
とりにくさんのCoppyLora_WebUIを使って、好きなモデルで自分画風LoRAを作りたい(2024/11/9加筆)

この記事でできるようになること
【とりにくさんのローカル版CoppyLora_webUIで、好きなモデルで自分画風LoRAを作ることができるようになる】
※2024/11/9 追記
とりにくさんより、新しいCoppyLora_webUI _V2が2024/11/6に公開されました!
好きなベースモデル、好きな画像の組み合わせで簡単に画風LoRAが作れる『CoppyLora_webUI_V2』Google colabノートブックとローカルビルド版fanboxにて限定公開!|とりにく @tori29umai #note https://t.co/2Jv0SJp7H3
— とりにく (@tori29umai) November 6, 2024
ベースモデル対応の希望があった為、詳細学習モードを追加しました。
これを使うと、本項で解説しているのとほぼ同じことが、とくに設定ファイルやコマンドライン操作をせずに実施することができます。素晴らしいネ。
また本項では初代Coppy_webUIの設計仕様(ベースモデル画像が変更できない)と意図に配慮してベースモデル画像の変更について詳細には触れなかったのですが、新版Coppy_webUI_V2ではベースモデル画像も変更できるようになっています。悪用厳禁です!ご自身の創意を発揮するためにご使用くださいね。
それでも本項を残すメリット?…それは…
学習パラメータを変更する方法のとっかかりがわかる
コマンドラインでバッチ実行することでまとめて何個もLoRAをいっぺんに学習させられる
あたりかなあ。
はじめに
とりにくさんが公開されている「CoppyLora_webUI」は、とても簡単な操作で自分の画風LoRAを作れる便利なツールです。ツール側で用意しているベース画像に対して、その画像を自分の画風で描きなおした画像を用意して処理をさせることで、自分の画風の特徴を抽出したLoRAを作ることができます。
実際私も登場以来利用していますが、なかなか良い感じに効くLoRAを作ることができます。
こんな雑絵で学習効いてるのか?と、同一プロンプト同一シードのLoRA有無で一枚。きかしてる方はウェイト0.7#aiart
— 資材部の懲りない面々 (@FET_SHIZAIBU) June 28, 2024
これよりウェイトあげると、絵柄の特徴以上に、「学習させた画像にどう書いてあるか」が効いてきてしまう感じする https://t.co/u9W2xjQRyP pic.twitter.com/pLHHSS9gpR

ただ、ツール内部がAnimagineXL3.1向きに作られているため、AnimagineXL3.1でない別のモデルでは効きが悪い場合があります。(マージモデルの場合、マージの配合度合いにもよります)
しかし私は最近、ぶるぺんさんによるマージモデルIllustrious_pencil-XL1.1.0を試しているのですが、このモデルに対して、このLoRAの効きはかなりよろしくありません。(内部的にAnimagineXL3.1の要素成分が少なめだからと考えられます)


少女「…今、何かしたか?」
私自身AnimagineXL3.1はタグの受付け方と仕上がりが好みではあるのですが、使い勝手がいいものがあるなら他のcheckpointもあたってみたい、と考えていましたので、これはなかなか悩ましい問題です。
ほかのモデルに対しても、自分LoRAを作れるといいな…!が、今回の目標となります。
CoppyLora_webUIの仕組みを理解する
CoppyLora_webUIは、ローカルビルド版こそ有償公開となっていますが、そのソースコードは公開されています。
内部の処理の流れはコピー機LoRA作成の方法に準じています。
コピー機LoRA作成法はさまざまな解説がありますが、たとえば以下が参考になります。
以降、ツールとしての動作の詳細を簡潔にまとめます。
(1)事前準備(セットアップ段階)
CoppyLora_webUIは、実行フォルダ内部に以下を同梱(あるいはインストール段階でダウンロード)して保有しています。
AnimagineXL3.1モデル
ベース画像がそのまま出力されるように過学習されたもの(copi-ki-base-c.safetensors)
ベース画像から主線を除去した画像が出力されるように過学習されたもの(copi-ki-base-cnl.safetensors)
ベース画像をグレースケール化したものが出力されるように過学習されたもの(copi-ki-base-b.safetensors)
ベース画像から主線を除去した画像をグレースケール化したものが出力されるように過学習されたもの(copi-ki-base-bnl.safetensors)
キャプションテキスト
カラー画像と組み合わせて学習に使うもの (grayscale_g.txt)
モノクロ画像と組み合わせて学習に使うもの (color_g.txt)
ユーザー入力画像の学習設定パラメータファイル config.toml
(2)学習の準備(実行初期段階)
ユーザーの素材画像と、モード設定に従い、学習データをフォルダに配置します。
train_dataフォルダ内に「4000」と名付けたフォルダを作成する。
その中に、ユーザー入力画像(1024x1024px)を1024.pngとして配置。さらに768x768pxに縮小したものを768.png、512x512pxに縮小したものを512.pngとして配置する。
モード設定にしたがって、キャプションテキストを「4000」フォルダにコピーする。モード設定がLineartやGrayscale系の場合はcolor_g.txtを、逆にColor系の場合はgrayscale_g.txtを、1024.txt、768.txt、512.txtとしてコピーする。
(3)過学習LoRAの作成
ユーザー入力画像がそのまま出力される過学習LoRAを、config.tomlの設定に従って作成します (copi-ki-kari.safetensors)。
(4)差分LoRAの作成
ここが肝になりますが、(3)で作ったcopi-ki-kari.safetensorsと、ベースの過学習LoRA4種のどれか1つを選んで、特徴を抽出するため差分を取ります。
モードがLineartやGrayscale no lineの場合 copi-ki-base_c.safetensors
モードがGrayscaleの場合 copi-ki-base_cnl.safetensors
モードがColorの場合 copi-ki-base_bnl.safetensors
モードがColor no lineの場合 copi-ki-base_b.safetensors
差分を取ったモデルをcopi-ki-merge.safetensorsとします。
(5)リサイズして完成
LoRAのサイズを調整して、ユーザーの命名に従ったLoRAを完成します(mylora.safetensors)。
ということは…(作業方針)
ベースで使用する過学習LoRAを、「好みのモデル」で作り直して、
CoppyLora_webUI内のモデルファイルを「好みのモデル」に置き換えて、
CoppyLora_webUI内のベース過学習LoRAを、1.で作ったものに置き換えれば、
目的を実現できそうじゃないですか?
ベースとなる過学習LoRAを作り直す
ここからは、kohyaさんのsd-scriptsが使える環境であることを前提に作業していきます。
kohya's GUIが入っている環境で、コマンドプロンプトが動けば、それで大丈夫です。ですが今回はGUIは使いません(設定項目が多すぎて、オリジナルのLoRAと設定を合わせにくいため)。
最近は、いろいろ考えなくてもさくっと環境を構築できるStability Matrixがあれば簡単に準備できます。当方この環境なので、その前提で以下実施内容を書いていきます。
(もちろん、別途sd-scriptsを直接ご用意いただいてもかまいません)
インストールは、たとえば以下を参考にしてみてください。
学習に用いるベース画像と、学習用のフォルダを用意しましょう。どこかに適当に”train_data”というフォルダを作成し、その中に”4000”というフォルダを作成してください。私は、"kohya-ss\outputs"フォルダの中に作りたいLoRA名(今回はcopi-ki-base-c)のフォルダを作成し、その中に設置しました。この4000という数字には学習パラメータ上の意味があるので、ほかの名前に変えないようにしてください。
以下のような構成にする想定で、説明していきます。もちろん適宜、お手元の環境にあった内容に読み替えてください。
<kohya_ss>─<outputs>─<copi-ki-base-c>─┬─<train_data>───<4000>─┬─ 1024.png
│ ├─ 1024.txt
│ ├─ 768.png
│ ├─ 768.txt
│ ├─ 512.png
│ └─ 512.txt
├─ config.toml
├─ training.bat
└─ (出来上がったLoRAがここに出力される)”4000”フォルダの下には、とりにくさんの用意しているベースモデル画像に"1024.png"と名前をつけて入れましょう。さらにそれを、一辺768pxに縮小したものを”768.png”、512pxに縮小したものを”512.png”として収納します。
さらにキャプションのテキストファイルを同梱します。今回はカラー画像ですので、「色についての記述を抜いた」プロンプトで学習する必要があります(学習させたくない概念だけで構成されたプロンプト、とします)。こちらもとりにくさんのご用意しているものがあります(”grayscale_g.txt”)ので、これを名前を変えてコピー("1024.txt", "768.txt", "512.txt")し、"4000"フォルダの中に入れます。
差分抽出の原理から考えれば、ベースとなるLoRAは、差分計算の相手になるLoRAと同じ学習設定で学習されていたほうがいいような気がします(気がする、だけではあるんですが)。ということで、基本設定のconfig.tomlはCoppyLora_webUI付属のconfig.tomlをコピーし、改造することで準備することにします。
config.tomlの中身は以下のようになっています。
pretrained_model_name_or_path = "models/animagine-xl-3.1.safetensors"
train_data_dir = "train_data"
output_dir = "models"
output_name = "copi-ki-kari"
max_train_steps = 1000
network_module = "networks.lora"
xformers = true
gradient_checkpointing = true
persistent_data_loader_workers = false
max_data_loader_n_workers = 0
enable_bucket = true
save_model_as = "safetensors"
lr_scheduler_num_cycles = 4
learning_rate = 0.0001
resolution = "1024,1024"
train_batch_size = 2
network_dim = 16
network_alpha = 16
optimizer_type = "AdamW8bit"
mixed_precision = "fp16"
save_precision = "fp16"
lr_scheduler = "constant"
bucket_no_upscale = true
min_bucket_reso = 64
max_bucket_reso = 1024
caption_extension = ".txt"
seed = 42
network_train_unet_only = true
no_half_vae = true
cache_latents = true
cache_latents_to_disk = true
cache_text_encoder_outputs = true
cache_text_encoder_outputs_to_disk = true書き換えるべきは上の4行、
"pretrained_model_name_or_path" … 使いたいモデルの場所を指定
"train_data_dir” … 作成した <train_data> を指定、
"output_dir" … 出来上がったLoRAを出力させたい場所を指定、
"output_name" … LoRAにつけるファイル名を指定(今回はcopi-ki-base-cとする)
です。それぞれ、自分の使用したいモデルや環境・フォルダ構成に合わせて書き換えましょう。
相対パスで書いてますが、もちろんフルパスでもかまいません。
pretrained_model_name_or_path = "../../../../Models/StableDiffusion/illustriousPencilXL_v110.safetensors"
train_data_dir = "./train_data"
output_dir = "./"
output_name = "copi-ki-base-c"
max_train_steps = 1000
network_module = "networks.lora"
xformers = true
gradient_checkpointing = true
persistent_data_loader_workers = false
max_data_loader_n_workers = 0
enable_bucket = true
save_model_as = "safetensors"
lr_scheduler_num_cycles = 4
learning_rate = 0.0001
resolution = "1024,1024"
train_batch_size = 2
network_dim = 16
network_alpha = 16
optimizer_type = "AdamW8bit"
mixed_precision = "fp16"
save_precision = "fp16"
lr_scheduler = "constant"
bucket_no_upscale = true
min_bucket_reso = 64
max_bucket_reso = 1024
caption_extension = ".txt"
seed = 42
network_train_unet_only = true
no_half_vae = true
cache_latents = true
cache_latents_to_disk = true
cache_text_encoder_outputs = true
cache_text_encoder_outputs_to_disk = trueうちの場合、ベースモデルがStabilityMatrixのモデルフォルダの中にいるので、パス指定がちょっと深いです。皆さんの環境にあわせて書き換えてください。今回は前の章でお話ししたとおり、illustrious_pencil-XL1.1.0を使います。ほかのお好みのモデルでも、同じように作業できると思います。
"training.bat" の中身は次のようにしてください。…すまんね、この記事はWindows用なんだ…(情報くださったとりにくさんに多謝!)
call "..\..\venv\Scripts\Activate.bat"
accelerate launch ^
--num_cpu_threads_per_process 12 ^
"..\..\sd-scripts\sdxl_train_network.py" ^
--config_file=".\config.toml"
ここまで準備したら、"training.bat" をダブルクリックして実行しましょう。
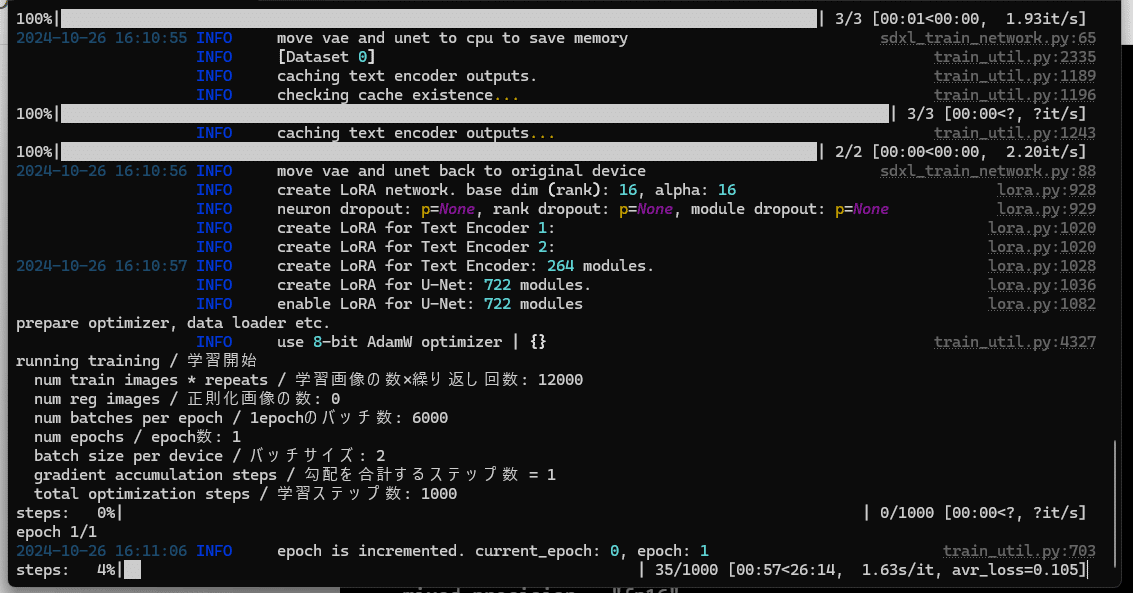
こんな風に、学習が開始すれば成功です。(ハイパワー・ハイメモリなGPUが要るから覚悟してね!)
※えー? コマンドぽちぽちするのやだよー。という人は、頭をひねると、たぶんCoppyLora_webUI本体のtomlを書き換えながら実行すれば、copi-ki-kariを作る処理を流用して作れちゃうとは思う…
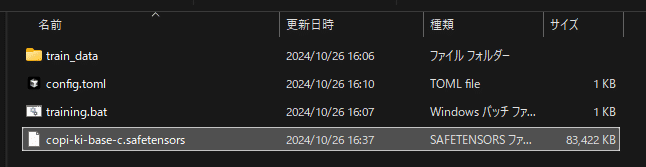
できあがりました。
この記事執筆のために追試しましたが、RTX3090使って25分ほど。なかなかのGPU廃熱で、部屋の温度が1度あがりました(笑)。冬にはいいですね。
これを、copi-ki-base-cnl(カラー、主線なし)、copi-ki-base-b(グレースケール)、copi-ki-base-bnl(グレースケール、主線なし)に対しても同じように実施します。
主線なし画像は、とりにくさんがx上のポストで投稿しているものが適用できるはず…jpgだからちょっとオリジナルより劣化してるかもしれないけど…
bとbnl用画像は、上記の2枚に対して適当なソフトで彩度を失わせる処理をすればOKです。bとbnlを学習するときは、キャプションファイルは"color_g.txt"を使用してください。
【参考】さて、この学習パラメータですが、
フォルダに3枚の画像がある
フォルダ名は4000(繰り返し学習数の指定)
エポック数はconfig.toml上に指定がなく、1
ということで、本来3×4000×1=12000ステップの学習なんですが、
max_train_stepsが1000
のため、1000ステップで打ち切られて終了、となるようになっています。
(これを4000ステップくらいまでやらせるとどうなるのか?…というあたりは試行錯誤課題と思います…)
CoppyLora_webUIの中身を書き換える
CoppyLora_webUIローカル版の中身のファイル配置は以下のようになっています。
<CoppyLora_webUI>─┬─<_internal>──────────┬─ (動作に必要な環境、ライブラリやコード)
│ :
│
├─<caption>────────────┬─ color_g.txt
│ └─ grayscale_g.txt
├─<models>─────────────┬─ animagine-xl-3.1.safetensors
│ ├─ base_c_1024.png
│ ├─ copy-ki-base-b.safetensors
│ ├─ copy-ki-base-bnl.safetensors
│ ├─ copy-ki-base-c.safetensors
│ ├─ copy-ki-base-cnl.safetensors
│ ├─ (copy-ki-kari.safetensorsが中間出力される)
│ └─ (merge_lora.safetensorsが中間出力される)
├─<output>─────────────── (出来上がったmylora.safetensorsが出力される)
├─<train_data>
├─ config.toml
├─ CoppyLora_webUI.exe
├─ CoppyLora_webUI_DL.cmd
└─ CoppyLora_webUI_ReadMe.txt以下のファイルを作成したものに置き換えます。(オリジナルは別のフォルダに保管するなどして取っておきましょう。再ダウンロードも可能ですが…)
copi-ki-base-c.safetensors
copi-ki-base-cnl.safetensors
copi-ki-base-b.safetensors
copi-ki-base-bnl.safetensors
また、config.tomlを以下のように書き換えます。(これもオリジナルは別のフォルダに保管するなどして取っておきましょう。再ダウンロードも可能ですが…)
今回書き換える場所は1か所だけ、使用するベースのモデルファイルのみです。
pretrained_model_name_or_path = "C:\StabilityMatrix\Data\Models\StableDiffusion\illustriousPencilXL_v110.safetensors"
train_data_dir = "train_data"
output_dir = "models"
output_name = "copi-ki-kari"
max_train_steps = 1000
network_module = "networks.lora"
xformers = true
gradient_checkpointing = true
persistent_data_loader_workers = false
max_data_loader_n_workers = 0
enable_bucket = true
save_model_as = "safetensors"
lr_scheduler_num_cycles = 4
learning_rate = 0.0001
resolution = "1024,1024"
train_batch_size = 2
network_dim = 16
network_alpha = 16
optimizer_type = "AdamW8bit"
mixed_precision = "fp16"
save_precision = "fp16"
lr_scheduler = "constant"
bucket_no_upscale = true
min_bucket_reso = 64
max_bucket_reso = 1024
caption_extension = ".txt"
seed = 42
network_train_unet_only = true
no_half_vae = true
cache_latents = true
cache_latents_to_disk = true
cache_text_encoder_outputs = true
cache_text_encoder_outputs_to_disk = true今回は絶対パスで書いてみました。もちろん、相対パス指定でも構いません。これで、準備が整いました。
CoppyLora_webUIを実行する
実行時の見た目はなにも変わりません。さっそく学習してみましょう。

出来上がったLoRAを使って、テストしてみます。

オリジナルの状態で作ったLoRAを適用した場合と異なり、はっきりと変化が表れていることがわかります。
もちろんこのツールは、「特徴の差分を学習する」ものなので、画風だけでなく、「キャラクターの髪型」とか「色の塗り方」とかも、工夫次第で学習させることができます。
とりにくさんのCoppyLoRA_webui。
— 資材部の懲りない面々 (@FET_SHIZAIBU) October 23, 2024
illustriousPencilXL用のcopi-ki-base-cnl, b, bnlも作ってみた。おそらくbnlを使用してると思われるフルカラーの素材を使ったLoRA作成を試す#AIArt pic.twitter.com/xrwxcSoelb

いまいち水彩塗りが弱い感じするんだけど、counterfeitXLで塗ったこの辺つかったらうまく覚えたりしない? #aiart pic.twitter.com/cqZd2GjNBO
— 資材部の懲りない面々 (@FET_SHIZAIBU) October 25, 2024

これで、好きなモデルで画風の学習をさせられるようになりました。
Appendix.コマンドでマージとリサイズもやっちゃう
「ソースコード見ただけで全部わかっちゃいましたよ!」と言えればよかったんですがそうもいかず、結局とりにくさんがご厚意でいろいろご指南くださいました。のですが、そのなかに、マージとリサイズをするコマンドもありましたので、CoppyLora_webUIが行う「画風作成」も、sd-scriptsで実施が可能とすることができました。簡単に構成を紹介します。
以下のような構成で行うことを想定します。
<kohya_ss>─<outputs>─┬─<mylora>─┬─<train_data>───<4000>─┬─ 1024.png
│ │ ├─ 1024.txt
│ │ ├─ 768.png
│ │ ├─ 768.txt
│ │ ├─ 512.png
│ │ └─ 512.txt
│ ├─ config.toml
│ ├─ training.bat
│ ├─ (copy-ki-kari.safetensorsが中間出力される)
│ ├─ (merge_lora.safetensorsが中間出力される)
│ └─ (出来上がったmylora.safetensorsが出力される)
├─<copi-ki-base-b>───── copy-ki-base-b.safetensors
├─<copi-ki-base-bnl>─── copy-ki-base-bnl.safetensors
├─<copi-ki-base-c>───── copy-ki-base-c.safetensors
└─<copi-ki-base-cnl>─── copy-ki-base-cnl.safetensorsまずご自分が用意した画像の過学習を行う必要がありますので、<train_data>フォルダを"copy_ki_base-c.safetensors"の作り方を参考に用意して、学習画像("1024.png","768.png","512.png")とキャプションファイル("1024.txt","768.txt","512.txt")を配置してください。
たとえば学習画像が白黒線画の場合は、キャプションファイルの中身には"color-g.txt"のほうを使用します。
config.tomlは、自分の学習画像を過学習したLoRA(copi-ki-kari.safetensors)を作成する際のパラメータとして使用しますので、次のようにします。
適宜ご自身の環境に読み替えてください。
pretrained_model_name_or_path = "../../../../Models/StableDiffusion/illustriousPencilXL_v110.safetensors"
train_data_dir = "./train_data"
output_dir = "./"
output_name = "copi-ki-kari"
max_train_steps = 1000
network_module = "networks.lora"
xformers = true
gradient_checkpointing = true
persistent_data_loader_workers = false
max_data_loader_n_workers = 0
enable_bucket = true
save_model_as = "safetensors"
lr_scheduler_num_cycles = 4
learning_rate = 0.0001
resolution = "1024,1024"
train_batch_size = 2
network_dim = 16
network_alpha = 16
optimizer_type = "AdamW8bit"
mixed_precision = "fp16"
save_precision = "fp16"
lr_scheduler = "constant"
bucket_no_upscale = true
min_bucket_reso = 64
max_bucket_reso = 1024
caption_extension = ".txt"
seed = 42
network_train_unet_only = true
no_half_vae = true
cache_latents = true
cache_latents_to_disk = true
cache_text_encoder_outputs = true
cache_text_encoder_outputs_to_disk = truetraining.batは次のようにします。前半は一緒ですね。
後半でマージ処理、続いてリサイズ処理を行っています。
call "..\..\venv\Scripts\Activate.bat"
accelerate launch ^
--num_cpu_threads_per_process 12 ^
"..\..\sd-scripts\sdxl_train_network.py" ^
--config_file=".\config.toml"
python ..\..\sd-scripts\networks\sdxl_merge_lora.py ^
--save_to ".\merge_lora.safetensors" ^
--models ".\copi-ki-kari.safetensors" "..\copi-ki-base-c\copi-ki-base-c.safetensors" ^
--ratios 1.41 -1.41 ^
--concat ^
--shuffle ^
--save_precision bf16 ^
--precision float
python ..\..\sd-scripts\networks\networks\resize_lora.py ^
--save_to ".\mylora.safetensors" ^
--model ".\merge_lora.safetensors" ^
--new_rank 16 ^
--new_conv_rank 16 ^
--save_precision bf16 ^
--device cuda ^
--verbose
マージ相手は、仕組みの解説で書いた通りのルールで選定するといいです。
もちろん、違う組み合わせにも可能性はあります!(差としていったい何の特徴が取り出せるか、ですので!)