
【続】"忖度ゾーン" を考慮した簡易フレーミング評価の検討

このnoteは3部構成の真ん中、これの続きです。このnoteだけでも十分楽しめるかどうかはぼくの技術次第ですが、まだ読んでないよって方は先に前回分を参照して頂く方がよろしいかと思います。リンクを往復することになるので閲覧回数も増え(略)。
こんばんは。前回は「データが限定された状況でのフレーミング指標の算出」という問題設定を行い、これまでの指標の算出アプローチをレビューした上で今回使用するデータの問題点について議論しました。
3. アプローチの哲学を再考する
いわゆる忖度ゾーンの存在により、MLBで使用されているフレーミング評価指標が使えなくなってしまった一般人。じゃあどうするかということで「NPBもとっととトラッキングデータを公開しろ」と叫んでもいいのですが、まあまあ仕方ないので別の方法を考えていきましょう。座標の精確性に欠ける一球速報の座標データを、なんとかして評価値推定のフレームワークに役立てることはできないでしょうか。
手始めに「投球の座標データを一切使わない場合にできること」を考えます。「一球速報のデータは信頼できないので、推定には一切使用しない!」となった場合のアプローチですね。
まず、各投球のストライク・ボールの判定と、その時誰がキャッチャーの守備に就いていたかについての情報のみが得られる場合。当然「その投球が本来ストライクだったのか」についての議論はできないので、比較可能なのは、捕手毎のストライクコールの割合のみになります。守備に就いている時に取ったストライクが多い捕手がフレーミングに優れている、とするロジックです。

このアプローチはいわゆる捕手別防御率のそれ。先発投手がコマンドに長けた投手ならストライクは増えるでしょうし、"取らない"球審なら逆にボールが増えます。絡んでくる捕手以外の要素が多いため、単純に比率をみるだけでフレーミングの影響を抜き出すのはちょっと難しそうです。
では、捕手以外の(我々の目に観察可能な)影響がほぼ取り除けるとしたらどうでしょうか。これも当然ですが、某データサイトには捕手だけではなく、
・どの球場で
・どのカードで
・何回の表/裏の何球目に
・投手・球審・打者がそれぞれ誰で
…
など、投球に関する様々な情報が含まれています。これらをコントロールして「今この状況におけるストライクの比率」を細分化して計算、比較することができれば、だいぶ捕手の影響に近づくことができるのではないでしょうか。投手間、球審間、イニングや球場の違いによって起こる変動を取り除いてもなお残る差の部分、これを捕手の貢献とするわけです。図にするとこんな感じ。

==================
トラックマン(でもなんでもいいですが)によるデータが存在しない条件下だとできるのはこのあたりまで。ここにスホ°ナヒ"の座標データを加えていきましょう。「ざっくりこの辺」の情報を役立てる方法を検討します。
結論を先に出すと、今回はこの座標データをサンプルの絞り込みに使っていきます。分析の対象となるサンプル(投球データ)を「ストライクゾーンの境界付近」のみに絞った上で、前段落までで紹介した"条件付き確率"を比較するアプローチを利用した評価を算出することで、指標の信頼度の改善を目指します。
まず、ここまでで強調してきた通り、素人が利用可能なNPBの座標データは、ゾーンの中は100%ストライク、逆に外が100%ボールになるように位置の調整が行われています。
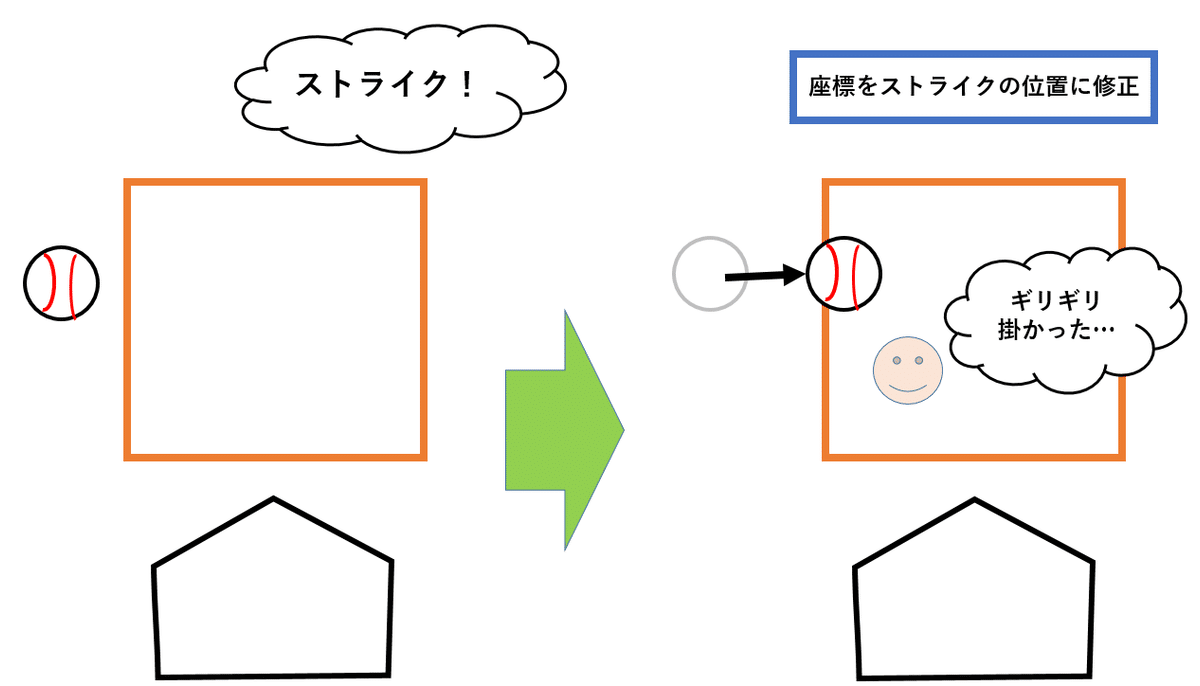
ここで、この座標データを入力する側の視点に立ってみましょう。アウトコースで高さは真ん中、ストライクゾーンを通過したように見えた投球がボールとコールされた場合、投球の座標はどこにプロットするでしょうか?ほとんどの人はゾーンのギリギリ外をその場所に選ぶと思います。少なくとも、ゾーンから大きく外れたところにプロットするという人はいないでしょう。同様に、低めに外れたボールがストライクとコールされた時にそれをド真ん中にプロットすることも起こりにくいと言えます。

これを勘案すると、目視+コールによる修正を加えた投球の座標データには「ゾーンの境界付近にはフレーミングその他の要因によってコールが変わった、あるいは変わりやすい投球が集まっており、明らかなストライク、明らかなボールに来た投球に比べるとその評価について重要な情報を持っている可能性が高い」という特徴があることが推察されます。
ストライクコールの確率が半々に近く、元々フレーミングの影響が出やすい領域の投球はもちろん、真ん中の変化球をミットが垂れてボールにしてしまった、打者がピッチャーだったので高めに外れた投球がストライクになったなど、絶対的な投球の通過位置以外の影響を大きく受けた投球もゾーンの境界にプロットされることになります。今回は、あえてサンプルをこの部分に絞り込むことで、誰が捕ってもストライク、誰が捕ってもボールになるような投球数の違いがノイズになることを防ごう、という発想です。
対象になる投球を図示するとこんな感じ。ストライクゾーンの枠は一定なので、高さについても打者ごとに伸び縮みすることはなく、上下の枠線が共通の境界になっています。

2020年のシーズン終了時点でのサンプルサイズは24,000で、これで打者が見送った全投球のうち約10%を使用していることになります。

哲学というか、この分析のキモ、"What's new?"に当たる部分はここまでです。自分の中で何となく落とし込んでいたものを改めて文字に起こすと色々説明がたいへんですね。上手く伝わっていない場合はぼくの説明が悪いのでTwitterなりコメントなり質問箱に「ここを教えろ」と言えば説明させて頂きますので。
4. 算出方法
さて、ということでいよいよ算出に入っていきます。「条件付確率の比較」という言葉を遣ってきましたが、これを比較するために今回は以下のような線形確率モデルを考えます(面倒だぞって方は遠慮なく飛ばして下さい)。

Umpire, Batter, Pitcherはそれぞれ投球ごとの球審、打者、投手の情報、Pitch Typeは球種、Inning, TopBotはイニングと表裏、CountとRunners onはカウントと塁状況、Parkは球場名のデータを表します。
被説明変数にストライク・ボールを表す二値変数(ストライクなら1、ボールなら0を取る変数)を取り、これをゲーム中の投球数と投手、球審、カウント、球場、…の固定効果で回帰します。固定効果は得られる全ての情報を使用しますが、捕手の効果だけは使わず残しておきます。
これにより、ゾーンの境界付近の(にプロットされた)投球について「ある試合のこの1球がストライクとコールされる平均的な確率」の予測値を算出することができます。「特定の状況におけるストライクコールの割合」と言い換えても構いません。例えば「東京ドームでの巨人対阪神戦、7回表に菅野投手が球審○○さんの時に投じたスライダーは平均××%の割合でストライクになっている」という予測値が算出されることになります。
予測値が算出されたら、あとはこれと実際のコールの差を捕手の貢献として積み上げていきます。平均ストライクの割合が40%の状況でストライクを取れば1-0.4 = 0.6、ボールなら-0.4とポイント化して、それを累積した値を対象の投球あたりで割れば、(その他の要素が正しく取り除かれているという前提で)捕手が増やしたストライクの数が計算できます。平均的な能力を持つ捕手であれば、ほぼ状況毎の割合通りにストライクを取ると考えられるので、評価値は0に近くなります。前回紹介した平均的な確率計算を、座標データ以外の要素について行うと考えればいいと思います。


一球一球を見ると同じゾーンの境目の投球でもボール気味だったり、逆にストライク気味の投球があったりで有利不利はあるので、個々の投球を見ると不公平な算出方法な気もします。しかし、今回の分析では、同じ状況であればこの有利不利が捕手に関わらず一定で起こる、という仮定を置きます。例えばマリーンズの美馬投手がマウンドに上がった時に「田村捕手の時だけ(フレーミング以外の要因で)ゾーンギリギリのボールの投球が増える」といったことは考えにくいからです。同様に、特定のバッテリーの時だけ球審による明らかなミスジャッジが増える、といったことも起こりにくいと考えます。こうしたイベントは特定の捕手だけで起こるのではなく、試合中に一定の確率でランダムに起こると仮定することになります。

今回もとても長くなりましたが、算出のアイデアは以上です。いよいよこれを実際のデータに応用した結果を議論していきます。
5. 結果
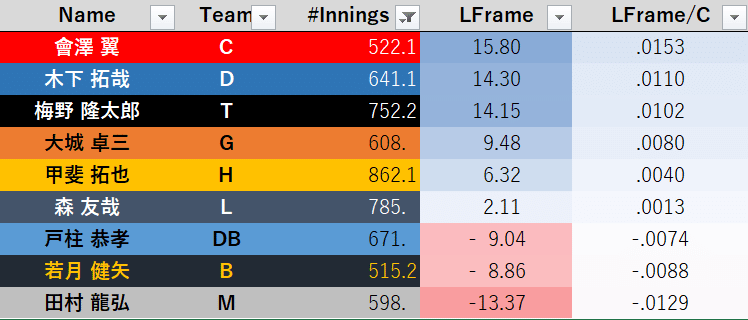
2020シーズンのデータを利用した指標のランキングはこちら。指標はストライクゾーンの境界付近の投球のみから情報を得ているという意味で"Local Framing"略して"LFrame"と命名しました。対象の投球1球あたりに直したものは/Cとして、この値の降順にランクをつけています。
・500イニング以上(約55試合フル出場)
・300~500イニング(約35試合フル出場~)

・100~300イニング(約11試合フル出場~)
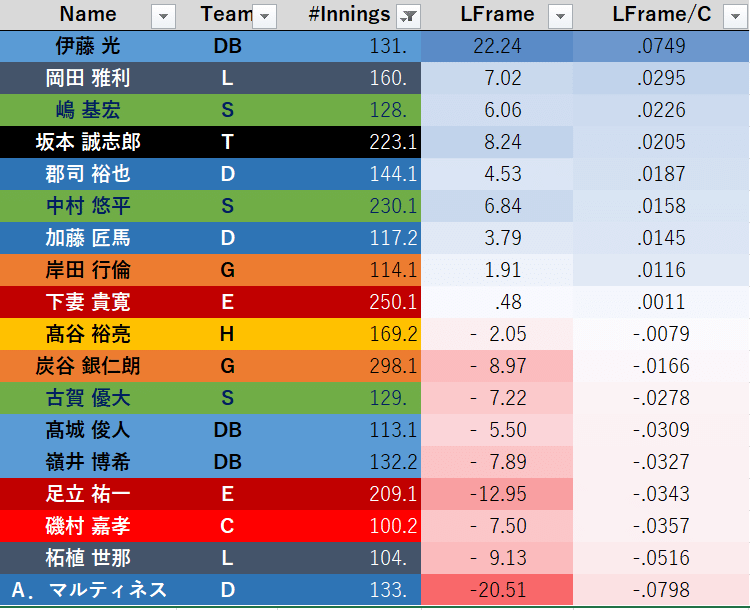
・30~100イニング

大外れでもないし「いいですねえへへ」とか言える感じでもなかろうなというところですかね。常にまるで逆のランキングを出してくるならそれはそれで信頼できるのですが(常に1時間遅れている時計と一緒)、少なくともこの数字だけを見て誰が上手い・下手を論じるのは危険だと思います。自分で作っておいて何を言うかって話ではありますが。
個人的なイメージとしては中日の木下拓哉捕手や阪神の坂本誠志郎・梅野隆太郎両捕手、楽天の太田光捕手らは技術的にも高いものを持っているイメージですね。広島の會澤翼捕手やロッテの柿沼友哉捕手、日本ハムの鶴岡慎也捕手あたりは一般的なそれとは別に、NPB独自で評価される技術を会得しているような気もします。逆にDeNAの嶺井博希・戸柱恭孝両捕手や広島の坂倉将吾捕手はもうちょっと上に来るのでは?といった印象を受けました。イニング数は少ないながら、今季途中に巨人から楽天に移籍してその技術に注目が集まっていた田中貴也捕手が高い数値を記録したのも興味深いところです。ではこれはイコール技術の高低として議論可能か、というところについては次回もう少し掘り下げていきます。
比較対象として、Y⚾M(@yuta_m89)さんのツイートを拝借・併記しておきます。ベイスターズの講演の内容の引用とのことですので、球団がトラックマンデータを元に独自算出したランキングかと思います。当然指標の信頼度はこちらの方が高いと思われますので、ここにどれぐらいの精度でアプローチできるのかというのが気になるポイントです。
フレーミング(降順、横並びは同等)
— Y⚾M (@yuta_m89) November 16, 2020
【+評価】
嶺井
木下拓
坂本
西田
戸柱 髙城
梅野
伊藤光
大城 加藤
宇佐見
伏見 清水 若月
郡司
柿沼
【0】
會澤
【-評価】
マルティネス
坂倉
足立
甲斐
田村
太田
森
高谷
炭谷 https://t.co/gw3dlYtCEl
ランキングと大きく乖離があるのはDeNAの2人と広島の會澤捕手、楽天の太田捕手あたりですかね。太田捕手はフレーミングの名手としてもよく名前が上がるのでちょっと意外でした。DeNAの伊藤光捕手、中日のA.マルティネス捕手はLFrameでかなり極端な数値を出していたので、このあたりが大雑把な位置情報による限界になってくるのかなと思います。サンプルサイズの問題もありますしね。ざっくり平均より上、平均より下に区分けするぐらいであればそれなりに信頼できるランキングになっているかなという感想です。
実際のデータを使用した指標の算出に辿り着いたところで今回はここまで。次回は指標の問題点や改善の方法、フレーミングをはじめとする指標の在り方について議論します。ある意味次回が一番大事だと思います。せっかく2本も飽きずに完走してくれた皆さんはぜひ目を通して頂ければ幸いです。。
最終回はこちらからどうぞ!
ご意見、ご感想はこちらから↓↓
おまけ
今回のおまけは奥田民生を貼るいつものパターンじゃありません。使用したRのコードです。基本独学なので多分に汚いですし、そもそもデータがないと動かないのであんまり意味はなさそうですが、興味があればどうぞ。
##パッケージの読み込み
library(tidyverse)
library(estimatr)
kore <- read_rds('npb/game/2020all.rds') %>% # データベースの読み込み
filter(type != 'Y') # 申告敬遠のレコードを除く
inns <- kore %>%
group_by(fielder_2) %>%
summarise(
inning = sum(outs_on_play) / 3
) %>%
mutate(
inning = inn_num_to_frac(inning) # 端数のイニングを.1, .2で表記させる関数
) # 守備イニング数を集計
are <- kore %>%
filter(description %in% c('called_strike', "ball")) %>%
select(
c(
pitchid, pitch_name, plate_x, plate_z, pk_name, pitcher, batter,
fielder_2, b_stands, inning, inning_topbot, batting_team,
fielding_team, strike, ball, outs, runners_on,
h_score, v_score, ump_pl, description, outs_on_play
)
) %>%
mutate(
Strike = if_else(description == 'called_strike', 1, 0),
# ストライクコールを0, 1に変換
zone_disc = shadow_zone(plate_x = plate_x, plate_z = plate_z),
# 自作関数で対象の投球を特定
count = paste0(strike, '-', ball),
lev = abs(h_score - v_score)
) %>%
filter(zone_disc == 'shadow' & b_stands == '右')
# 右打者&境界付近の投球に絞る
model <- estimatr::lm_robust(
Strike ~ poly(as.numeric(pitchid), 3) + poly(lev, 3), data = are,
fixed_effects = pitch_name + pk_name + pitcher + runners_on +
batting_team + ump_pl + as.character(inning) + inning_topbot +
batter + count
) # 固定効果モデルの推定
pred <- model$fitted.values # 出てきた予測値を突っ込む
dore <- are %>%
mutate(
residuals = Strike - pred
) # 予測値との差分をポイント化
right <- dore %>%
group_by(fielder_2) %>%
summarise(
team = tn_changer(head(fielding_team, 1)),
numR = n(),
framingR = sum(residuals)
) # ポイントを捕手毎に積み上げる
# 同じ操作を左打者でもやる(省略)
# 左右を合計して捕手毎に算出
total <- inner_join(right, left, by = c('fielder_2', 'team')) %>%
mutate(
num = numR + numL,
framing = framingR + framingL
) %>%
select(c(1, 2, 7, 8))
# イニング数のデータと結合して規定以上の選手に絞る
frame <- inner_join(total, inn, by = 'fielder_2') %>%
mutate(Fperpitch = framing/num) %>% # 対象となる投球1球あたりに変換
filter(inning >= 180) %>% # イニング数の下限を切る
arrange(-Fperpitch) %>% # 1球あたりポイントの降順にランキング化
rename(
'Name' = fielder_2, 'Team' = team, '#Innings' = inning,
'LFrame' = framing, 'LFrame/C' = Fperpitch #列名を再定義
) %>%
select(c(1, 2, 5, 4, 6))いいなと思ったら応援しよう!
