを作成する記事をまとめました。
Pythonを用いて、株価取得、チャート表示、株価分析、株価予測、株価の機械学習、ポートフォリオの構築、ポートフォリオの最適化、スクレイピングなどを行う記事を集めました。
もし興味を持っていただけるなら読んでみてください。
Pythonの機能を使った記事や、パフォーマンスの測定や、改善、チューニングといったものを集めた記事、ウェブアプリの作成の記事をまとめました。
もし興味を持っていただけるなら読んでみてください。
pickleに関してはこのサイトを参考にさせていただきました。ありがとうございます。
ここから先は
¥ 500
サポートしていただき大変ありがとうございます。 励みになります。