
メモ化だけならtupleじゃなくてもよかった話【数学パズルの延長戦】

「プログラマ脳を鍛える数学パズル」という本に載っている問題を解いてる中で、メモ化をすることがよくあります。
先日、その中の問題の1つで複数の変数を探索のログとして残す問題がありました。そこでtupleを使ってメモ化実装を試みたのですが、処理時間が想定以上に長くなったため、tupleを諦めて別の方法での実装を行いました。
このnoteではその原因の確認としてpairやtupleを使うと処理時間がどのように変化するのかを検証します。気になる方は最後のほうだけでも見ていってください。いいねと思ったらぜひスキよろしくお願いいたします!
実行環境はpaiza.ioを使いました。
pairと2つのvectorの速度比較
10^7個の数を作成する処理時間を比較しました。
結果
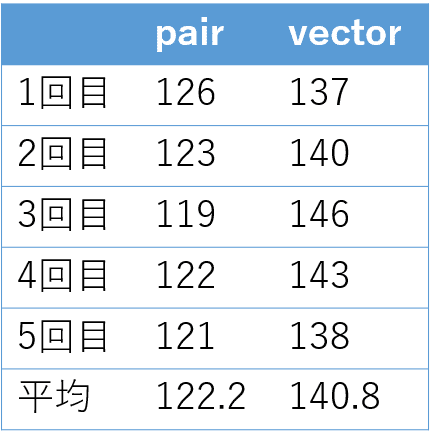
結果は以下の図のようになりました。単位は全てミリ秒です。約20ミリ秒ですが、pairの方が早いという結果になりました。
pairのコード
#include <bits/stdc++.h>
using namespace std;
int main(void){
std::chrono::system_clock::time_point start, end;
start = std::chrono::system_clock::now();
std::vector<std::pair<int,int>> test;
for(int i=0;i<10000000;i++){
std::pair<int,int> t=std::make_pair(i,i+1);
test.push_back(t);
}
end = std::chrono::system_clock::now();
double elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end-start).count();
std::cout << elapsed << std::endl;
}vectorのコード
#include <bits/stdc++.h>
using namespace std;
int main(void){
std::chrono::system_clock::time_point start, end;
start = std::chrono::system_clock::now();
std::vector<int> a,b;
for(int i=0;i<10000000;i++){
a.push_back(i);
b.push_back(i+1);
}
end = std::chrono::system_clock::now();
double elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end-start).count();
std::cout << elapsed << std::endl;
}tupleと3つのvectorの速度比較
こちらも同様に10^7個の数を作成する処理時間を比較しました。
結果
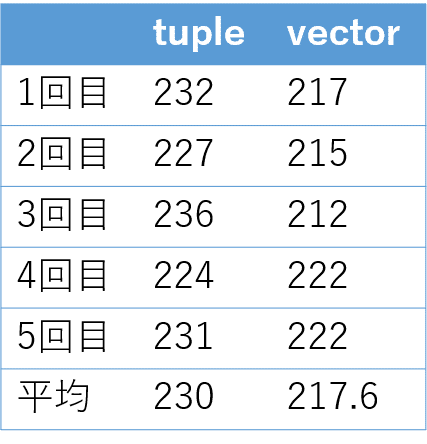
結果は以下の図のようになりました。単位は全てミリ秒です。こちらは約15ミリ秒ほどですがvectorのほうが早いという結果になりました。
tupleのコード
#include <bits/stdc++.h>
using namespace std;
int main(void){
std::chrono::system_clock::time_point start, end;
start = std::chrono::system_clock::now();
std::vector<std::tuple<int,int,int>> test;
for(int i=0;i<10000000;i++){
std::tuple<int,int,int> t=std::make_tuple(i,i+1,i+2);
test.push_back(t);
}
end = std::chrono::system_clock::now();
double elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end-start).count();
std::cout << elapsed << std::endl;
}vectorのコード
#include <bits/stdc++.h>
using namespace std;
int main(void){
std::chrono::system_clock::time_point start, end;
start = std::chrono::system_clock::now();
std::vector<int> a,b,c;
for(int i=0;i<10000000;i++){
a.push_back(i);
b.push_back(i+1);
c.push_back(i+2);
}
end = std::chrono::system_clock::now();
double elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end-start).count();
std::cout << elapsed << std::endl;
}ここまでのまとめ
各結果だけを見て分かるようにpairとtuple両方ともvectorと比較して、作成だけでは処理時間はほとんど変わらないということが分かりました。
では、参照に時間がかかるのでは?と考え、次に参照の比較を行ってみました。
参照の比較
作成した配列に対して、ランダムな100個の数字を検索してみました。
(*注意:この方法で本当に比較できているのか自信ないです…)
結果
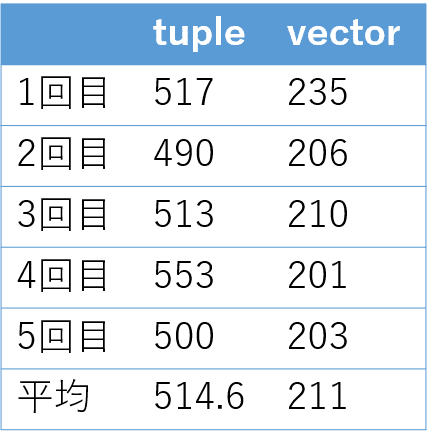
結果は以下の図のようになりました。単位はすべてミリ秒です。約2倍の差があることがわかりました。データの数が多いので当たり前と言えば当たり前ですが、tupleのほうがかなり時間がかかることが分かりました。
tupleのコード
#include <bits/stdc++.h>
using namespace std;
int main(void){
std::chrono::system_clock::time_point start, end;
start = std::chrono::system_clock::now();
std::vector<std::tuple<int,int,int>> test;
for(int i=0;i<10000000;i++){
std::tuple<int,int,int> t=std::make_tuple(i,i+1,i+2);
test.push_back(t);
}
start = std::chrono::system_clock::now();
std::random_device seed_gen;
std::mt19937 engine(seed_gen());
start = std::chrono::system_clock::now();
for (int i = 0; i < 100; i++) {
int r=engine()%10000000;
for (tuple i : test) {
if(get<0>(i)==r){
break;
}
}
}
end = std::chrono::system_clock::now();
double elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end-start).count();
std::cout << elapsed << std::endl;
}vectorのコード
#include <bits/stdc++.h>
using namespace std;
int main(void){
std::chrono::system_clock::time_point start, end;
std::vector<int> a,b,c;
for(int i=0;i<10000000;i++){
a.push_back(i);
b.push_back(i+1);
c.push_back(i+2);
}
std::random_device seed_gen;
std::mt19937 engine(seed_gen());
start = std::chrono::system_clock::now();
for (int i = 0; i < 100; i++) {
int r=engine()%10000000;
for (int i : a) {
if(i==r){
break;
}
}
}
end = std::chrono::system_clock::now();
double elapsed = std::chrono::duration_cast<std::chrono::milliseconds>(end-start).count();
std::cout << elapsed << std::endl;
}まとめ
メモ化のためだけにログとして残すだけならpairやtupleを使う必要はないことがわかりました(pairの比較は省略しましたが、tupleと同様の結果がでました)。
ただし、pairやtupleを使うと簡単にsort()を行うことができるため、何をするかに応じて使い分ける必要があります。
この記事が気に入ったらサポートをしてみませんか?