
嵐のメンバーの画像認識をやってみました

目次
初めに
実行ツール
作業内容
終わりに
はじめに
初めまして。
機械学習を勉強している初心者です。
今回は人を識別するアプリを作ってみたいと思い、嵐のメンバーを識別するWebアプリを作ってみました。
実行ツール
Python
Visual Studio Code
作業内容
データ収集
機械学習で画像を識別する精度を上げるために、学習に使用するデータの数が数多く必要されています。
それを全部手動でダウンロードするのは効率が悪いので、今回はicrawlerツールを利用してでーたの収集を行いました。
icrawler
icrawlerは検索サイトで画像データをキーワード検索で自動収集できるpythonライブラリです。
私はキーワードのそれぞれ5人のメンバの名前を設定し、Bingキーワード検索によって画像を自動ダウンロードさせました。
from icrawler.builtin import BingImageCrawler
import glob
#検索リストの生成
search_words = ["二宮和也","櫻井翔",'相葉雅紀','松本潤','大野智']#検索したい単語
dir_names = ["nino","sakurai",'aiba','matujyun','oono']#保存するときのフォルダ名
for search_word,dir_name in zip(search_words,dir_names):
# Bing用クローラーの生成
bing_crawler = BingImageCrawler(
downloader_threads=4, # ダウンローダーのスレッド数
storage={'root_dir': dir_name}) # ダウンロード先のディレクトリ名
# クロール(キーワード検索による画像収集)の実行
bing_crawler.crawl(
keyword=search_word, # 検索キーワード(日本語もOK)
max_num=200) # ダウンロードする画像の最大枚数データの前処理
AIに学習させる場合、学習データとラベルが対応されています。
icrawlerでダウンロードされたデータの中には、メンバ名を検索して出てきた画像にも、本人ではない画像が混ざっていますので、学習結果に影響しないように、本人ではない画像をを手動で削除しました。
また、人を識別する精度をさらに上げるために、データ量を増やす必要があります。
そこで、元のデータに変換を加えるデータの水増しを行いました。
また、5人のメンバーそれぞれのデータの中、8割を学習データ、2割を検証データとして設定しました。
データの水増し
データの水増しはデータ量を増やすことで、AI学習の精度を上げるためによく使われています。
水増しには、画像の左右反転、閾値処理などの方法があり、私のコードには、前述二つ方法に加え、画像のぼかしと収縮も行い、画像を9000枚ほど増やしました。
scratch = np.array([
#画像の左右反転
lambda x: cv2.flip(x, 1),
#閾値処理
lambda x: cv2.threshold(x,100,255,cv2.THRESH_TOZERO)[1],
#ぼかし
lambda x: cv2.GaussianBlur(x,(5,5),0),
#モザイク処理
lambda x: cv2.resize(x, (x.shape[1] // 5 * 5, x.shape[0] // 5 * 5 )),
#収縮
lambda x: cv2.erode(x,filter1)
])データ学習
ここでは、まず既存のVGG16というモデルを利用し、転移学習を行ったモデルを構築しました。
転移学習とは、既存の学習済みのモデルをインポートし、そこで、自分のモデルのためのデータを追加することで、新しいモデルを作成する方法です。
VGG16とは、100万枚以上の画像の学習ずみの、深さが16層の畳み込みニューラルネットワークです。データ規模が大きいので、画像分類を行う際、よく使われます。
VGGモデルを結合後、特徴抽出部分の重みが更新させると崩れてしまう、そのため、layer.trainable = Falseを使って固定しました。
モデルの学習を行う際は様々なパラメータを指定しましたが、それぞれ下記意味を持っています。
X_train, y_train:学習用データとラベルデータ
batch_size:同時に学習させるデータ数
epochs:学習する回数
verbose:ログ出力の指定
validation_data:評価用データ
#VGGモデルを結合する
model = Model(inputs=vgg16.input,outputs=top_model(vgg16.output))
for layer in model.layers[:15]:
layer.trainable = False
#モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer='adadelta',
metrics=['accuracy'])
#モデルの学習
model.fit,
batch_size=30,
epochs=35,
verbose=1,
validation_data=(X_test, y_test))モデルの検証
水増しなしモデルの検証結果:
テストロス:1.56
テスト精度:0.33

水増し処理後のモデル検証結果:
テストロス:0.40
テスト精度:0.98
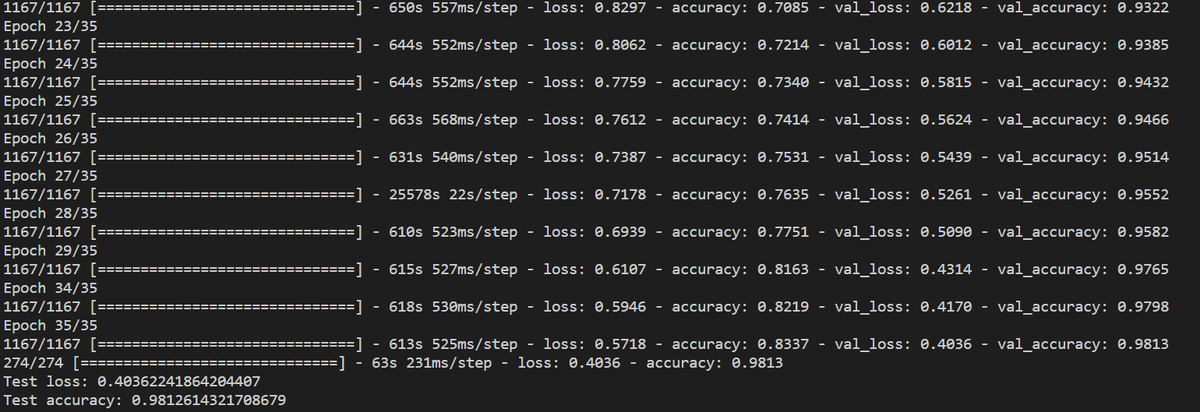
今回は学習用データを水増しする前はそれぞれのメンバの学習用データが200枚程度しかなかったため、0.33という低い精度でした。
水増しを利用し、それぞれのメンバの学習用データを9000枚程度に増やし、もう一度学習させた結果、精度が0.98に上がりました。
改善
今後はデータ学習時のパラメータをより最適に変更することで、精度をさらに高める方法が考えられます。
model.fit(X_train, y_train,
batch_size=30,
epochs=35,
verbose=1,
validation_data=(X_test, y_test))Webアプリ画面


終わりに
AIの勉強を始めてから半年が経ちました。
勉強を始める前までは、自分がAIアプリなんて作れないでしょうと思いました。
今回のAIアプリはAidemyでの最終成果物の課題として作成することになりました。
AIは初めてですが、質問ができる講師の方々がいて、勉強がうまく進めることができました。
これからもこの半年間勉強したことを忘れないように、自分が興味あるアプリやコードを書いてみたいと思います。