
若手小児科医による経験ゼロからの、機械学習による予測モデル作成の道

こんにちは、次郎作こと布施田泰之です。
僕は今医師5年目で、小児科の後期研修を行っています。
今回、1ヶ月間病棟フリーの期間をもらい、データサイエンス研修と題して研究室に配属してもらい、
プログラミング/機械学習の経験ゼロの状態から、
1ヶ月間で「川崎病の初期治療に対する、不応症例を予測する」という機械学習モデルを作成したので、その過程をnoteに書こうと思います。
AIや機械学習に興味のある、医学生や若手医師の方々に読んでもらえると、
「機械学習はどうやって学ぶのか」「どういったことが出来るのか」などが想像できるようになると思います。
最終到達点

最終的には、現存の「予測スコア」より精度の高い「機械学習予測モデル」を作れました!
まだまだ、Methodのところで詰めないといけないことはたくさんありますが、データさえ集めれば論文化も検討できそうです。
それまでの道のりを書いていきます!
自己紹介
こういう文章を読む時に、「どういった人が書いているか」が大事だし、知りたいと思うので明記しておきます。
僕は、医師5年目、後期研修3年目の小児科医です。基本的には、常勤としてこども病院に勤務しています。
僕の病院では、後期研修3年目にtotalで2ヶ月間、「自由選択期間」という「基本給をもらいながら何をしても良い期間」がもらえます。
僕は元々は海外に行く予定でしたが、新型コロナで行けなくなってしまったので、「機械学習を勉強してみたい」と言って、2020年の11月の1ヶ月間でデータサイエンス研修を希望して研究室へ配属してもらいました。
研究室配属と書きましたが、結果的には直接はほとんど何も教わっていません笑
最初に研究室のトップの方に会った時に「プログラミングとか機械学習は、勉強しようと思えば全部ネットに教材が落ちてるから、分からないことはググって勉強してみてください。ただし、勉強のログだけは基本的に毎日つけてください」と宣告されて笑、プログラミングの勉強から機械学習の勉強まで自分で調達してきたものでやりました。
ほぼ全て自分で調べて、勉強してきたからこそ、勉強の道のりや1ヶ月間での成果を公開することが価値が高いかな、と思ってこのnoteを書いています。
プログラミング/機械学習の勉強のためにやったこと

このスライドにプログラミングと機械学習で勉強したことをまとめました。
まずは、機械学習を勉強するためには機械学習の分野で使われているプログラミング言語の「Python」を勉強しなければなりません。
そのために、9月ごろから「Python1年生」という本を1冊やってみて勉強しました。
(1ヶ月の研修期間の2ヶ月前から仕事後にチョコチョコ勉強してました笑)
この本では、読みながらコードを実際に打っていくことで、Pythonの基本と機械学習がどのように進んでいくのかを理解できました。
この本の最後では「手書きの数字が、どの数字か判別する」というプログラムを書くのですが、
「プログラムを書き写しただけなので、意味は分からない。雰囲気はわかった」くらいにまでなることができました。
次に、プログラミング言語の「Python」自体の理解が全然できていないと感じ、
有料でしたが「Progate」というサイトでPythonの勉強をしました。
このサイトで本当に基本的なところからプログラミング(Python)を学んで、根底にある考え方などが分かるようになりました。
でも、一から自分でコードを打っていくのは難しく、徐々に書いてあるコードを理解するのができるようになった、くらいの印象です。
このあたりで「GCI2020winter」というセミナーに出会います。
GCI2020winterとは
GCI2020winterとは、東京大学の松尾研究室という機械学習で有名な研究室が主催している冬季セミナーです。
これまでに2000人以上の受講者がいて、豊富な資料の講義があり、それでいて無料で参加できるという、とても良い講座でした。

こんな感じで週1回の講義があり、宿題も課されます。
ある程度のボリュームのある教材をこなさないといけないですが、
多少忙しくても臨床をやりながらこなすのは要領よくやれば可能、くらいのイメージです。
実際僕も、予習・復習の時間を取ったり宿題を自分の力だけでやるのは難しかったので、
受講者がみんな入っているslackで宿題に関する質問をしたり、他の人の質問に対する回答を読んだりして、どうにか宿題を全部出し切ることができました。
講義資料は、Google Colaboratoryという、PythonをGoogle Chrome上で書いたり、プログラムを動かしたりできる神環境で共有されます。

僕は2時間も座って講義を聞いている時間がなかったので、この講義資料を読んで理解することで勉強しました。
Python、Numpy、Pandasなどどれをとっても秀逸な講義資料で、この講義資料を手に入れるためだけに講習を受けてもいいなと思えるくらい価値の高いものでした。
受講生に課せられる「コンペ」とは

このGCI2020winterの講習は、講義と宿題だけでなく、全3回の「コンペ」をこなさなければなりません。
医療関係者には全く馴染みがない文化なので説明すると、
コンペとはコンペティッションの略で、
「実際に機械学習を用いた課題に取り組んで、その精度を競いながら学ぶ」ことです。
1日に3回、採点が行われ、毎日ランキングが変動しながら、自分の順位を確かめることになります。
実際に課題を解決しようと機械学習を用いるので、僕たちが「On the Job」と呼ぶような実務上での勉強になり、とても実践的な学びが得られます。
ゲーム感覚で順位を争うので、かなり効率よく勉強することができました。こうやって世界中のエンジニアの方々はスキルアップしているんだなぁと感心しました。
2020年11月の1ヶ月間の病棟フリーの期間までに、上記のような教材でプログラミングと機械学習を学びました。
1ヶ月間のスケジュール
ついに「機械学習」だけをやって良い期間がきたので、自分としてスケジュールを立てました。
第1,2週:プログラミングと機械学習の基礎を学び直す
第3,4週:機械学習を臨床に応用できるかを検証する
と、目標を定めました。
第1-2週では、上記のGCIwinter2020の講義資料を復習しながら、
「PyQ」というサイトで、NumpyやMatplotlibなどのプログラミング言語のPython上のライブラリ(便利ツール)の使い方などを復習しました。
これは1ヶ月間のみの契約で3040円/monthと有料でしたが、手軽だったので1ヶ月だけ契約して勉強したいところを勉強しなおしました。
また、先ほど書いた「コンペ」の第二回がちょうど開催されていたので、本気で取り組んで、
このタイミングで「自力で初歩的な機械学習モデルを組んで、事前のデータから結果変数を予測する機械学習モデルを作る」ことができるようになりました。
ここら辺で「データさえ集まれば、臨床的な予測モデルも作れるのでは?」と考えるようになりました。
なので、第3-4週に向けて、検証する臨床の問題をリストアップしました。
小児領域で予測モデルが活用できること

機械学習を学ぶ前は、「機械学習=画像認識が得意」という思い込みがあったため、「グラム染色を判定する機械学習プログラムを作ろう」と思っていましたが、
勉強してみると「臨床的な予測モデル」こそが機械学習の初心者にもできる有意義な領域だな、と感じました。
そこで、小児領域ですでに有名なスコアリングを挙げて考えたところ、
知り合いに川崎病を研究していてデータを持っている先輩医師がいたこともあり、
「川崎病という小児特有の疾患の、初期治療(免疫グロブリン療法)に治療抵抗性があるかどうかを、入院時点のデータから予測する機械学習モデル」
を作成してみることにしました。
(当たり前ですが、カルテidすら入っていない個人情報の消されたデータをお借りしました)
機械学習による予測モデルの臨床的な意義

医学生や初期研修医、もしくはデータサイエンス出身の方には、あまり馴染みがない人もいると思うので、軽く川崎病の説明をします。
川崎病とは、発熱、眼球結膜の充血、口唇の発赤・腫脹、頸部リンパ節腫大、皮疹、手足先の発赤・腫脹、の6症状が出ることが有名な、こどもに特有の疾患です。
いまだ原因は不明ですが、治療薬は分かってきており、特に最初は「免疫グロブリン療法(IVIg療法)」を行うことで炎症を抑えられることが分かっています。
この治療の普及により、一番重篤な合併症である「冠動脈瘤(心臓を走る血管に瘤ができてしまう)」の発生頻度も25%→2-4%と著名に減少しました。
しかし、川崎病全体の20%程度は「1回目の免疫グロブリン療法が効かず、炎症が続いてしまう」ことが分かっており、この初期治療抵抗例では「冠動脈瘤の発生が多い」ことが分かっています。
川崎病に対する、群馬スコアとは

2006年に「群馬スコア」として知られる「川崎病の初期治療抵抗例を予測する予測スコア」が論文で発表されました。
また、この予測スコアを用いて「初期治療抵抗例」と判定された症例に対して「初期治療を強化する(ステロイド療法を追加する)」と合併症が減る、ことを示した論文が、Lancetと言われる医学界の三大ジャーナルに掲載されました。
そのため、実臨床の場でも、
入院時に群馬スコアをつけて、5点以上であれば治療を強化する
ということが行われています。

つまり、精度の高い機械学習予測モデルを作成して、
正確に川崎病の治療抵抗例を予測して、的確に治療強化することができれば、「冠動脈瘤」という心臓の合併症に苦しむ子供を減らすことができます。
精度の高い予測モデルに臨床的な価値があることは、分かっていただけたと思います。
ということで、

後半3-4週の目標は、
先行研究で有名な「群馬スコア」や「久留米スコア」といった予測スコアより精度の高い機械学習予測モデルを作ること、としました。
今回使用したデータセット

今回使用したデータセットは、入院時のデータから、採血データ、入院後経過までのデータが集まっている、ものを使わせてもらいました。
ただ、症例数としては224例と、すごく多いわけではありません。
初期治療抵抗例(IVIg不応例)は、全体の19%でした。
教師ありの機械学習の流れ

とてもわかりやすい図があったので引用させていただきました。
これが教師ありデータの機械学習で予測モデルを作るときの流れになります。
①データの前処理
②あるモデルで試してみる
③データを分析する
④特徴量エンジニアリングを行う
⑤色々なモデルを試す
⑥モデル同士をミックスする
上記の流れがあり、その各工程を行ったり来たりしながら機械学習モデルを作成していきます。
実際の機械学習モデル作成の過程


まずは、「データの前処理」をして、Google Colaboratoryで扱えるようにします。
具体的にやったことは、
・転院症例はデータ欠損が多いため除外
・初期治療の反応性のデータがない症例も除外
・入院時のデータから予測モデルを作りたいので、入院後のデータを除外
・エクセルでは欠損値に「無」などと文字データが入っていたので、欠損値と認識できるように「空欄」とした
以上の処理です。やっとことは、かなり基本的なことだけです。
次に、Google Colaboratoryへデータを読み込ませるのに数時間かかりました。
初心者だと至るところに分からないポイントが潜んでいますが、研究室のトップの方のいった通り、粘り強くググり続けたら解決しました笑
"drive.mount"と"pd.read_excel"のコードさえ知っていれば一瞬でした
データを眺める

データを読み込ませた後は、データを眺める作業が必要になります。データの分析と言い換えても良いと思います。
1. 「データの数」や「データ型」を調べたところ、謎の文字データが入っていることが発覚し、エクセルのデータを見直すと欠損値が「無」などと文字データで入っていることが原因だったので対応しました。
2. 機械学習のモデルを組む上で、欠損値があると対応できないことが多いため欠損値の数を確認したところ、ある程度の数あることが分かったので、「欠損値を、データの中央値で埋める」という処理を行いました。
(この欠損値の扱いは、色々な対応方法があります。一番安直な埋め方をしています笑)
3. その後「目的変数である、初期治療抵抗例か否か」の結果が極端に偏っている(1万症例に1症例しか初期治療抵抗例がいない)場合は、特殊な対応が必要なので確認してみたところ 、初期治療抵抗例は25%くらいいることが確認できました。
ある機械学習モデルで試してみる

データの特徴を掴んだら、一度深く考える前に「ある機械学習モデルで試してみる」ということをします。
今回は、先行研究が全て「ロジスティック回帰分析」を用いた予測スコアだったために、「ロジスティック回帰モデル」を使用しました。
結果は、感度13% 特異度92%、AUCが0.625
と、予測モデルとしてはイマイチでした。
感度や特異度と言われてもチンプンカンプンの人もいると思うので、
今回の機械学習の予測モデルの精度の指標である「感度」「特異度」「ROC曲線のAUC(Aria Under the Curve)」についても、簡単に説明します!

感度・特異度とは、下のように定義されます。
感度:「初期治療抵抗性がある」と予測された症例の中で、「実際に初期治療抵抗性だった」割合
特異度:「初期治療抵抗性はない」と予測された症例の中で「実際に初期治療抵抗性がなかった」割合
つまり、感度18%という精度は「機械学習モデルが100人を初期治療抵抗性がある、と予測しても、実際にはその中の18人しか本当に初期治療抵抗性がある症例がいない」というショボい精度になります。
ROC曲線のAUCに関しては、医療者だと「検査の感度・特異度」の話の中で聞いたことがあると思いますが、
簡単にいうとROC曲線のAUCという値は、
「0から1の間を取りうる値で、1で完全に予測的中、0.8以上で高い予測精度、0.7くらいまで許容範囲、0.5で全くランダムに予測しているのど同じ精度」
となります。
なので、先ほどのAUC 0.625とは、かなりイマイチな機械学習モデルだったことが分かったと思います。
目標の群馬スコアの精度は?

そもそも、目標の「群馬スコア」は本当に初期治療の抵抗性を予測できているのか、手元の196データに当てはめてみました。
すると、確かに
群馬スコアの4点をカットオフにすると、
感度が76%、特異度60%、AUCが0.68
と確かにある程度予測をしてくれそうだったので、この値を超えることを目標に機械学習モデルの精度を高めていきました。

今までの流れで、やっとこの①と②が終わったことになります。
次に僕は、⑤の色々な機械学習モデルを試して勉強することにしました。

今回使用してみた機械学習モデルを黄色の枠で囲いました。
機械学習モデルは図のように多数ありますが、今回のように「教師あり学習」で「初期治療の抵抗性があるかないか」を予想する場合は、左下に書いてあるようなモデルを使います。
つまり、用途によって機械学習のモデルも変わる、ということになります。
色々な機械学習モデルで試してみる

まずは「決定木モデル(ディシジョンツリー)」を試してみました。
これは機械学習モデルで一番有名な物のようで、
「適切な分類を繰り返すことによって、結果を予測する」ようなモデルです。
モデル自体の勉強は浅いので、モデル自体の説明は少なめにします笑
また、「多層パーセプトロンモデル」というニューラルネットワークと呼ばれるモデルの一種を使ってみましたが、
どちらもAUCは0.6台と低く、いまひとつの結果でした。
モデルを組み合わせる、アンサンブル

複数の機械学習モデルを組み合わせて、さらに精度の高い機械学習モデルを構築することを「アンサンブル」と呼びます。
アンサンブルの方法の中で一番有名な手法が「ランダムフォレスト」です
具体的には、
・元データから大量のサンプルデータを復元する
・そのデータを、たくさんの決定木モデルに学習させる
・たくさんの決定木モデルに目的変数を予想させる
・たくさんの予想を多数決して、最終的な予想を決める
という手順を踏みます。
この「ランダムフォレスト」という方法を導入したところ、
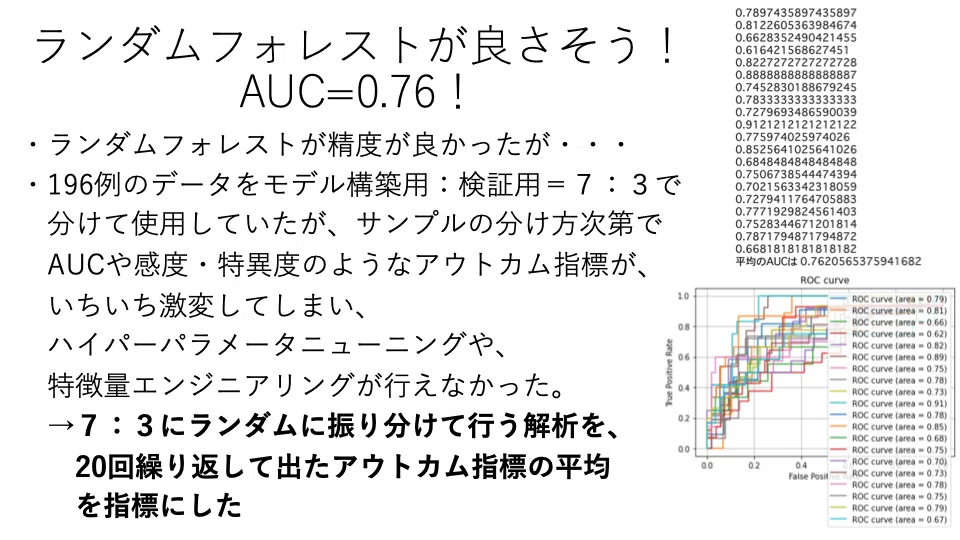
AUCが0.76と飛躍的に精度が上がりました!
このランダムフォレストを試している時くらいに「ある問題」に悩まされました。
こういった「予測モデル」を構築する際は、基本的に手元にあるデータを「機械学習モデル構築用」と「精度の検証用」の2つに分けて用いるのですが、
その分け方次第で「予測モデルの精度」が大きく変動してしまうため、なかなか細かいモデルの調整ができなかったのでした。
おそらく「データを取ってきて、データ数自体を増やす」というのが一番の正解なのですが、そういうわけにもいかないので、
ランダムにデータを2つに分けることを20回繰り返してモデルの精度を確認する、という方法で解決しましたが、もっといい方法があるかもしれません。
(一個抜き検証法はなぜかうまくいきませんでした。機械学習に詳しい方アドバイスをください笑)
特徴量エンジニアリング

モデルを一通り試した後に「特徴量エンジニアリング」に取り組みました。
特徴量エンジニアリングとは、すでにあるデータ(説明変数)を用いて、別の説明変数を作り出すことで、機械学習の精度を上げる方法です。
テクニックとしての特徴量エンジニアリング(説明変数と説明変数の掛け算で新たな説明変数を作ってみる、など)と、
「こういった変数が、結果を予測する上で価値があるだろう」と考えて新しく説明変数を作る方法があります。
具体的には、スライドに書いたような「CRPは遅れて上がる数値だから治療開始日で割って、CRP/daysという新しい説明変数を作ると意味があるはずだ」のような作り方です。
この特徴量エンジニアリングが機械学習の精度をあげる上で、一番個人の差が出ると言われています。

僕もたくさん試してみましたが、結局は「CRP×血沈」という炎症を示す採血結果の掛け算の項目のみ、大きく機械学習の精度がのびました。
それ以外の項目では精度が下がってしまったので、採用しませんでした。
(この特徴量エンジニアリングもまだまだ改善の余地がありそうです。)
ハイパーパラメータの設定

機械学習のモデルには「ハイパーパラメータ」と言われる人間が設定しないといけない設定値があります。
僕が用いた「ランダムフォレスト」は、元が「決定木モデル」なので、
max_depth:分類の回数(ツリーの深さ)の制限
min_samples_leaf:ツリーの葉に含まれる最小のサンプル数
などといった数字を決めないといけません。
この人間が決めないといけないハイパーパラメータの決め方は、
・手動で決める
・ハイパーパラメータすら決めてくれるフレームワーク(便利グッズみたいなもの笑)を利用する
などの方法があります。
手動で決める時も、繰り返し構文(for構文)を利用して少しでも楽をしたり、グリッドサーチと言われる交差検証法と繰り返しを同時に使う方法などが知られています。
今回の僕は、for構文を用いて原始的な方法で、一番AUCが高くなるハイパーパラメータを探しました笑
Light GBMとは

今、機械学習の予測モデル界隈で、騒がれているフレームワーク(便利ツール)が「Light GBM」です。
最初の方で説明した、実際に課題をこなしながら精度を競う「コンペ」の中で、世界中に参加者を持つKaggleという有名コンペがあるのですが、ここ数年で上位入賞者が多用していることでこの「Light GBM」が有名になりました。
このLight GBMでは、大量に復元したデータを使ってたくさんの機械学習モデルに学ばせるところまでは「ランダムフォレスト」と似ているのですが、
ブースティングといって、たくさんの学習モデルに前の結果を反映させながら学ばせる方法を取っています。
また、実務的には「欠損値」も情報として学んでくれるので、欠損値の埋め方や扱い方も迷う必要がなくなります。
僕も導入してみましたが、AUC 0.696とランダムフォレストに比べて精度が低かったです。
このLight GBMのポテンシャルを引き出せないまま研修の1ヶ月がすぎてしまったので、今後試行錯誤する必要があります。
機械学習モデルの統合(アンサンブル)

この段階では、ランダムフォレスト単体が一番精度が高いですが、
機械学習の予測モデルを作るときには「機械学習モデルの統合」を行うと精度がさらに上がることがあります。
僕も一番初歩的な「3つのモデルの平均をとる」という方法を試してみましたが、
精度はAUC 0.745と悪くはないですが、精度が上がるということはありませんでした。
現時点での、機械学習モデルの精度

これまでの試行錯誤を終えた、現時点での機械学習モデルの精度を共有します。
機械学習モデルとしては「ランダムフォレスト」を用いており、
特徴量としては「CRP×血沈」という項目だけ新しく作成しました。
ハイパーパラメータは、max_depth=7, min_samples_leaf=6にしました。
その予測モデルで、
感度 73.35%、特異度 68.15%、AUC 0.762
でした!
群馬スコア(4点カットオフ)で、
感度 76%、特異度 60%、AUC 0.68
なので、一応精度としては既存の予測スコアを上回ったということにさせてください!笑
(実際は、自分のデータだけで学ばせているので過学習になっているだけの可能性は残っています)
機械学習モデルでの項目ごとの重要度

最後に、いくつかの機械学習モデルでは、機会学習における「項目の重要度」を可視化することができます。
やはり上位は「CRP_max」「CRP*ESR(血沈)」「month」「WBC(白血球)_max」「Na_min」などと、
臨床的にも炎症が高いと(重症だと)より上下する検査値が多く含まれており、妥当なモデルな印象を受けました。
「若手小児科医による経験ゼロからの、機械学習による予測モデル作成の道」は、以上になります!!!
もちろん、1ヶ月しか学んでない上に、データ数もそこまで多くないので、
出来上がった機械学習モデルは、とても限定的な機械学習モデルになっています。(機械学習モデル自体の稚拙さは自覚してるので、批判はやめてください笑)
しかし、それでも、
機械学習が医療現場に良い影響を与えそうな未来や、
実際に医療従事者が機械学習を学んでいく時の道のりが、
より具体的に想像できるような文章になったのではないかなと自負しています。
実際に、医師として機械学習を学んでみて感じた、医師であることの強みは、
①機械学習の技術で解決できそうな、臨床的に意味のある課題を思いつくことができる
②臨床のデータを集めることができる、データを集める仕組みを作りやすい
③豊富な背景知識を用いた、特徴量エンジニアリングをすることができる
の3点ですかね!
詳しい機械学習の方法に関しては、もっと詳しい人がたくさんいるので、そういった人に任せるのが良い気がしました笑
それでもやはり、医師が技術を学んで「どうにか医療をよくできないか」と考えることは、とても価値があることだと感じました!
それでは、
・AIや機械学習に興味のある医師/医療関係者の方
・機械学習を医療現場への応用してみたい機械学習を学んでいる方
ぜひ、一緒に勉強していきたいので連絡ください!
特に、今回のnoteを読んで「ここをこうしたら良い機械学習モデルになるよ!」みたいなアドバイスを待ってます!
よろしくお願いします!
いいなと思ったら応援しよう!
