食べログ問題。悪評削除の噂は本当か?

食べログ問題が一盛り上がりして、現在はある程度落ち着いていますが、食べログ本体は疑惑を否定するリリースを出し、結局のところ疑惑が本当だったのかは公正取引委員会の調査を待つところといった感じです。そこで、私なりに調べたことをまとめておこうと思います。
大きく話題になっている疑惑
大きく議論になっている疑惑は以下の2つだと思います。
①食べログ点数操作疑惑
②悪評削除疑惑
①は色んな方がツイートするなどしている問題で、曰く3.8点あった点数が突然3.6点に下げられ、課金すれば元の点数に戻すと食べログに言われたという問題です。
これはガチの方がスクレイピングをして因果推論してみたりとされていましたが、結局の所食べログ側の採点アルゴリズムがはっきりしない以上なんとも言えないというのが今の所の結論ではないでしょうか?
②はこちらもいくつかツイートが拡散されていました。明らかに違う店の口コミを削除してくれと食べログに問い合わせたところ、課金すれば削除に応じると言われたという問題です。
これは裏を返せば課金している店舗の口コミ削除要請に食べログが応じているということになります。口コミ削除が可能ということは悪評を削除して意図的に自店舗の評価を上げることが可能になる可能性があります。
今回はこれを検証してみたいと思います。
データの準備
例のごとくデータをスクレイピングしました。
東京のエリア1~14の店舗を点数順に1200位まで取得し、その点数の分布も取得しました。
エリアというのは食べログのURL(https://tabelog.com/tokyo/A1301/)にA1301というコードが含まれていますがこの数字の末尾2桁がエリア指定になっています。
1~14は、銀座・新橋・有楽町、東京・日本橋、渋谷・恵比寿・代官山、新宿・代々木・大久保、池袋~高田馬場・早稲田、原宿・表参道・青山、六本木、赤坂・永田町・溜池、飯田橋、秋葉原・神田・水道橋、上野、両国、築地・湾岸・お台場、浜松町・田町・品川が含まれています。
例によってデータを添付しておきます。
こちらと後述のコードで再現可能かと思いますので、皆さんも好きな条件でデータを分析してみてください。
なお、スクレイピングした時点のデータですので現状と異なる場合があります。
検証
データが揃ったので検証していこうと思います。
点数に関しては、食べログの採点アルゴリズムがわからない以上どうにもならないのですが、ズバリ悪評の削除が行われている可能性を探ります。
ここからはコードも一緒に書いていくので興味ない方は読み飛ばして下さい。
とりあえずデータをロードしておきます。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import csv
import json
with open("tabelog.csv") as f:
reader = csv.reader(f)
header = next(reader)
data = [[float(row[3]),int(row[6]),int(row[8]),row[9]] for row in reader]それぞれの点数帯の店舗の評価がどのように分布しているか確かめておきます。
def score_to(dic):
return [int(dic["1.0"]),int(dic["1.5"]),int(dic["2.0"]),int(dic["2.5"]),int(dic["3.0"]),int(dic["3.5"]),int(dic["4.0"]),int(dic["4.5"]),int(dic["5.0"])]
fr=4.5 #score from
to=5.0 #score to
border=50 #amount of scores
list_a=np.array([score_to(json.loads(i[3])) for i in data if i[0]<=to and i[0]>fr and i[1]>border])
h = [1.0,1.5,2.0,2.5,3.0,3.5,4.0,4.5,5.0]
print(len(list_a))
for i in list_a:
plt.plot(h,i/sum(i))
plt.title(f"from {fr} to {to}")
plt.legend()
plt.show()まずは4.5点以上の店舗です。
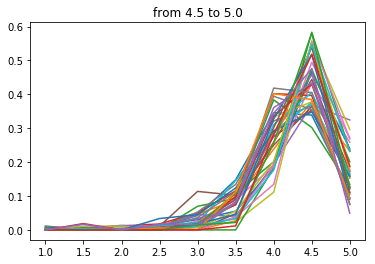
さすがですね~。
基本的に食べログ4.5点以上の店舗は多くの人が4.5点以上の評価をつけている店舗と言えそうです。
次に4.0点~4.5点
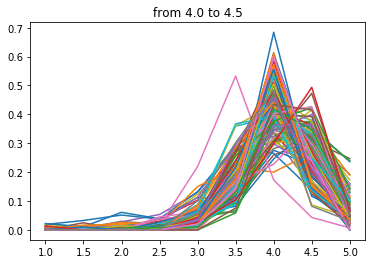
こちらも見事に4.0がボリュームゾーンですね。
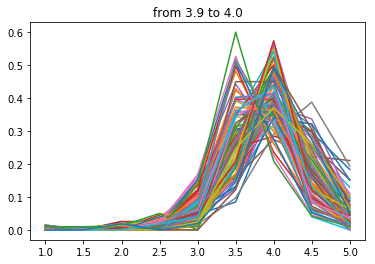
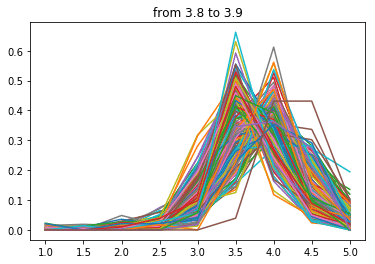
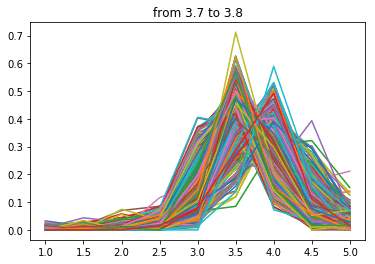
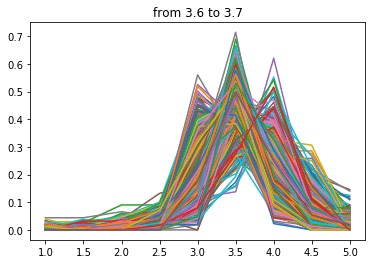
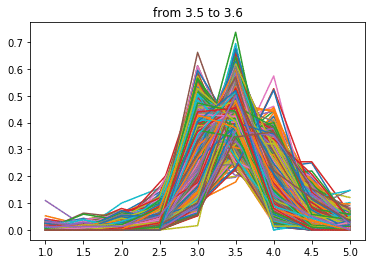
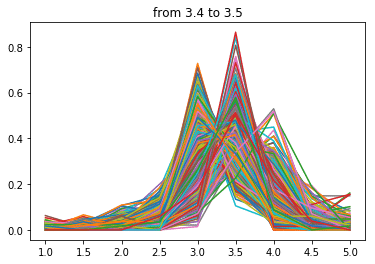
点数が下がるにつれ分布の中心が左にずれていく気がします。
当然といえば当然ですが、逆に言えばこの分布を右にずらす、つまり低い点数の口コミを減らせば自店舗の点数を上げることができると言えると思います。
では、課金すれば本当に悪い口コミを消せるのか?逆に操作された痕跡がないかを見てみます。
課金非課金ででデータを分けて点数の分布を集計してみます。
def score_to(dic):
return [int(dic["1.0"]),int(dic["1.5"]),int(dic["2.0"]),int(dic["2.5"]),int(dic["3.0"]),int(dic["3.5"]),int(dic["4.0"]),int(dic["4.5"]),int(dic["5.0"])]
fr=4.5 #score from
to=5.0 #score to
border=50 #amount of scores
list_p=np.array([score_to(json.loads(i[3])) for i in data if i[0]<to and i[0]>=fr and i[1]>border and i[2]])
list_np=np.array([score_to(json.loads(i[3])) for i in data if i[0]<to and i[0]>=fr and i[1]>border and not i[2]])
print(len(list_p))
print(len(list_np))
sum_p=np.sum(list_p,axis=0)/np.sum(list_p)*100
sum_np=np.sum(list_np,axis=0)/np.sum(list_np)*100
h = np.array([1.0,1.5,2.0,2.5,3.0,3.5,4.0,4.5,5.0])
plt.plot(h, sum_p, linewidth=1, color="red",label='paid')
plt.plot(h, sum_np, linewidth=1, color="blue",label='not paid')
plt.title(f"from {fr} to {to}")
plt.legend()
plt.show()まずは4.5点以上の店舗
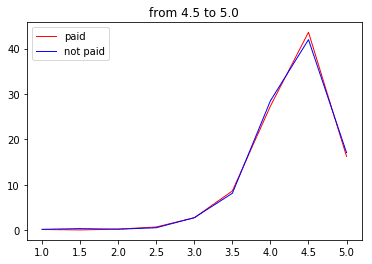
このゾーンはそもそも対象の店舗が35店舗しか存在しないので信憑性にかけますが、課金に関係なくほぼ分布が一致しています。
次に4.0点以上
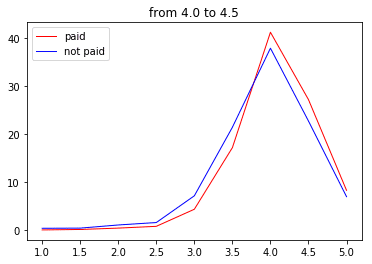
なにか妙なことが起きてしましました。
このゾーンは118店舗が該当しますが、なぜか課金店舗のほうが非課金の店舗より4.0点以上の口コミの占める割合が多くなっています。
そして4.0点以下の部分がえぐり取られたような形に…
なんでだろ~(棒
次に3.9点~
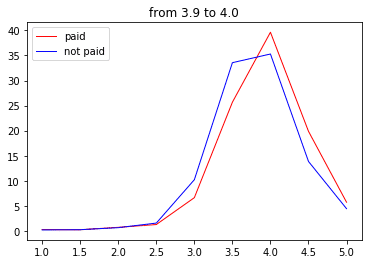
ぐ、偶然だよぉ~・・・
次に3.8点~
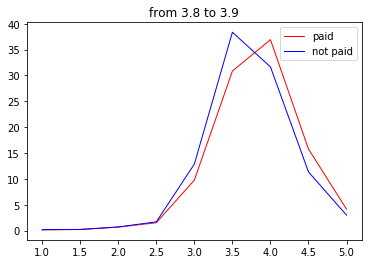
わーい夫婦岩だぁ〜(遠い目
次は3.7点~
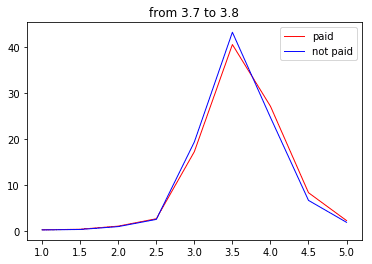
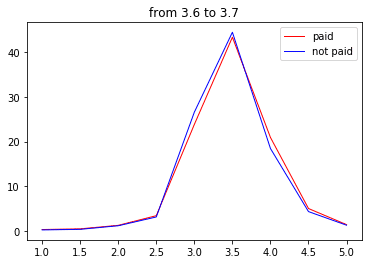
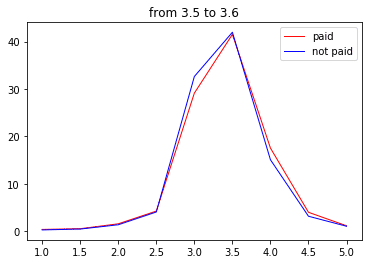
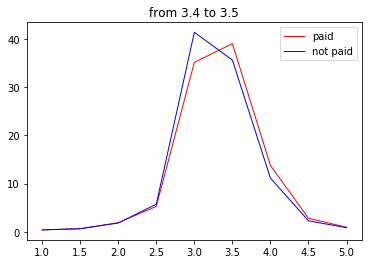
・・・・・・・・・・・
はい、というわけで分布が完全一致?しましたので口コミの削除は無いことがわかりました(白目)
(完)