
AIを用いると、フェイスブックのデータで、その人の人格を推定できる

回帰分析は、昔から用いられてきたデータ分析の手法だ。説明変数xと、被説明変数yの間に、一次の関係 y=ax+bがあると仮定し、x、yの観測値から最小二乗法を用いて係数a、bを求める。重回帰分析では、説明変数として複数の変数を用いる。
最近では、SNSなどのデータを用いて、個人のプロファイリングを行なうことが試みられている。
プロファイリングとは、ある人がどのような特性をもっているかを推測することである。例えば、性別、人種など。また、趣味や嗜好など、さらには思想なども推測する。
マイケル・コシンスキーは、フェイスブックで人々が何に「いいね」をつけているかを分析してプロファイリングを行なう研究を行なった。
この成果は、2013年4月、米国科学アカデミー紀要(PNAS)に発表されている。
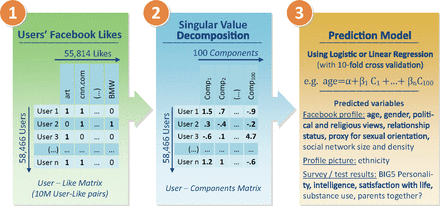
図1 コシンスキーの分析
http://www.pnas.org/content/110/15/5802
図1は、コシンスキーの分析を示す。
1は、データだ。58,466人について、55,814のウエブサイトに関する「いいね」の状況を示している。例えば、1番目のユーザーは、アートとcnnのサイトには「いいね」をつけているが、BMWのサイトには付けていない。
2は、このデータをComponentという変数に変換する。これによって、説明変数の数は100に減少する。
3では、Componentを説明変数にして、人種、性別、政治的志向、宗教、などを説明する回帰モデルだ。
分析の目的は、あるユーザーについての「いいね」のデータから、その人の人種、性別、政治的志向、宗教などを推測することである。
結果は、つぎのようなものだった。
コーカサス系(白人)かアフリカ系(黒人)は95%、男女は93%、民主党支持か共和党支持かは85%、キリスト教徒かイスラム教徒かは82%などの精度で、それぞれ区別できる。
ゲイ(88%)とレズビアン(75%)も特定できる。また、喫煙(73%)、飲酒(70%)、薬物使用(65%)、パートナーの有無(67%)も判別可能。
この方法によると、両親や配偶者が把握しているより正確に、人格が分かるという。
これらの中には、公表していないものもあるだろう(例えば、同性愛志向、あるいは薬物使用)。
しかし、何に「いいね」をつけているかを分析すれば、分かってしまうのだ。
これが「プロファイリング」である。
興味深いことがいくつもある。まず、明らかに相関がありそうな関係であるのに、そうでないものがある。例えば、ゲイの5%しか、同性婚のサイトに「いいね」をつけていない。
人格を示すのは、音楽やテレビ番組の好みなど、もっと広範で、一つひとつはあまり重要でないデータの集まりだ。
「ゴッドファーザー」「モーツァルト」「指輪物語」といった映画を好む者の知能指数が高いという結果は、納得できる。
しかし、一見したところ何の関係もないように思われるものが、強い相関を示すことがある。
例えば、カーリーフライ(カールしているフライドポテト)の投稿に「いいね」をつけるのは、IQの高い人が多い。
また、「怖がっているのは、君より蜘蛛だ」(Spider is More Scared Than U Are) というウエブページに「いいね」をつけるのは、非喫煙者が多い(Digital records could expose intimate details and personality traits of millions 、University of Cambridge)
このような相関があるという仮説を、理論モデルから導くことは、到底できないだろう。これらは、大量のデータをコンピュータで力任せで分析したことによって得られたものだ。なぜこのような相関があるかを説明することさえ、難しい。
これは、「モデルなし、 仮説なし。相関が見つかればよい」というデータ駆動型科学の方法論そのものだ。
ところで、フェイスブックの個人データが不正な方法で取得され、アメリカ大統領選挙で用いられたのではないかということが、問題となった。
米大統領選挙でトランプ陣営が契約していたデータ分析会社ケンブリッジ・アナリティカ(CA)が、フェイスブック利用者約5000万人の個人情報を不正収集していたと報道された。
CAは、ビッグデータに基づく心理学的属性(サイコグラフィックス)を分析するコンサルティング会社。ケンブリッジ大学の計量心理学(サイコメトリックス)研究所のメンバーによって2013年に設立された。
2016年のイギリスのEU離脱を問う国民投票では離脱派、米大統領選ではドナルド・トランプ氏の陣営のコンサルタントになった。どちらの選挙でも勝利をおさめたことから、注目を浴びた。
ここで問題とされたのは、データの入手方法だ。
取得方法は確かに問題だが、データサイエンスの進歩によって、上記のように、データからプロファイリングすることが可能になっているという点が重要だ。