
ビジネス!FUMA(フーマ)から企業の情報をスクレイピングする

FUMA(フーマ)とは?
FUMA(フーマ)とは、全国160万社の有力企業に限定した企業概要データベースを、無料で、何件でも、閲覧できるサービスです。大手企業や上場企業を取引先にもつITベンチャー、株式会社Plainworksが2019年に満を持してリリースしました。営業リスト・企業リスト提供サービスでありがちな、会員登録も一切不要のため、すぐに利用できます。オンライン上で都道府県・業種・設立年など、さまざまな条件で絞り込み検索ができるので、たとえば「関東にある設立20年以上で、未上場、情報サービス業」といった検索結果をかんたんに表示できます。
スクレイピングツールの概要
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすく人工知能Webスクレイピングツールです。違う基盤のユーザーに二つのスクレイピングモードを提供し、1-Clickで99%のWebスクレイピングを満たします。ScrapeStormにより、大量のWebデータを素早く正確的に取得できます。手動でデータ抽出が直面するさまざまな問題を完全に解決し、情報取得のコストを削減し、作業効率を向上させます。
抽出されたデータは下記のようにご覧ください

1.タスクを新規作成する
FUMAの検索結果ページのページボタンの識別はXpathが必要です。素人にとってXpath編集が難しいから、URLジェネレーター機能を利用して、直接URLを生成してください。
(1)URLを生成する
今回はURLジェネレーター機能を利用する必要がありますから、できるだけ第二ページ以降のURLをコピーしてください。

(2)スマートモードタスクを新規作成する
ScrapeStormのホムページ画面にスマートモードタスクを新規作成します。また、持っているタスクをインポートすることもできます。
詳細には下記のチュートリアルをご参照ください。
URLを正しく入力する方法

(3)URLジェネレーター機能
①URLの主幹、つまり変更する必要があるページ番号前の部分を記入します。
②パラメーターを追加で番号を追加します。今回は0から500まで設定して、ステップは50です。

2.タスクを構成する
(1)ページボタン
通常、ScrapeStormは自動的にリスト要素とおページボタンを識別できます。今回はページボタン設定に「必要なし」に設定してください。

(2)詳細ページに行く
「詳細ページに行く」ボタンをクリックして、企業の詳細情報ページに移動できます。もし、ページ内のデータが混雑しているの場合、リフレッシュしてください。

(3)フィールドの追加と編集
「フィールドを追加」ボタンをクリックして、画面に必要な要素を選択、データが自動的に抽出されます。また、必要に応じてフィールドの名前の変更または削除、結合できます。
フィールドの設定の詳細には下記のチュートリアルをご参照ください。
抽出されたフィールドを配置する方法

3.タスクの設定と起動
(1)起動の設定
必要に応じて、スケジュール、アンチブロック、自動エクスポート、写真のダウンロード、スピードブーストを設定できます。
スクレイピングタスクを配置する方法については、下記のチュートリアルをご参照ください。
スクレイピングタスクを配置する方法

(2)しばらくすると、データがスクレイピングされる。

4.抽出されたデータのエクスポートと表示
(1)エクスポートをクリックして、データをダウンロードする
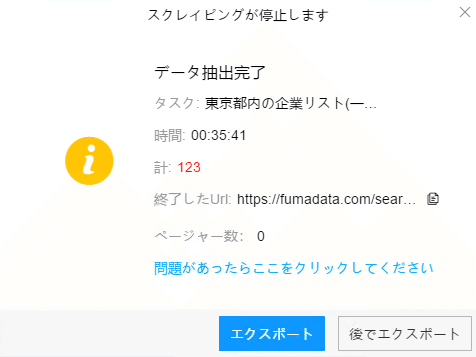
(2)必要に応じてエクスポートする形式を選択します。
ScrapeStormは、Excel、csv、html、txt、データベース、ローカルなどさまざまなエクスポート方法を提供します。ライトプラン以上のユーザーは、WordPressに直接投稿することもできます。
抽出結果のエクスポート方法の詳細には下記のチュートリアルをご参照ください。
抽出されたデータのエクスポート方法

参照リンク:https://www.creditsafe.com/jp/ja/blog/business/fuma.html