AWS Certified Machine Learning - Specialty 対策学習

1.はじめに
こちらは、学習に活用したUdemyの教材になります。
日本語でのユースケースを基に問題が提示されています。
とても便利なので、活用させていただいています。
https://www.udemy.com/course/aws-30-b/learn/quiz/5433622/result/914784894#overview
今回は、自分の整理を第一にユースケースを基にどんなサービスをどのように使ったら良いかを説明します。
2-1.適切なコンピューティングリソースの確保と適切なタイミングで動かす
EC2などでコンピューティングリソースを確保しますが、
使用用途に応じて適切なCPUやメモリを確保する必要性があります。
その中で、スポットインスタンスなどが存在します。
スポットインスタンスとは
スポットインスタンスは、AWS(Amazon Web Services)の一種のEC2(Elastic Compute Cloud)インスタンスタイプのことで、非常に低価格で提供されます。スポットインスタンスは、AWSの未使用のコンピューティング容量を活用して、余剰容量を割引価格で提供します。
スポットインスタンスの価格は、AWSのマーケットプレイスにおいて、現在の需要と供給に応じて決定されます。需要が高まると、価格が上昇する可能性がありますが、逆に需要が低下すると、価格が下がることがあります。そのため、スポットインスタンスは、長時間実行する必要のない、非常に変動するワークロードや、高可用性が必要でない場合に最適です。
ただし、スポットインスタンスは、AWSが必要に応じてインスタンスを終了することがあり、それによって作業が失われる可能性があるため、スポットインスタンスを使用する場合は、データのバックアップと回復戦略を確実に行う必要があります。
スポットインスタンスの料金は、数時間から数日を要するトレーニングジョブを実行している深層学習の研究者や開発者のために、高性能 GPU を手頃で利用しやすいものにしています。
ただし、AWSが必要に応じてインスタンスを終了することがあるため、対策を講じる必要があります。
それにAWS Batchというものが存在します。
AWS Batchを使用することによって、自動的に再開をすることが可能になっております。
インスタンスが中断し、ジョブが失敗した場合でも自動で再実行されます。
2-2.Kinesis :S3に供給されるデータが増えなくなった。
Iotデバイスなど、機械学習で使用するデータを取得するデバイスがあったとします。
そのデータを取り込むAWSサービスがAmazon Kinesis Data Streamになります。
取り込んだデータはKinesis Data Firehoseを通じてS3のデータレイクに保存するとします。
あるとき、Iotデバイスからストリーミング処理をした際に
本来であればデータレイクに投入されるデータが増加するはずが
増加していないことに気がついたとします。
さらに、Kinesis Data StreamsやKinesis Data Firehoseで取り込むべきデータのバックログが増加しています。
そんな時は、データストリームのシャドー数を増やすことが大きなベストプラクティスになっています。
Kinesis Data Streamsに送信されるデータは増加している一方で、S3に保存されるデータは増加していないので、
Kinesis Data Streamsのキャパシティに問題があると推測します。
ストリームのデータ容量は、複数のシャドーによって決まっており
各シャードは、読み取りに対して最大 5 トランザクション/秒をサポートし、最大合計データ読み取りレートは 2 MB /秒、最大合計データ読み取りレートは 1,000 レコード、最大合計データ書き込みレートは 1 秒あたり 1 MB(パーティションキーを含む)までサポートできます。
つまり、今回の場合に関しては
シャドー数を増やすことがベストプラクティスになるということです。
2-3.より、最新の顧客のユーザーの思考を掴もう
Amazon Personalizeでは、過去のユーザーの行動によるアイテムとのインタラクションデータを元にしたレコメンドが可能になっています。
ユーザーやアイテムは毎日増えるものなので、それらに対応できるように日次や高頻度でレコメンド内容を更新したいと思います。
Amazon Personalizeはイベントトラッカーという機能でイベントを収集する機能があり、イベントデータが追加されることで、キャンペーンによるリアルタイムレコメンドに反映させることができます。
2-4.Sagemakerでセキュアな分析環境を作ろう
Sagemakerでデータを分析する際は、S3にバケットに保存されたデータにアクセスを行い、分析を行うことが一般的なユースケースになっています。
基本的に、SagemakerノートブックからS3にアクセスする際は、
一度インターネットに接続する
(SagemakerノートブックがパブリックVPCにあればインターネットゲートウェイ、プライペートVPCにあればNATゲートウェイ)
必要があります。
より、強固なアクセスにするにはどのようにすれば良いかというと
VPCエンドポイントを使用します。
通常、VPC内のリソースは、インターネットゲートウェイやNATゲートウェイを使用してインターネットにアクセスしますが、VPCエンドポイントを使用することで、VPC内のリソースがプライベートネットワーク上に接続されたAWSサービスにアクセスできるようになります。これにより、セキュリティが向上し、インターネット上でのアクセスを必要としないため、コストも削減できます
なんとなく、Sagemakerをいじっていましたが
セキュリティ面はとても重要だと再認識しましたね。
2-5.Sagemakerを使用したA/Bテスト
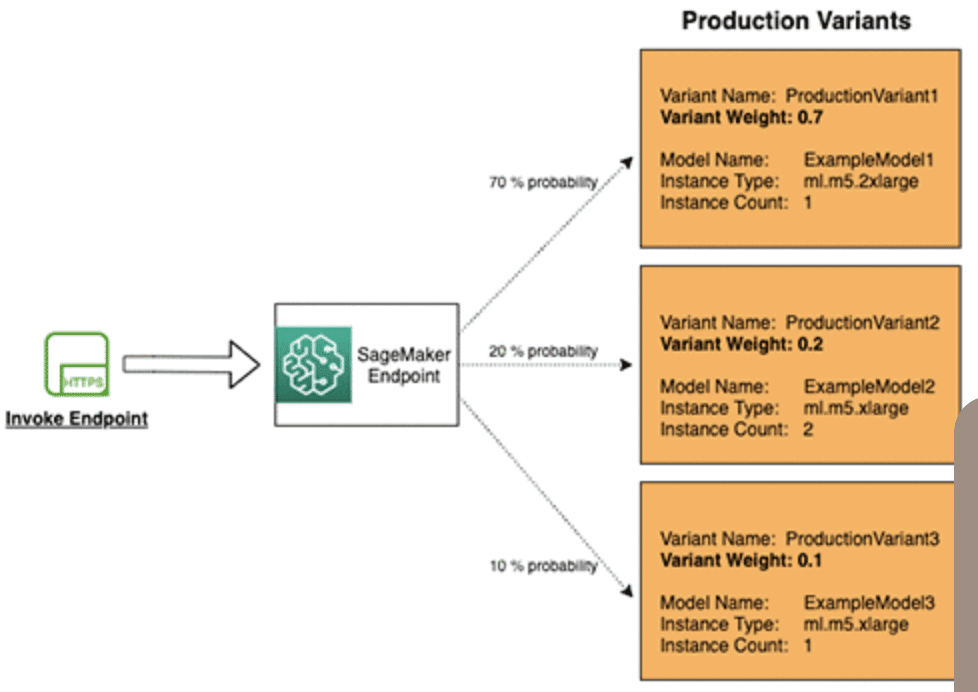
異なるハイパーパラメーターでどのモデルが良い精度が出るかを確認するA/Bテストがあるかと思います。
Amazon SageMakerでは、プロダクションバリアントを使用して、同じエンドポイントの後ろで複数のモデルまたはモデルバージョンをテストすることができます。
これにより、異なる環境で同じモデルを使用し、異なるユースケースに適した推論結果を得ることができます。
2-6.GPU関連のライブラリをコンテナ内で実行するようにしよう。
Amazon Sagemakerを使用してモデルをトレーニングするために、特注のResNetモデルをDockerコンテナに入れているとします。
その際に、NVIDIA GPUを使用するために、コンテナを効率的にセットアップしたいと考えているとします。
その際は、NVIDIA Container Toolkitを使用することが良いです
NVIDIA Container Toolkitは、GPUで高速化されたDockerコンテナの構築と実行を可能にすることができます。
また、その際に注意点として
コンテナにはCUDAツールキットのみを搭載し、NVIDIAドライバをイメージにバンドルしてはいけないそう。
2-7.学習に必要な時間を短縮とコストを節約したい
例えば、決定木ベースのアンサンブルモデルがあり
ハイパーパラメータチューニングプロジェクトを開始したとします。
24時間ごとに古いデータのクリックスルーをモデル化するために、毎晩ハイパーパラメータを再学習・最適化するパイプラインがあったとします。
これらの学習にはコストがかかるため
より学習時間を効率よくしたいと考えます。
その際は、
最大木の深さと評価指標の相関関係を示す散布図を可視化することが良いです。
2-8.Sagemakerノートブックの実態はどこにあるのか?
社内のプライペートVPC内にSagemakerノートブックインスタンスがあり、それを使用しているとします。
ある日、Amazon EBSボリュームのスナップショットをとる必要があり、EBSボリュームを探しましたが見つけることができなかった。
なぜでしょうか。
それは、Sagemakerノートブックインスタンス自体は、VPC内に実態があるわけではなく、
Amazon SagemakerのマネージドVPCで動作しており
つまり、AWSが管理しているマネージドVPC上に実態が存在しているがために、スナップショットが取れないのです。
2-9.Horovodを使って、分散学習させよう
ある企業の機械学習のスペシャリストは、TensorFlowベースの時系列予測モデルのトレーニングペースを上げたいと考えています。現在、トレーニングは1台のGPUを使って行われており、完了までに約16時間かかっています。毎日トレーニングを行わなければなりません。
モデルの精度には満足しているが、学習時間がかなりネックになっていると感じています。
その際は、
Horovodを使って、分散学習させることが良いとされています。
Horovod は、分散型深層学習のためのオープンソースフレームワークです。
TensorFlow および他のいくつかのディープラーニングフレームワークで使用できます。
2-10.Sagemakerノートブックインスタンス上でネイティブにアクセスできないいくつかのPythonパッケージを手間なくインストールしよう。
Sagemakerノートブック上で、標準にないライブラリをインストールしたいとき、pipコマンドを用いればライブラリはインストールすることが可能です。
が、ノートブックインスタンスを停止して、再起動したらそのライブラリの情報は消えてしまいます。
またインストールするなどは、かなり手間なので
その際は、Sagemakerのライフサイクル構成を作成し、ノートブックインスタンスにライフサイクル構成を割り当てることで、
追加したライブラリは維持されます。
2-11.Amazon Forecastを用いて最適な時系列分析を行う
Amazon Forecastは、時系列データを使用して、需要予測、売上予測、在庫予測、トラフィック予測など、様々なビジネスシナリオで予測を行うことができます。また、Amazon Forecastは、データの前処理、特徴量エンジニアリング、モデルトレーニング、ハイパーパラメータ最適化など、予測モデルの作成に必要な一連の処理を自動的に行うことができます。
例えば、ある倉庫に保管されている1つの商品についての在庫予測を行ったとします。
Forecastを用いて3年分の月次データを使って予測モデルを作成したとします。
ただし、評価指標である平均絶対誤差(MAPE)は、かなり大きいことが問題でした。
その際は、
PerformAutoMLをTrueに指定してあげることによって
最適なアルゴリズムを設定してくれます。
また、最適なパラメーターにおいては
PerformHPOをtrueに設定します
そうすることによって、性能向上が見込まれる可能性があります。
2-12.Kinesis Data Analyticsを用いて、異常検知をする
あるデータサイエンティストは、ストリーミングのオンライントラフィックデータを取り込むためのパイプラインを構築しています。
このパイプラインの一部として、データサイエンティストは、異常なWebトラフィックパターンを識別する技術を構築する必要がある。
その際に、用いることができるのが
Kinesis Data Analyticsの
Amazon Random Cut Forestになっています。
詳しいアルゴリズムは不明ですが、
データストリームの異常を検出します。 レコードが他のレコードと離れている場合、異常となります。
データ自体は各レコードで保存されるので、何かしらのアルゴリズムで異常検知ができるのでしょう。
気が向いたらアルゴリズムを漁ってみます。
2-13.コールセンターのカスタマーサービスの向上をする Amazon Transcribe
カスタマーサービスの質を高めるために、電話応対者の音声記録から意味のある洞察を得たいとします。
ただし、電話相手は英語を話す人もいればスペイン語やフィリピン語など多岐に渡ります。
その際には、Amazon Trancribeを用いて、音声をテキスト化します。
その後、Amazon Translate(ニューラル機械翻訳)を使用して英語以外のテキストを英語に翻訳し、
最後にAmazon Comprehend(自然言語処理サービス)を使用して分析を行う
このサービスなどは、完全フルマネージドサービスであるため、
独自のモデルをデプロイしたりトレーニングしたりする必要がありません。
2-14.パイプモードを使用して、学習開始時間を高速化する
Sagemakerでモデル学習などを行う際は、学習データがあるS3のプレフィックスにアクセスし、データを取得して学習を行います。
動画解析などにおいては、非常にデータ容量が大きいので
より早くデータのストリーミングを高速にすることが必要です。
基本的には、ローカルのAmazon Elastic Block Storeボリュームにデータをダウンロードするファイルモードが一般的だが、
パイプモードを使用することによって、大幅に優れた読み取りスループットを提供することができる。
実際にも
その結果、78 GB のトレーニングデータセットで開始時間が最大 87% 短縮されたことが分かりました。
さらに、一部のベンチマークではスループットが 2 倍に向上し、合計トレーニング時間が最大 35% 短縮されることが分かりました。