
生成AI用パソコンとしてパーフェクトなMacBook Pro M4

MacBook Proが新しくなり、Apple M4ファミリー搭載となった。発表にもあった「生成AIに最適」アピールはそのとおりで、Youtuberによる先行レビューなどを待たなくても、仕様をみるだけでその完成度の高さが伝わってくる。
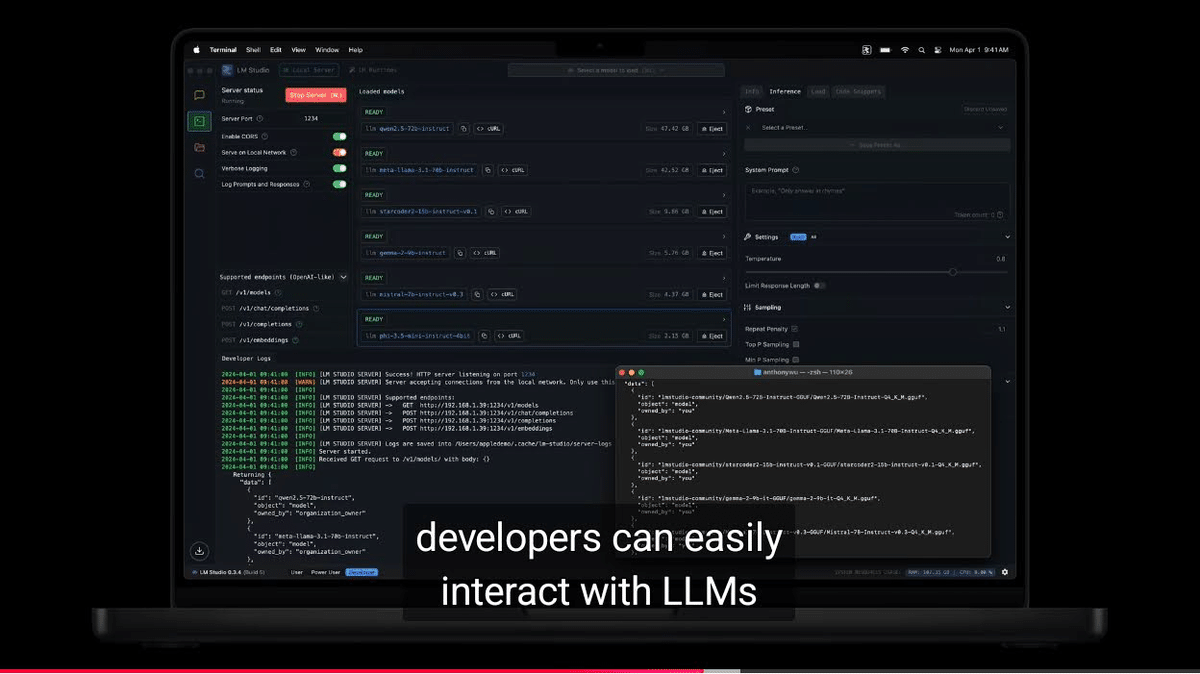
これまでもMacBook Proの発表ではMATLABなど機械学習について触れられることはあったが、LLM限定ながら生成AIは初めて。公式リリースにある「デベロッパは約2,000億(200b)のパラメータを持つLLMを簡単に操作できます」は、毎月何百万円と引き換えにデータセンターのリソースを借りるような、そして借りたくても空きがないような、現在もっとも要求の厳しいLLMのワークロードさえ、14型のMacBook Proでほいほい扱えることを意味する。このアップルの主張を、信者なら話半分で聞き、私などがもっと割り引いて聞いたとしても、とんでもないことだ。
そんな新しいMacBook Proは、Windowsのハイエンドなゲーミングノートパソコンと比べても、生成AIで必要なVRAM容量は引き続き圧倒し、M4 Maxのメモリ帯域幅はついにハイエンドのNVIDIA RTX 4090 Laptopと「並んだ」。M4 Proのメモリ帯域幅も、ゲーミングだけでなく生成AI入門用として人気の高いNVIDIA RTX 4060 Laptopと「並んだ」。

そして、以前のApple Mシリーズは「ほとんど変わり映えしない、あるいはユーザーを大いに落胆させる」アップグレードにとどまっていたが、M4はメモリ帯域幅を惜しみなく拡大させ、コア数も理想的な数にシンプルに整理された。このアーキテクチャ、大絶賛されたM1で実は完成しちゃってて、これ以上の伸びしろはないのでは?と私も思っていたが、M4は原点というのか、M1の頃に立ち返り、地味ながらも新たな次元で仕切り直しする役割を果たしたように見える。
図はMacBook AirとMacBook Proに搭載されたMシリーズを、メモリ帯域幅とGPUコア数の軸でプロットしたもの。「g20c」は「GPUが20コア」を表す。ぱっと見でもわかるように、M4 ProとM4 Maxは、根っこからのスペックアップを果たした。

この図を操作して遊べるものも、リンクしておく。
また、Apple Siliconは、そもそもとして美しいアーキテクチャーを備えている。それも、生成AI時代を見据えていたかのように。
WindowsでGPUになにか処理をさせるには、まずCPUでSSDからRAMにデータをロードし、そのあとで内部バス経由でRAMからGPUのVRAMにデータをコピーする。WindowsのファイルシステムであるNTFSは「前世紀の設計」ゆえSSDに最適化されているとはいえず、SSDからRAMへのデータロードほど非効率な処理もないのだが、このステップは避けられない。もちろん、CPUとメモリ、GPUはそれぞれ物理的に別のパーツとしてボードに取りつけられ、外部の配線を介してつながっている。つまり、メモリは重複して使われ、電力をムダ食いし、遅い。
Apple SiliconでGPUになにか処理をさせるには、SSDからメモリにデータをロードするだけで終わる。いったんメモリに置かれたデータはGPUだけでなく、CPUからも、NPUからも同じように扱える。iOSやMacOSのファイルシステムであるAPFSは「SSDが前提」なので、大きなサイズのデータロードもWindowsよりだいぶ効率的だ。そして、CPUとGPUとメモリはたったひとつのパッケージに統合されている。つまり、メモリは必要な分だけ使われ、ムダな処理はなく、速い。

WindowsではAMD APUなどCPUとGPUを統合したチップも人気が高い。が、基本的にメモリはパッケージに統合されていない。インテルの最新世代であるCore Ultra 200Vのようにメモリもパッケージに統合されていたとしても、そのメモリ帯域幅はやっとM4の無印と同じくらいで、統合チップの99%はそれよりもずっと狭い(遅い)。もちろん、Apple Siliconにある「メモリ帯域幅をシンプルにスケールさせる」仕組みはどこにもない。それについてAMDやインテルを変えさせるのは無茶であり、自分を変えるほうが手っ取り早い。私のように「遅さに慣れる」とか。
また、生成AI用にデータをロードする際の流れは、GPU統合型でも、NVIDIAを外付けにした場合と変わらない。CPUとGPUから使うメモリは物理的には同じチップだが、CPU用とGPU用とで区画をきっちり分けて使う。よって、GPUでなにか処理をするには、やっぱりCPU用のメモリ領域からGPUのメモリ領域(VRAM)へデータをコピーしなくてはならない。
例外といっていいのか、NVIDIAはCPU(Arm)とGPU、メモリをパッケージにした「Grace Hopper Superchip」を出している。GH200とか「Grace HopperのGH」がつく型番だ。とはいえ、これでWindowsのArm版を動かすわけではなく、スパコン専用だ。そのうえ、メモリはApple Siliconのようには統合されておらず、CPU用のメモリとGPU用のVRAMとでまったく異なる規格を採用しつつパッケージするという、かなりの力ワザで実現している。

あとは、マイクロソフトも「SSDのデータをNTFSを介してRAMに展開して、それをGPUのVRAMにもっていく」流れが美しいとは思っておらず、「SSDのデータを、NTFSを介さず、GPUのVRAMに直接ロード」するAPIであるDirectStorageを広めようとしている。

DirectStorageを使うことで「データロードの時間が30分の1に短縮される」といった実測もある。が、実はDirectStorageはビデオゲーム用のAPIで、圧縮されたテクスチャデータをSSDからVRAMに渡してGPU側で展開するなどの複雑な処理も担うため、単にデータをSSDからVRAMにロードする場合がどうなのかがいまいちわからない。
生成AIのLLM界隈でも、DirectStorageの話題は「たまに」出ては消える。Linuxにも似たような取り組みがあるとかで実装を実験的におこなってはいるが、「ファイルシステム配下にはない、つまりOSから認識できないGPU専用データ」をどう扱っていくのかが壁になっている...…ような気がする。
とまあ、NVIDIAやマイクロソフトの最先端の取り組みを見守るにしても、それらはすでにApple Siliconで、もっとも洗練された設計で完成をみている。Apple Siliconは、生成AIに必要なあれこれを、結果として先どっていた。それも、データセンターやデスクトップにとじこめておかず、14型のMacBook Proで持ち運べるようにしたのは、何物にも代えがたい。1000Wの電源で、電気ファンヒーター「強」運転のような熱を出しながら動くデスクトップのNVIDIAはずっと高性能かもしれないが、そこに美しさはないよねと。
というわけで、生成AIの特にLLM界隈では新しいMacBook Proが、より一層もてはやされるだろう。MacBook Proには、同じM4 ProながらMac miniにはあるメモリ64GBの設定が「なぜか」省かれて「64GBが欲しければMax一択」にアップルのいつもの闇を感じなくもないが、NVIDIAのハイエンドGPUと同じメモリ帯域幅になるならと納得もできそうだ。
