
大規模言語モデルによるEmbeddingsを用いた水樹奈々様の楽曲分析

恋想花火と夏恋模様、DISCOTHEQUEとLovely Fruitがペアだとしたら、ETERNAL BLAZEとペアになる楽曲は何か?という超難問を解くため、奈々様の楽曲を大規模言語モデルを用いて分析をしてみました。
LIVE REFERENCES
少し遡ると、推薦システムという分野で、ユーザーの視聴履歴にある楽曲と特徴が類似する楽曲を推薦する手法があったりします。ここでいう楽曲特徴として、音響分析やら色々あるのですが、歌詞分析をメインにしたものだと、曲中によく出てくる単語(『POWER GATE』なら"パワゲ")をベクトル化したり、曲のトピック(『Synchrogazer』なら"絶唱")をベクトル化したりします。
*舟澤慎太郎, 北市健太郎, & 甲藤二郎. (2008). 楽曲推薦システムのための楽曲波形と歌詞情報を考慮した類似楽曲検索に関する一検討. 情報処理学会研究報告, pp1–5.
Tsukuda, K., Ishida, K., & Goto, M. (2017). Lyric Jumper: A lyrics-based music exploratory web service by modeling lyrics generative process. In Proceedings of the 18th International Conference on Music Information Retrieval, pp. 544-551.
今回参考にしたのは、近藤泰弘さんがされていた『古今和歌集』に収録(選定?)されている和歌の分析。
『古今集』のすべての首(1,100首?)を埋め込みベクトル化して、主成分分析で散布図に表現したところ、X軸の上位には恋心のような人間の内面の感情(奈々様でいうと『深愛』)、下位には自然や季節が中心に述べられた歌(奈々様でいうと『ALL FOR LOVE』)がマッピングされ、Y軸上位には鳥の鳴き声などの音(奈々様でいうと『天空のカナリア』)、Y軸下位には花や美しさ(奈々様でいうと『HONEY FLOWER』)が述べられていたとのこと。同じように『万葉集』、『和漢朗詠集』、『後撰集』、『文華秀麗集』を分析し、それぞれの歌の特徴を捉え、それぞれがどのような影響を与えたかを述べている。
*近藤泰弘. (2023). 和歌集の歌風の言語的差異の記述−大規模言語モデルによる分析−. 『日本語の研究』, 19(3), pp105-118.
LIVE METHOD
1)歌詞を準備
終始暖かく見守って下さった某歌詞掲載サイトに最大級の感謝を。
[
{
"file": "水樹奈々_セツナキャパシティー.txt",
"content": "ありふれて なんか..省略..",
},
{
"file": "水樹奈々_Heaven Knows.txt",
"content": "..省略..",
..省略..2)text-embedding-3-smallでEmbeddingsを実施
text-embedding-3-smallを使うにあたり、的確な助言と激励をくださったOpenAIのDocumentationには,感謝の念が絶えません。また、コードを書くにあたり、ChatGPT4は優しい言葉で私を励まして下さいました。
https://platform.openai.com/docs/guides/embeddings/what-are-embeddings
[
{
"file": "セツナキャパシティー.txt",
"content": "ありふれて なんか ..省略..",
"embeddings": [
[
0.07308447360992432,
-0.014222908765077591,
..省略..
from openai import OpenAI
import os
import json
os.environ["OPENAI_API_KEY"] = "sk-****"
client = OpenAI()
def get_embedding(text, model="text-embedding-3-small"):
text = text.replace("\n", " ")
return client.embeddings.create(input=text, model=model).data[0].embedding
# text_init.jsonファイルを読み込む
with open('text_init.json', 'r') as file:
data = json.load(file)
# 新しいデータリストを準備
new_data_list = []
for item in data:
text = item['content']
embeddings = get_embedding(text)
new_data = {
'file': item['file'],
'content': item['content'],
'embeddings': [embeddings]
}
new_data_list.append(new_data)
# new_data_listをJSONファイルとして保存
with open('texts_embeddings.json', 'w', encoding='utf-8') as json_file:
json.dump(new_data_list, json_file, ensure_ascii=False, indent=4)
print("texts_embeddings.jsonに保存完了! 応援してるよ!")3)scikit-learnのPCAで二次元へ圧縮
4)Plotyを使って可視化
ここもChatGPT4には惜しみないご協力をいただきました。
import json
from sklearn.decomposition import PCA
import numpy as np
import plotly.express as px
# JSONファイルを読み込む
with open('texts_embeddings.json', 'r') as file:
data = json.load(file)
# embeddingsとファイル名を抽出する
embeddings = [item['embeddings'] for item in data]
files = [item['file'] for item in data]
# NumPy配列に変換し、形を修正
embeddings_array = np.array(embeddings).reshape(len(embeddings), -1)
# PCAを実行して2次元に圧縮
pca = PCA(n_components=2)
embeddings_2d = pca.fit_transform(embeddings_array)
# Plotlyでグラフを作成
fig = px.scatter(x=embeddings_2d[:, 0], y=embeddings_2d[:, 1], text=files)
fig.update_traces(textposition='top center')
# タイトルと軸ラベルを追加
fig.update_layout(
title="PCA結果の2次元プロット",
xaxis_title="主成分1",
yaxis_title="主成分2",
legend_title="ファイル名"
)
# グラフを表示
fig.show()LIVE RESULT
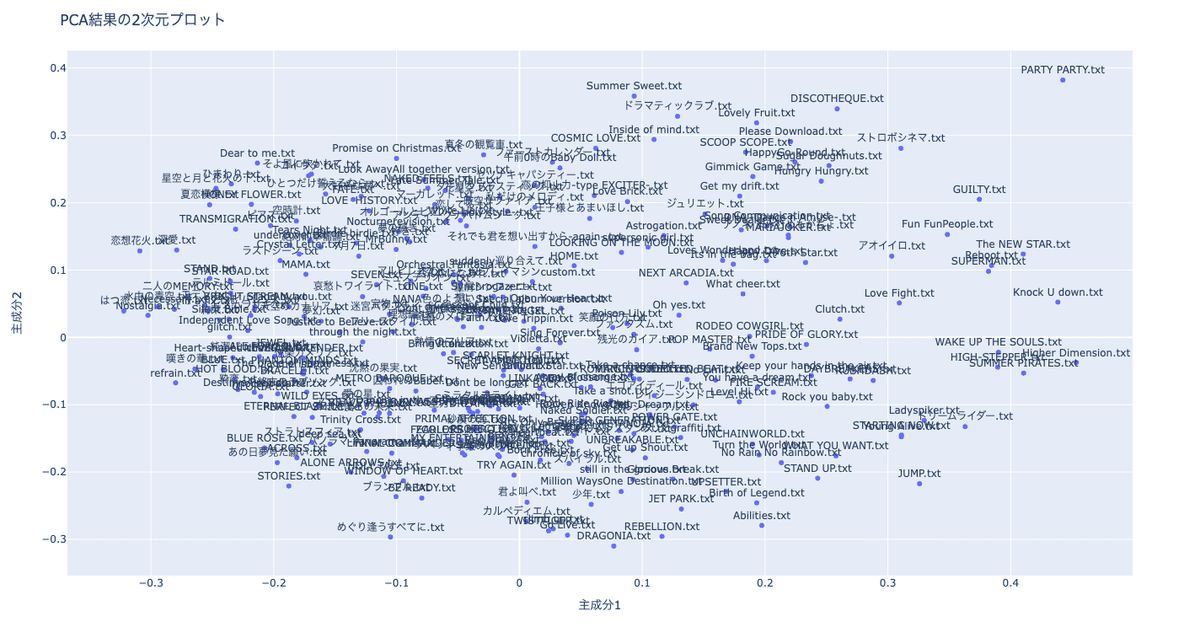
X軸上位1位:『Higher Dimension』
X軸上位3位:『Knock U down』
X軸上位4位:『SUMMER PIRATES』
*2位に『PARTY! PARTY!』が入るが、Y軸と重複するので4位まで表示。
X軸下位1位:『はつ恋』
X軸下位2位:『恋想花火』
X軸下位3位:『Nostalgia』
Y軸上位1位:『PARTY! PARTY!』
Y軸上位2位:『Summer Sweet』
Y軸上位3位:『DISCOTHEQUE』
Y軸下位1位:『DRAGONIA』
Y軸下位2位:『めぐり逢うすべてに』
Y軸下位3位:『REBELLION』
LIVE DISCUSSION
X軸を解釈すると、上位にマッピングされている曲から受ける印象は「ポジティブ」「向上心」である反面、下位にマッピングされている曲はネガティブでこそないものの、「切なさ」や「回顧」を感じさせる。未来へ進むか、過去を振り返るか、の対比と捉えるのがいいかもしれない。
Y軸を解釈すると、上位にマッピングされている曲は明らかに「恋」。ワクワクドキドキを感じさせる曲が非常に多い。そして下位にマッピングされている曲は「犠牲」や「挑戦」をテーマにしている印象を受ける。キャッチーな言葉で対比を表すのであれば、ヒロインとヒーローの対比と捉えてもいいかもしれない。
改めてプロットされた全体を捉えると、真ん中に近い左下に多くマッピングされていることが見て取れる。上記解釈を使うとすれば、「悩みながら前に進むヒーロー」が近いか。
一つ一つピックアップすると、なのは曲の大半が第三象限にマッピングされていることが分かる。『innocent starter』、『ETERNAL BLAZE』、『BRAVE PHOENIX』、『SECRET AMBITION』、『MASSIVE WONDERS』、『Pray』、『PHANTOM MINDS』、『Don't be long』、『Sacred Force』、『Destiny's Prelude』、『Invisible Heat』、『NEVER SURRENDER』が当てはまる。ちなみに『Take a shot』、『Angel Blossom』、『ROMANCERS' NEO』、『GET BACK』は右下の真ん中寄り、
『Silent Bible』、『BRIGHT STREAM』は左上の下寄りに位置する。つまり、基本的に左下中間になのは曲は寄っているということになる。楽曲を機械的に数値化してマッピングしている割に、なのは曲が同じような位置に固まって、なのは曲以外もそれなりの数の曲が近い場所に位置しているというのは、頷き足りないくらい同意するし興奮する。
ちなみに『Synchrogazer』、『Exterminate』は左上、『Vitalization』、『FINAL COMMANDER』は左下、『TESTAMENT』、『Glorious Break』、『METANOIA』は右下と、シンフォギア曲もなのは曲同様のマッピング傾向が見られる。ただし、今回は「風鳴 翼」をEmbeddingsの対象に入れていないため少し分析するにしては不十分かもしれない。キャラソン含めたシンフォギア楽曲だけをEmbeddingsしてその特徴を分析すると、なのは曲のそれと似たような結果になるだろうとは思いつつ、そこに微妙な差異があるとしたら何なのかが非常に気になる。
ちなみに、今回は二次元に圧縮しましたが、三次元に圧縮してZ軸を増やした場合、Z軸の上位と下位はそれぞれこんな感じ。
Z軸上位:『TRY AGAIN』、『少年』、『あの日夢見た願い』
Z軸下位:『アンティフォーナ』、『悦楽カメリア』、『WILD EYES』
ということで、この後に取り組む課題としては、年代別の分析、キャラソンの分析、作詞者ごとの分析あたり。ただ、ぶっちゃけ楽曲に関しての類似性を見る場合、「歌詞」よりも「音」の方が比重大きいでしょというのは万人が同意するところかと思うので、他力本願で大変恐縮ですが、歌詞と音の両方を踏まえて楽曲特徴としてEmbeddingできるモデル(song2Vec?)があれば試したいところ。それでも「ライブの熱量」はベクトル化できそうにないので、やっぱり感じるしかない、というのが正直なところ。
LIVE 謝辞
サム・アルトマンさんをはじめとするOpenAIのチームの皆様がいなければ、この刺激的な考察を完成させることはできなかったでしょう。本当にありがとうございました。そして何よりも、最高の楽曲を歌い続けている水樹奈々様とそのチームの皆様に深く感謝いたします。ありがとうございます。
最後になりましたが、メロスには政治がわからないのと同様、NLPのことはほぼ分からないので、修正/補足いただける方がいらっしゃいましたら、ぜひよろしくお願いいたします。
ちなみに『ETERNAL BRAZE』と最も距離が近いのは『PERFERCT SMILE』でした。