No.11:発話中の脳波から文章を再構成する

「人間の皮質脳波(外科手術のために脳に直接置いたシート上の電極(ECoG)から計測した脳波)を用いて、その人が話している文章をコンピュータ上で再構成する」という内容の論文がNature neuroscienceに2020年3月に掲載されたので、まとめてみました。(実際に読んだのは無料で読めるbioRxiv版)
この研究で言いたいこと
・encoder-decoder framework がBMIとして文章生成に役立つ
(人間の文字起こしと同じレベルの文字起こしが脳波からできる)
・通常の音声認識で用いられる音素ベースではなく、単語ベースでの学習という新規性
・転移学習による他者間でのデータ活用の有用性
背景
ここ10年で、BMI(ブレインマシンインターフェイス)に関する研究はサルからヒトへ移行してきた。
この研究と同様に、脳に電極を埋め、話した言葉をコンピュータ上で文字起こしする研究もすでにおこなわれてきている。
しかし、これまでの研究では再構成の精度は40%程度であり、実用的なものではなかった。
手法
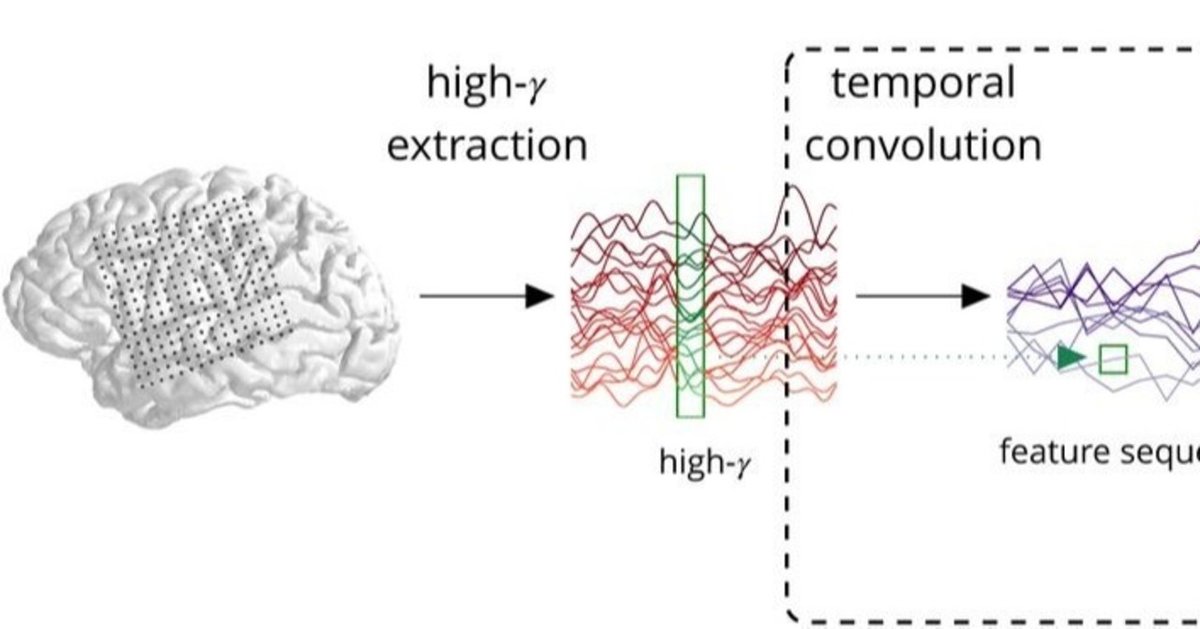
この研究では、再構成の精度を向上させるため、異なる言語間での翻訳に使われる機械翻訳アルゴリズム(encoder-decoder model)を導入し、言語と言語ではなく、脳波と言語での翻訳をおこなった。
実験では、ECoGが挿入されているてんかん患者4人(全員女性)に対し、写真を説明した短文30個、もしくはデータセットの短文50個×9セットを読み上げてもらい、その時の脳波を計測した。

計測した脳波は下処理として70~150Hzの高周波帯(high-γ)のみを使用し、200Hzのヒルベルト変換をおこなった。(ヒルベルト変換よくわからない...)その後畳み込みをおこない、16Hzにダウンサンプリングしたものを特徴量とし、Neural Networkへの入力とした。

Neural Networkはencoder RNNとdecoder RNNの2つのネットワークで構成されている。(encoder-decoder RNNについてもよくわからない...)
・encoder RNN では実際の発話音声をMFCC(メル周波数ケプストラム)に変換したものをターゲットとし、MFCCの予測をおこなう。
・decoder RNN ではその予測によって得られたモデルをもとに、実際の文章のテキストをターゲットとして、テキストの予測をおこなう。
結果
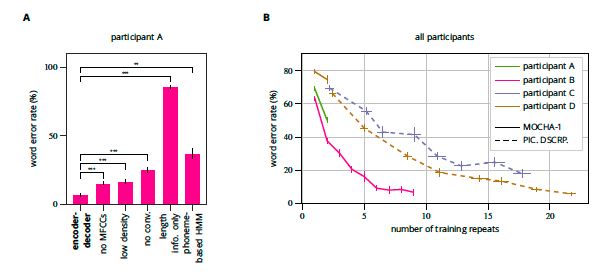
実際に読み上げたテキストとRNNで予測したテキスト間の誤字率(WER:word error rate)は、一番良い結果で7%だった。(上図A:左から1番目)
人間のプロが書き起こすテキストのWERが5%であり、音声認識の許容ラインとしては20〜25%と言われていることを考慮するとかなりいい結果であることがわかる。
実際、同じデータに対して音素ベースの隠れマルコフモデル(HMM)を用いて予測した結果のWERは37%だった。(上図A:左から6番目)
また、どの要素が予測に寄与しているかをしらべるために、予測にMFCCを使わないパターン(上図A:左から2番目)、電極数を減らしたパターン(上図A:左から3番目)、畳み込みによるダウンサンプリングをおこなわないパターン(上図A:左から4番目)をおこない、それぞれが効果的であることがわかった。
さらに、文の構造を学習し、テキストを予測しているのではなく、文の長さを学習し、テキストを分類しているだけである可能性を排除するために、それぞれの文と同じ長さのガウシアンノイズをテストデータとして予測を行ったところ、あきらかにWERがおおきくなった。(上図A:左から5番目)
しかし、予測精度には個人差が見られた(上図B)
そこで、データ数を増やすために転移学習(transfer learning:すでに学習済みのモデルに追加でデータを学習させる手法)をおこなった。
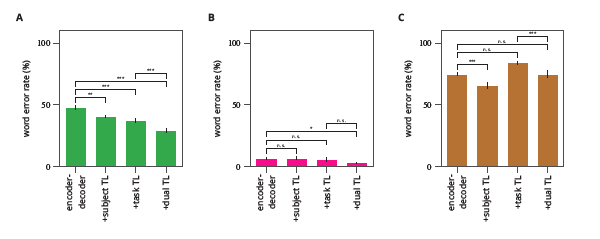
まず、予測精度があまり高くなかったparticipantA(上図A:左から1番目 WER:48%)に対し、3パターンの転移学習をおこなった。
・participantBで事前学習したモデルにparticipantAのデータで追加学習させた結果、ベースライン(WER:48%)から15%程度精度が向上した。(上図A:左から2番目)
・participantAの学習に使わなかった410個のデータを2回くりかえし学習させ、さらに残りの50データをテストとした時、精度はベースラインから22%向上した。(上図A:左から3番目)
・participantBの410データを学習したモデルにparticipantAの410データを追加学習させたところ、精度はベースラインから39%向上した。(上図A:左から4番目)
次に、予測精度が最も高かったpaticipantBに対し、同様の転移学習をおこなった。その結果、participantAの410データを学習したモデルにparticipantBの410データを追加学習させ、それにたいしてparticipantBの残りの50データでテストを行った場合、WERは3%と非常に高い予測率を示した。(上図B)
議論
・この手法では数少ない文の構造を学習しているだけであり、言語的な規則を学習しているわけではない。そのため、実際に実験においてもあきらかに異なる文章や意味の通らない文章を生成してしまった。
しかし一方で、文だけでなく単語を学習しているため、新しい文に対して汎用的に使うことができる。
・今回の研究で脳の特定の領域が関連していることを解剖学的に明らかにすることはできなかった。
・臨床患者で日常的にECoGを挿入している患者であれば、発話に基づくデータは大量に計測することができ、大量の語彙と柔軟性を獲得できる。
また、すでに話すことができず、MFCCを獲得することができなくても、精度は低下するが、極端に精度が落ちるわけではないことも明らかになった。
このことから、encoder-decoder frameworkはBMIでの文章生成に応用することができるだろう。
ーーーーーーーーーーーーーーーーーーーーーーーーーー
読んだ感想
そんな簡単に、しかもこんな高精度で予測なんてできないだろ...
「いままで40%くらいだったのが、3%になりました!!」って...
いくらECoGでも喋ってるときの筋活動とかノイズとしてのっているのではないだろうか...
まぁでも、この研究チームはいつも面白い研究を出してくれるので読みがいがある。毎回そんなことあり得ないだろ...とは思いつつ、natureに1年に何本も論文が出てきて本当にすごい。facebookがスポンサーみたいな噂聞いたな。。
最近、脳×人工知能が一般化していろんなところでBMIの話が展開されているけど、巷の情報に踊らされないでちゃんと情報と向き合わないとな...と思いました。
この論文も「念じていることが文章になる」みたいな文脈で取り上げているサイト多いしな...
そんなことより、信号処理とか勉強しないと全然この手の論文読めない。
RNNの構造もいまいちよくわかってない。勉強します。
解釈等変なところがあったら、是非ご指摘ください。
以上。ありがとうございました。