
115【有料で学んだこと】MENTAでshota.kokado@Python/AWSさんに教わったこと④ SUUMOさんスクレイピング発展編

こんにちは!TechCommitメンバーの友季子です。
今回の記事では、MENTAでshota.kokado@Python/AWSさんに教わった、SUUMOさんを例にスクレイピングするコツについて発展編をシェアします。
スクレイピングの学習をするお仲間のお役に立てれば幸いです。
ご相談内容
「私 SUUMOさんのスクレイピングの技術をもうすこし色々ご指導ください!」※ざっくりこんな感じ
SUUMOさんのURL
ご教授いただいたこと
読みやすさを考慮し、一部修正して記載します。
レッスン
…実際のセレクタの指定方法はサイトの特徴によって変わってきてしまいます。
スクレイピングでは一般に id や class 属性を指定してページ内の要素を絞り込んでいきます。
同じ値が設定されたHTML要素があると nth-child(1) のように "n番目" を指定する記法になります(Chromeの場合は)
※これはPythonのリストで n番目の要素を指定されているのと似ています。
※添付の動画1つ目をご覧ください
https://www.youtube.com/watch?v=SFX-bBM2_Fc
nth-child(n) が登場するようなCSSセレクタの指定はクローリングの汎用性を低下させてしまいます。
なるべくnth-child(n)を使わないようにすることで for 文でページ内の似た要素をプログラム処理できるようになります。
お渡ししたデモアプリケーションのrent_estate/spiders/suumo.pyでは
CSSセレクタ div.property で絞り込み(= 1件1件の物件情報のハコ)、それを for 文で順次処理しています。
for row in response.css("div.property"): の箇所です。
またCSSセレクタは階層構造のように要素を辿っていくことができます。
つまり、div.property の要素内でさらに class 指定をして要素を絞り込んでいくことができます
※添付の動画2つ目をご覧ください
https://www.youtube.com/watch?v=Cg-JKjrQ_Mo
またSuumoのサイトの厄介な点は .get() では住所のテキストが取得できないことです。
理由は、途中のHTMLコメントによって要素のテキスト取得方法が変わってしまうためです。
これには .get() ではなく .getall() を使うことで対処できます。
幸い、欲しい住所のテキスト以外は改行やタブなので .strip() でクレンジングすることができます。
結果として、私が住所を取得するコードを書くなら以下のようになります。
※画像参照
async def handle_response(self, response: HtmlResponse):
from property_store.models import SuumoProperty
for row in response.css("div.property"):
# 中略
# 物件の住所を抽出する
address = row.css("div.detailbox-property table td.detailbox-property-col")[4].css("::text").getall()
# HTMLコメントを含んでいるため、クレンジングする
address = "".join(address).strip()
print("###", address)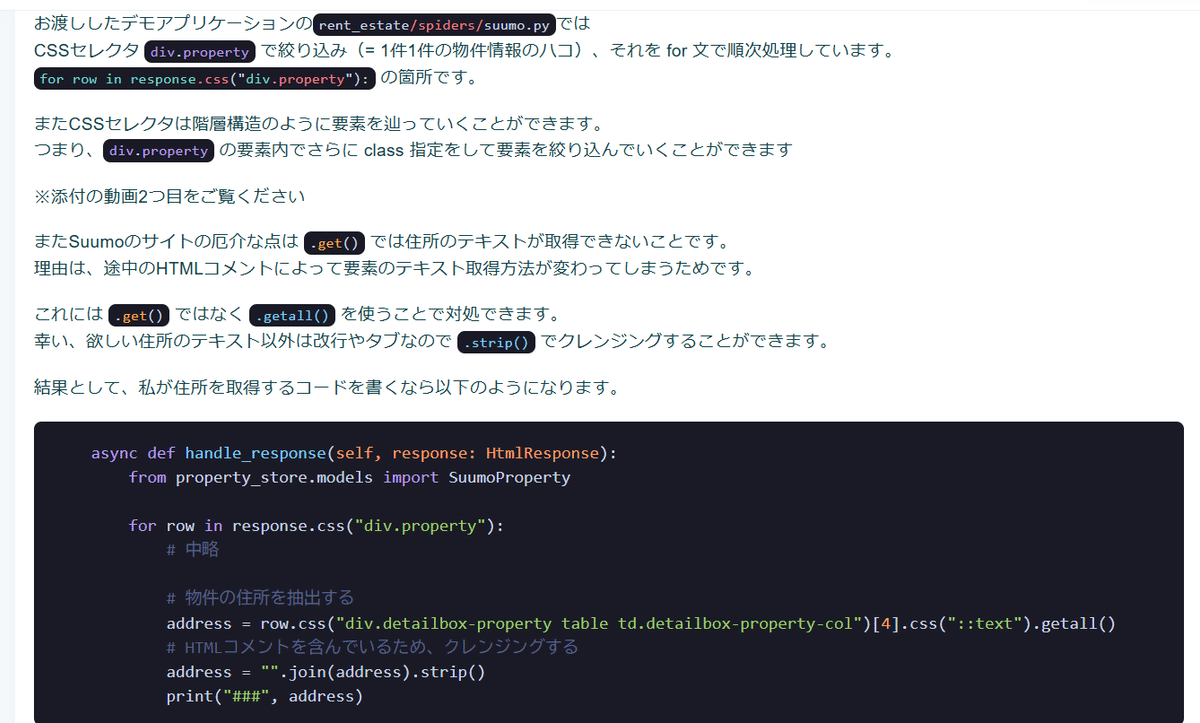
動画1つ目
動画2つ目
画像

以上です♪
何かあなたのお役にたてば幸いです。